Работа с файлами
Содержание:
- Получение информации о пути в Pathlib
- Запись в файл Python
- Other Useful Items
- Форматы файлов в Python 3
- Шаг 2 — Открытие файла
- Как читать файл по частям
- Чтение и запись json-файлов
- Найти все страницы, где есть заданный текст
- Основа
- Чтение¶
- Чтение из файла Python
- Чтение данных из файла с помощью Python
- Ответы на вопросы читателей
- Извлечение текста с помощью PyMuPDF
- Альтернатива для модуля glob
- Шаг 4 — Запись файла
- The write() Method
- OpenPGP Public Keys
- Выявление ошибок
- Настройка строк и столбцов
- Модули для чтения и записи
- Пишем в файлах в Python
- Чтение и запись в бинарном режиме доступа
- Методы работы с файлами
Получение информации о пути в Pathlib
Во время работы с путями зачастую требуется найти родительскую директорию файла/папки или получить символические ссылки. У класса Path есть несколько удобных для этого методов, различные части пути доступны как свойства, что включают следующее:
- : строка, что представляет название жесткого диска. К примеру, вернет ;
- : возвращает , что дает доступ к компонентам пути;
- : компонент пути без директории;
- : последовательность обеспечивает доступ к логическим предкам пути;
- : финальный компонент пути без суффикса;
- : разрешение файла финального компонента;
- : часть пути перед директорией. используется для создания дочерних путей и имитации поведения ;
- : совмещает путь с предоставленными аргументами;
- : возвращает , основываясь на совпадении пути с предоставленным шаблоном поиска.
Например, у нас есть данный путь :
- : — возвращает PosixPath(‘/home/projects/pyscripts/python/sample.md’);
- : — возвращает (‘/’, ‘home’, ‘projects’, ‘pyscripts’, ‘python’);
- : — возвращает ‘sample.md’;
- : — возвращает ‘sample’;
- : — возвращает ‘.md’;
- : — возвращает PosixPath(‘/home/projects/pyscripts/python’);
- : — возвращает PosixPath(‘/home/projects/pyscripts’);
- : возвращает True;
- : возвращает (‘home/projects/pyscripts/python/edited_version.
Запись в файл Python
Чтобы записать данные в файл в Python, нужно открыть его в режиме ‘w’, ‘a’ или ‘x’. Но будьте осторожны с режимом ‘w’. Он перезаписывает файл, если то уже существует. Все данные в этом случае стираются.
Запись строки или последовательности байтов (для бинарных файлов) осуществляется методом write(). Он возвращает количество символов, записанных в файл.
with open("test.txt",'w',encoding = 'utf-8') as f:
f.write("my first filen")
f.write("This filenn")
f.write("contains three linesn")
Эта программа создаст новый файл ‘test.txt’. Если он существует, данные файла будут перезаписаны. При этом нужно добавлять символы новой строки самостоятельно, чтобы разделять строки.
Other Useful Items
- Looking for 3rd party Python modules? The
Package Index has many of them. - You can view the standard documentation
online, or you can download it
in HTML, PostScript, PDF and other formats. See the main
Documentation page. - Information on tools for unpacking archive files
provided on python.org is available. -
Tip: even if you download a ready-made binary for your
platform, it makes sense to also download the source.
This lets you browse the standard library (the subdirectory Lib)
and the standard collections of demos (Demo) and tools
(Tools) that come with it. There’s a lot you can learn from the
source! - There is also a collection of Emacs packages
that the Emacsing Pythoneer might find useful. This includes major
modes for editing Python, C, C++, Java, etc., Python debugger
interfaces and more. Most packages are compatible with Emacs and
XEmacs.
Форматы файлов в Python 3
Python очень гибкий и может относительно легко обрабатывать множество различных форматов файлов. Вот основные форматы:
| Формат | Описание |
| txt | Обычный текстовый файл, который хранит данные в виде символов (или строк) и исключает структурированные метаданные. |
| CSV | Файл, который хранит данные в виде таблицы; для структурирования хранимых данных используются запятые (или другие разделители). |
| HTML | Файл Hypertext Markup Language хранит структурированные данные; такие файлы используются большинством сайтов. |
| JSON | Простой файл JavaScript Object Notation, один из наиболее часто используемых форматов для хранения и передачи данных. |
Данное руководство рассматривает только формат txt.
Шаг 2 — Открытие файла
Прежде чем написать программу, нужно создать файл для кода Python. С помощью текстового редактора создадим файл files.py. Чтобы упростить задачу, сохраните его в том же каталоге, что и файл days.txt:
/users/sammy/.
Чтобы открыть файл, сначала нужно каким-то образом связать его с переменной в Python. Этот процесс называется открытием файла. Сначала мы укажем Python, где находится файл.
Чтобы Python мог открыть файл, ему требуется путь к нему: days.txt -/users/sammy/days.txt. Затем создаем строковую переменную для хранения этой информации. В нашем скрипте files.py мы создадим переменную path и установим для нее значение days.txt.
files.py
path = '/users/sammy/days.txt'
Затем используем функцию Python open(), чтобы открыть файл days.txt. В качестве первого аргумента она принимает путь к файлу.
Эта функция также позволяет использовать многие другие параметры. Но наиболее важным является параметр, определяющий режим открытия файла. Он зависит от того, что вы хотите сделать с файлом.
Вот некоторые из существующих режимов:
- ‘r’: использовать для чтения;
- ‘w’: использовать для записи;
- ‘x’: использование для создания и записи в новый файл;
- ‘a’: использование для добавления к файлу;
- ‘r +’: использовать для чтения и записи в тот же файл.
В текущем примере нужно только считать данные из файла, поэтому будем использовать режим «r». Применим функцию open(), чтобы открыть файл days.txt и назначить его переменной days_file.
files.py
days_file = open(path,'r')
После открытия файла мы сможем прочитать его, что сделаем на следующем шаге.
Как читать файл по частям
Самый простой способ для выполнения этой задачи – использовать цикл. Сначала мы научимся читать файл строку за строкой, после этого мы будем читать по килобайту за раз. В нашем первом примере мы применим цикл:
Python
handle = open(«test.txt», «r»)
for line in handle:
print(line)
handle.close()
|
1 2 3 4 5 6 |
handle=open(«test.txt»,»r») forline inhandle print(line) handle.close() |
Таким образом мы открываем файл в дескрипторе в режиме «только чтение», после чего используем цикл для его повторения
Стоит обратить внимание на то, что цикл можно применять к любым объектам Python (строки, списки, запятые, ключи в словаре, и другие). Весьма просто, не так ли? Попробуем прочесть файл по частям:
Python
handle = open(«test.txt», «r»)
while True:
data = handle.read(1024)
print(data)
if not data:
break
|
1 2 3 4 5 6 7 8 |
handle=open(«test.txt»,»r») whileTrue data=handle.read(1024) print(data) ifnotdata break |
В данном примере мы использовали Python в цикле, пока читали файл по килобайту за раз. Как известно, килобайт содержит в себе 1024 байта или символов. Теперь давайте представим, что мы хотим прочесть двоичный файл, такой как PDF.
Чтение и запись json-файлов
Для работы с json-объектами предусмотрен встроенный модуль json. Его нужно импортировать для начала.
Практически все объекты Питона можно безболезненно преобразовывать в json-сущности.
В библиотеке json имеется 4 основные функции (таблица 2).
| Функция | Характеристика |
| dumps() | Преобразовывает объекты Питона в json |
| dump() | Записывает преобразованные в json-формат данные в файл |
| loads() | Преобразовывает json-данные в словарь |
| load() | Считывает содержимое json-файла и делает из них словарь |
Таблица 2 – Ключевые функции модуля json
Так как мы рассматриваем тему создания и чтения файлов, то будем использовать соответствующие инструменты.
Создадим на ПК документ «my.json» с таким содержимым:
Теперь считаем их и представим в виде словаря Python.
Пример кода:
Результат выполнения:
Как видно, десериализация json-данных осуществляется следующим образом:
- Двойные кавычки преобразованы в одинарные;
- Булево значение false превратилось в False;
- Объект null соответствует значению None в Питоне.
А теперь расширим информацию в документе «my.json», добавив еще одного студента.
Пример кода:
Открываем файл в режиме чтения и возможности записи («r+»). Считываем имеющееся в нем содержимое и преобразуем его в словарь. Добавляем новую запись в словарь с ключом «student2». Полностью переписываем содержимое документа с учетом новой информации: делаем отступы (indent=4) для удобства чтения, а также отключаем режим «только ASCII», чтобы появилась возможность вставлять кириллицу.
Найти все страницы, где есть заданный текст
Этот скрипт довольно практичен и работает аналогично . Используя PyMuPDF, скрипт возвращает все номера страниц, которые содержат заданную строку поиска. Страницы загружаются одна за другой и с помощью метода обнаруживаются все вхождения строки поиска. В случае совпадения соответствующее сообщение печатается на :
import fitz
filename = "source/Computer-Vision-Resources.pdf"
search_term = "COMPUTER VISION"
pdf_document = fitz.open(filename)
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s найдено на странице %i" % (search_term, current_page+1))
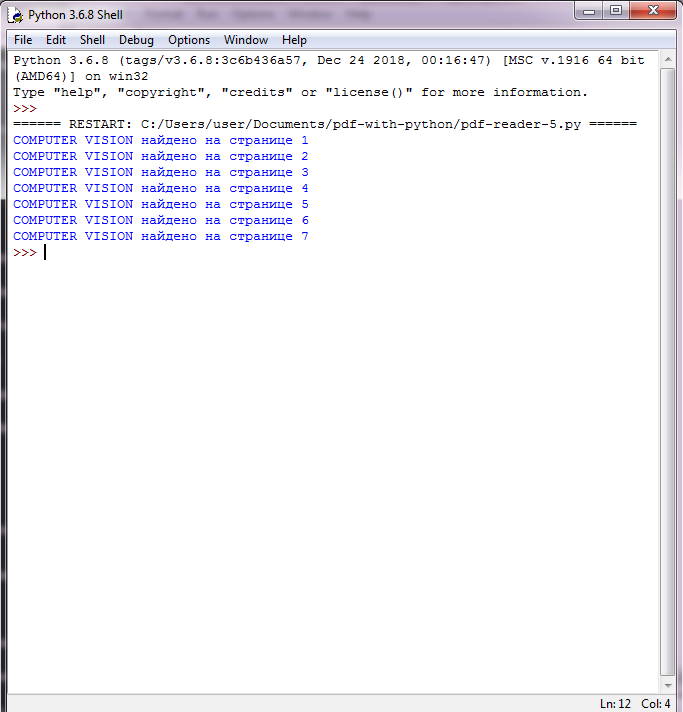 Результаты поиска COMPUTER VISION
Результаты поиска COMPUTER VISION
Методы, показанные здесь, довольно мощные. Сравнительно небольшое количество строк кода позволяет легко получить результат. Другие варианты применения рассматриваются во второй части, посвященной добавлению водяного знака и картинок в PDF.
Продолжение цикла статей-конспектов на сайте
Источники вдохновения:
Основа
Python может с относительной легкостью обрабатывать различные форматы файлов:
| Тип файла | Описание |
| Txt | Обычный текстовый файл хранит данные, которые представляют собой только символы (или строки) и не включает в себя структурированные метаданные. |
| CSV | Файл со значениями,для разделения которых используются запятые (или другие разделители). Что позволяет сохранять данные в формате таблицы. |
| HTML | HTML-файл хранит структурированные данные и используется большинством сайтов |
| JSON | JavaScript Object Notation — простой и эффективный формат, что делает его одним из часто используемых для хранения и передачи данных. |
В этой статье основное внимание будет уделено формату txt
Чтение¶
Файл sw_templates.json:
{
"access"
"switchport mode access",
"switchport access vlan",
"switchport nonegotiate",
"spanning-tree portfast",
"spanning-tree bpduguard enable"
],
"trunk"
"switchport trunk encapsulation dot1q",
"switchport mode trunk",
"switchport trunk native vlan 999",
"switchport trunk allowed vlan"
}
Для чтения в модуле json есть два метода:
- — метод считывает файл в формате JSON и возвращает объекты Python
- — метод считывает строку в формате JSON и возвращает объекты Python
Чтение файла в формате JSON в объект Python (файл json_read_load.py):
import json
with open('sw_templates.json') as f
templates = json.load(f)
print(templates)
for section, commands in templates.items():
print(section)
print('\n'.join(commands))
Вывод будет таким:
$ python json_read_load.py
{'access': , 'trunk': }
access
switchport mode access
switchport access vlan
switchport nonegotiate
spanning-tree portfast
spanning-tree bpduguard enable
trunk
switchport trunk encapsulation dot1q
switchport mode trunk
switchport trunk native vlan 999
switchport trunk allowed vlan
Чтение из файла Python
Чтобы осуществить чтение из файла Python, нужно открыть его в режиме чтения. Для этого можно использовать метод read(size), чтобы прочитать из файла данные в количестве, указанном в параметре size. Если параметр size не указан, метод читает и возвращает данные до конца файла.
>>> f = open("test.txt",'r',encoding = 'utf-8')
>>> f.read(4) # чтение первых 4 символов
'This'
>>> f.read(4) # чтение следующих 4 символов
' is '
>>> f.read() # чтение остальных данных до конца файла
'my first filenThis filencontains three linesn'
>>> f.read() # дальнейшие попытки чтения возвращают пустую строку
''
Метод read() возвращает новые строки как ‘n’. Когда будет достигнут конец файла, при дальнейших попытках чтения мы получим пустые строки.
Чтобы изменить позицию курсора в текущем файле, используется метод seek(). Метод tell() возвращает текущую позицию курсора (в виде количества байтов).
>>> f.tell() # получаем текущую позицию курсора в файле 56 >>> f.seek(0) # возвращаем курсор в начальную позицию 0 >>> print(f.read()) # читаем весь файл This is my first file This file contains three lines
Мы можем прочитать файл построчно в цикле for.
>>> for line in f: ... print(line, end = '') ... This is my first file This file contains three lines
Извлекаемые из файла строки включают в себя символ новой строки ‘n’. Чтобы избежать вывода, используем пустой параметр end метода print(),.
Также можно использовать метод readline(), чтобы извлекать отдельные строки. Он читает файл до символа новой строки.
>>> f.readline() 'This is my first filen' >>> f.readline() 'This filen' >>> f.readline() 'contains three linesn' >>> f.readline() ''
Метод readlines() возвращает список оставшихся строк. Все эти методы чтения возвращают пустую строку, когда достигается конец файла.
>>> f.readlines()
Чтение данных из файла с помощью Python
Допустим, вы (или ваш пользователь посредством вашего приложения) поместили данные в файл, и ваш код должен их получить. Тогда перед вами стоит цель – прочитать файл. Логика чтения такая же, как логика записи:
- Открыть файл
- Прочесть данные
- Закрыть файл
Опять же, этот логический поток отражает то, что вы и так делаете постоянно, просто используя компьютер (или читая книгу, если на то пошло). Чтобы прочитать документ, вы открываете его, читаете и закрываете. С компьютерной точки зрения «открытие» файла означает загрузку его в память.
На практике текстовый файл содержит более одной строки. Например, вашему коду может потребоваться прочитать файл конфигурации, в котором сохранены данные игры или текст следующей песни вашей группы. Так же, как вы не прочитываете всю книгу прямо в момент открытия, ваш код не должен распарсить весь файл целиком при загрузке в память. Вероятно, вам потребуется перебрать содержимое файла.
f = open('example.tmp', 'r')
for line in f:
print(line)
f.close()
В первой строке данного примера мы открываем файл в режиме чтения. Файл обозначаем переменной , но, как и при открытии файлов для записи, имя переменной может быть произвольным. В имени нет ничего особенного – это просто кратчайший из возможных способов представить слово file, поэтому программисты Python часто используют его.
Во второй строке мы резервируем (еще одно произвольное имя переменной), для представления каждой строки . Это сообщает Python, что нужно выполнить итерацию по строкам нашего файла и вывести каждую из них на экран.
Чтение файла с использованием конструкции with
Как и при записи данных, существует более короткий метод чтения из файлов с использованием конструкции . Поскольку здесь не требуется вызов функции , это более удобно для быстрого взаимодействия.
with open('example.txt', 'r') as f:
for line in f:
print(line)
Ответы на вопросы читателей
Сколько времени потребуется на изучение Питона? При постоянной практике и достаточном ежедневном внимании к языку Python основам синтаксиса и базовым операциям можно научиться за 1-2 месяца. Уверенное владение базовыми библиотеками, популярными сторонними модулями, объектно-ориентированном подходе может потребовать от 3 до 6 месяцев. Нужно осознавать и то, что для каждого обучаемого сроки индивидуальны.
Как работать с текстовыми файлами в Питоне? Взаимодействие с текстовыми файлами связано с функциями open(), close(), read(), readlines(), контекстным менеджером with и рядом других. Эти инструменты позволяют как читать документы, так и осуществлять в них запись.
Как работать с таблицами в языке Python? Универсальный формат табличной информации – csv (Comma Separated Values, разделенные запятой данные). Его хорошо понимают разные сайты, среды разработки, операционные системы. Чтобы взаимодействовать с excel-файлами требуется установить модуль openpyxl. Для работы с Гугл-таблицами нужно получить доступ к программному интерфейсу в качестве разработчика.
Что такое json-формат данных? Информация на Интернет-ресурсах зачастую представлена в виде json-данных. Она очень напоминает словари (dictionaries) в Питоне. Именно поэтому работать с этим форматом очень удобно. Он используется для передачи и получения информации между API сайтов и программ.
Какой модуль используется для взаимодействия с файлами операционной системы? Встроенная библиотека os позволяет работать с каталогами и файлами операционной системы. Возможности не ограничены конкретной «операционкой» и в большинстве случаев универсальны. Набор инструментария следующий: представление списка документов конкретной папки, создание папок, удаление каталогов и документов, переименование файлов и др.
Как представить текстовый файл в виде строки? После создания файлового объекта его можно прочитать полностью и вывести на печать. Пример кода: — with open(‘myfile.txt’, ‘r’, encoding=’utf-8′) as doc: print(doc.read()) — Файл «myfile.txt» открыт в режиме чтения и будет выведен в консоль со всем своим содержимым.
Как создать pdf-файл в Питоне? В зависимости от исходных данных pdf-документы могут создаваться при помощи разных инструментов: Pillow (когда входная информация в основной своей массе графическая), PyPDF2 (объединение файлов, кодирование-декодирование), fpdf (преобразование текста в pdf-формат) и пр.
Как обрабатывать изображения при помощи языка Python? Один из самых часто применяемых инструментов – библиотека Pillow. Позволяет решать задачи: извлекать сведения о картинке; менять размеры, обрезать, поворачивать; накладывать фильтры на рисунки (размытие, повышение контраста и др.); добавлять текстовые надписи; создавать изображения.
Извлечение текста с помощью PyMuPDF
Перейдём к PyMuPDF.
Отображение информации о документе, печать количества страниц и извлечение текста из документа PDF выполняется аналогично PyPDF2 (см. скрипт ниже). Импортируемый модуль имеет имя , что соответствует имени PyMuPDF в ранних версиях.
import fitz
pdf_document = "./source/Computer-Vision-Resources.pdf"
doc = fitz.open(pdf_document)
print("Исходный документ: ", doc)
print("\nКоличество страниц: %i\n\n------------------\n\n" % doc.pageCount)
print(doc.metadata)
for current_page in range(len(doc)):
page = doc.loadPage(current_page)
page_text = page.getText("text")
print("Стр. ", current_page+1, "\n\nСодержание;\n")
print(page_text)
Извлечение текста с помощью PyMuPDF
Приятной особенностью PyMuPDF является то, что он сохраняет исходную структуру документа без изменений — целые абзацы с разрывами строк сохраняются такими же, как в PDF‑документе.
Альтернатива для модуля glob
Помимо модулей , в Python также доступен модуль , что предоставляет путь связанных утилит. Функция модуля используется для нахождения файлов, соответствующих шаблону.
Python
from glob import glob
top_xlsx_files = glob(‘*.xlsx’) # Все файлы с расширением .xlsx
all_xlsx_files = glob(‘**/*.xlsx’, recursive=True)
|
1 2 3 4 |
fromglobimportglob top_xlsx_files=glob(‘*.xlsx’)# Все файлы с расширением .xlsx all_xlsx_files=glob(‘**/*.xlsx’,recursive=True) |
Pathlib предоставляет свою реализацию :
Python
from pathlib import Path
top_xlsx_files = Path.cwd().glob(‘*.xlsx’)
all_xlsx_files = Path.cwd().rglob(‘*.xlsx’)
|
1 2 3 4 |
frompathlib importPath top_xlsx_files=Path.cwd().glob(‘*.xlsx’) all_xlsx_files=Path.cwd().rglob(‘*.xlsx’) |
Функциональность glob доступна с объектами . Следовательно, модуль Pathlib упрощают сложные задачи.
Шаг 4 — Запись файла
На этом этапе мы запишем новый файл, который включает в себя название «Days of the Week», и дни недели. Сначала создадим переменную title.
files.py
title = 'Days of the Weekn'
Также нужно сохранить дни недели в строковой переменной days. Открываем файл в режиме чтения, считываем файл и сохраняем вывод в новую переменную days.
files.py
path = '/users/sammy/days.txt' days_file = open(path,'r') days = days_file.read()
Теперь, когда у нас есть переменные для названия и дней недели, запишем их в новый файл. Сначала нужно указать расположение файла. Мы будем использовать каталог /users/sammy/. Также нужно указать новый файл, который мы хотим создать. Фактический путь будет /users/sammy/new_days.txt. Мы записываем его в переменную new_path. Затем открываем новый файл в режиме записи, используя функцию open() с режимом w.
files.py
new_path = '/users/sammy/new_days.txt' new_days = open(new_path,'w')
Если файл new_days.txt уже существовал до открытия, его содержимое будет удалено, поэтому будьте осторожны при использовании режима «w».
Когда новый файл будет открыт, поместим в него данные, используя <file>.write(). Операция write принимает один параметр, который должен быть строкой, и записывает эту строку в файл.
Если хотите записать новую строку в файл, нужно указать символ новой строки. Мы записываем в файл заголовок, за которым следуют дни недели.
iles.py
new_days.write(title) print(title) new_days.write(days) print(days)
Всякий раз, когда мы заканчиваем работу с файлом, нужно его закрыть. Мы покажем это в заключительном шаге.
The write() Method
The write() method writes any string to an open file. It is important to note that Python strings can have binary data and not just text.
The write() method does not add a newline character (‘\n’) to the end of the string −
fileObject.write(string)
Here, passed parameter is the content to be written into the opened file.
Example
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
fo.write( "Python is a great language.\nYeah its great!!\n")
# Close opend file
fo.close()
The above method would create foo.txt file and would write given content in that file and finally it would close that file. If you would open this file, it would have following content.
Python is a great language. Yeah its great!!
OpenPGP Public Keys
Source and binary executables are signed by the release manager or binary builder using their
OpenPGP key. Release files for currently supported releases are signed by the following:
- Pablo Galindo Salgado (3.10.x and 3.11.x source files and tags) (key id: 64E628F8D684696D)
- Steve Dower (Windows binaries) (key id: FC62 4643 4870 34E5)
- Łukasz Langa (3.8.x and 3.9.x source files and tags) (key id: B269 95E3 1025 0568)
- Ned Deily (macOS binaries, 3.7.x / 3.6.x source files and tags) (key ids: 2D34 7EA6 AA65 421D, FB99 2128 6F5E 1540, and Apple Developer ID DJ3H93M7VJ)
- Larry Hastings (3.5.x source files and tags) (key id: 3A5C A953 F73C 700D)
- Benjamin Peterson (2.7.z source files and tags) (key id: 04C3 67C2 18AD D4FF and A4135B38)
Release files for older releases which have now reached end-of-life may have been signed by one of the following:
- Anthony Baxter (key id: 0EDD C5F2 6A45 C816)
- Georg Brandl (key id: 0A5B 1018 3658 0288)
- Martin v. Löwis (key id: 6AF0 53F0 7D9D C8D2)
- Ronald Oussoren (key id: C9BE 28DE E6DF 025C)
- Barry Warsaw (key ids: 126E B563 A74B 06BF, D986 6941 EA5B BD71, and ED9D77D5)
You can import a person’s public keys from a public keyserver network server
you trust by running a command like:
or, in many cases, public keys can also be found
at keybase.io.
On the version-specific download pages, you should see a link to both the
downloadable file and a detached signature file. To verify the authenticity
of the download, grab both files and then run this command:
Note that you must use the name of the signature file, and you should use the
one that’s appropriate to the download you’re verifying.
(These instructions are geared to
GnuPG and Unix command-line users.)
Выявление ошибок
Иногда, в ходе работы, ошибки случаются. Файл может быть закрыт, потому что какой-то другой процесс пользуется им в данный момент или из-за наличия той или иной ошибки разрешения. Когда это происходит, может появиться IOError. В данном разделе мы попробуем выявить эти ошибки обычным способом, и с применением оператора with. Подсказка: данная идея применима к обоим способам.
Python
try:
file_handler = open(«test.txt»)
for line in file_handler:
print(line)
except IOError:
print(«An IOError has occurred!»)
finally:
file_handler.close()
|
1 2 3 4 5 6 7 8 |
try file_handler=open(«test.txt») forline infile_handler print(line) exceptIOError print(«An IOError has occurred!») finally file_handler.close() |
В описанном выше примере, мы помещаем обычный код в конструкции try/except. Если ошибка возникнет, следует открыть сообщение на экране
Обратите внимание на то, что следует удостовериться в том, что файл закрыт при помощи оператора finally. Теперь мы готовы взглянуть на то, как мы можем сделать то же самое, пользуясь следующим методом:
Python
try:
with open(«test.txt») as file_handler:
for line in file_handler:
print(line)
except IOError:
print(«An IOError has occurred!»)
|
1 2 3 4 5 6 |
try withopen(«test.txt»)asfile_handler forline infile_handler print(line) exceptIOError print(«An IOError has occurred!») |
Как вы можете догадаться, мы только что переместили блок with туда же, где и в предыдущем примере. Разница в том, что оператор finally не требуется, так как контекстный диспетчер выполняет его функцию для нас.
Настройка строк и столбцов
С помощью модуля OpenPyXL можно задавать высоту строк и ширину столбцов таблицы, закреплять их на месте (чтобы они всегда были видны на экране), полностью скрывать из виду, объединять ячейки.
Настройка высоты строк и ширины столбцов
Объекты имеют атрибуты и , которые управляют высотой строк и шириной столбцов.
sheet'A1' = 'Высокая строка' sheet'B2' = 'Широкий столбец' sheet.row_dimensions1.height = 70 sheet.column_dimensions'B'.width = 30
Атрибуты s и представляют собой значения, подобные словарю. Атрибут содержит объекты , а атрибут содержит объекты . Доступ к объектам в осуществляется с использованием номера строки, а доступ к объектам в — с использованием буквы столбца.
Для указания высоты строки разрешено использовать целые или вещественные числа в диапазоне от 0 до 409. Для указания ширины столбца можно использовать целые или вещественные числа в диапазоне от 0 до 255. Столбцы с нулевой шириной и строки с нулевой высотой невидимы для пользователя.
Объединение ячеек
Ячейки, занимающие прямоугольную область, могут быть объединены в одну ячейку с помощью метода рабочего листа:
sheet.merge_cells('A1:D3')
sheet'A1' = 'Объединены двенадцать ячеек'
sheet.merge_cells('C5:E5')
sheet'C5' = 'Объединены три ячейки'
Чтобы отменить слияние ячеек, надо вызвать метод :
sheet.unmerge_cells('A1:D3')
sheet.unmerge_cells('C5:E5')
Закрепление областей
Если размер таблицы настолько велик, что ее нельзя увидеть целиком, можно заблокировать несколько верхних строк или крайних слева столбцов в их позициях на экране. В этом случае пользователь всегда будет видеть заблокированные заголовки столбцов или строк, даже если он прокручивает таблицу на экране.
У объекта имеется атрибут , значением которого может служить объект или строка с координатами ячеек. Все строки и столбцы, расположенные выше и левее, будут заблокированы.
| Значение атрибута freeze_panes | Заблокированные строки и столбцы |
|---|---|
| Строка 1 | |
| Столбец A | |
| Столбцы A и B | |
| Строка 1 и столбцы A и B | |
| Закрепленные области отсутствуют |
Модули для чтения и записи
Модуль CSV имеет несколько функций и классов, доступных для чтения и записи CSV, и они включают в себя:
- функция csv.reader
- функция csv.writer
- класс csv.Dictwriter
- класс csv.DictReader
csv.reader
Модуль csv.reader принимает следующие параметры:
- : обычно это объект, который поддерживает протокол итератора и обычно возвращает строку каждый раз, когда вызывается его метод .
- : необязательный параметр, используемый для определения набора параметров, специфичных для определенного диалекта CSV.
- : необязательный параметр, который можно использовать для переопределения существующих параметров форматирования.
Вот пример того, как использовать модуль csv.reader.
модуль csv.writer
Этот модуль похож на модуль csv.reader и используется для записи данных в CSV. Требуется три параметра:
- : это может быть любой объект с методом .
- : необязательный параметр, используемый для определения набора параметров, специфичных для конкретного CSV.
- : необязательный параметр, который можно использовать для переопределения существующих параметров форматирования.
Пишем в файлах в Python
Как вы могли догадаться, следуя логике написанного выше, режимы написания файлов в Python это “w” и “wb” для write-mode и write-binary-mode соответственно
Теперь давайте взглянем на простой пример того, как они применяются.ВНИМАНИЕ: использование режимов “w” или “wb” в уже существующем файле изменит его без предупреждения. Вы можете посмотреть, существует ли файл, открыв его при помощи модуля ОС Python
Python
handle = open(«output.txt», «w»)
handle.write(«This is a test!»)
handle.close()
|
1 2 3 |
handle=open(«output.txt»,»w») handle.write(«This is a test!») handle.close() |
Вот так вот просто. Все, что мы здесь сделали – это изменили режим файла на “w” и указали метод написания в файловом дескрипторе, чтобы написать какой-либо текст в теле файла. Файловый дескриптор также имеет метод writelines (написание строк), который будет принимать список строк, который дескриптор, в свою очередь, будет записывать по порядку на диск.
Чтение и запись в бинарном режиме доступа
Что такое
бинарный режим доступа? Это когда данные из файла считываются один в один без
какой-либо обработки. Обычно это используется для сохранения и считывания
объектов. Давайте предположим, что нужно сохранить в файл вот такой список:
books =
("Евгений Онегин", "Пушкин А.С.", 200),
("Муму", "Тургенев И.С.", 250),
("Мастер и Маргарита", "Булгаков М.А.", 500),
("Мертвые души", "Гоголь Н.В.", 190)
Откроем файл на
запись в бинарном режиме:
file = open("out.bin", "wb")
Далее, для работы
с бинарными данными подключим специальный встроенный модуль pickle:
import pickle
И вызовем него
метод dump:
pickle.dump(books, file)
Все, мы
сохранили этот объект в файл. Теперь прочитаем эти данные. Откроем файл на
чтение в бинарном режиме:
file = open("out.bin", "rb")
и далее вызовем
метод load модуля pickle:
bs = pickle.load(file)
Все, теперь
переменная bs ссылается на
эквивалентный список:
print( bs )
Аналогичным
образом можно записывать и считывать сразу несколько объектов. Например, так:
import pickle
book1 = "Евгений Онегин", "Пушкин А.С.", 200
book2 = "Муму", "Тургенев И.С.", 250
book3 = "Мастер и Маргарита", "Булгаков М.А.", 500
book4 = "Мертвые души", "Гоголь Н.В.", 190
try:
file = open("out.bin", "wb")
try:
pickle.dump(book1, file)
pickle.dump(book2, file)
pickle.dump(book3, file)
pickle.dump(book4, file)
finally:
file.close()
except FileNotFoundError:
print("Невозможно открыть файл")
А, затем,
считывание в том же порядке:
file = open("out.bin", "rb")
b1 = pickle.load(file)
b2 = pickle.load(file)
b3 = pickle.load(file)
b4 = pickle.load(file)
print( b1, b2, b3, b4, sep="\n" )
Вот так в Python выполняется
запись и считывание данных из файла.
Методы работы с файлами
| Методы | Описание |
| close() | Закрывает открытый файл. |
| detach() | |
| fileno() | Возвращает целое число (файловый дескриптор) файла. |
| flush() | Сбрасывает буфер записи потока файлов. |
| isatty() | ВОЗВРАТ True если файловый поток является интерактивным. |
| read(n) | Читает самое большее n символы из файла. Читает до конца файла, если он отрицательный или None. |
| readable() | ВОЗВРАТ True если файловый поток можно прочитать. |
| readline(n=-1) | Считывает и возвращает одну строку из файла |
| readlines(n=-1) | Считывает и возвращает список строк из файла |
| seek(offset,from=SEEK_SET) | |
| seekable() | ВОЗВРАТ True если файловый поток поддерживает произвольный доступ. |
| tell() | Возвращает текущее местоположение файла. |
| truncate(size=None) | Изменяет размер потока файлов следующим образом size байты. Если size не указан, изменяет размер до текущего местоположения. |
| writable() | ВозвращаетTrue, если файловый поток может быть записан. |
| write(s) | Записывает строку sв файл и возвращает количество записанных символов. |
| writelines(lines) | Записывает список lines в файл. |







