Что такое storage-файл?
Содержание:
Каким должен быть склад
Сегодня на российском рынке в основном представлены игроки, которые предлагают услугу self-storage в ее классическом виде. Это значит, что клиент может выбрать локацию склада исходя из места проживания и работы, а также бокс необходимой площади. Он имеет доступ к боксу в определенные часы — согласно правилам компании — и самостоятельно привозит туда свои вещи. Однако потенциальные клиенты могут столкнуться с рядом неудобств вроде необходимости самим упаковывать свои вещи или нанимать сторонних грузчиков для перевозки крупногабаритных вещей. Все это может повлиять на решение людей воспользоваться сервисом индивидуального хранения. Чтобы клиенты выбирали вас и возвращались к вам, необходимо предложить такой сервис, который будет выгодно отличать вас от остальных игроков на рынке. Так, разрабатывая бизнес-модель «Чердака», мы проанализировали существующие предложения, пересмотрели классический подход к self-storage и решили предоставить клиентам максимально удобный сервис с прозрачным ценообразованием.
Наши штатные муверы приезжают по нужному адресу, сами упаковывают вещи и отвозят на склад, а когда возникает необходимость — возвращают их все или только часть. Данный подход позволяет сэкономить нашим клиентам время и силы, которые они потратили бы на сборы и доставку своих вещей на склад. На сегодняшний день в штате в Москве работают более 100 муверов, а также более 30 сотрудников офиса. Также у нас есть колл-центр — наши специалисты оказывают техническую поддержку существующим клиентам и консультируют по всем вопросам работы нашего сервиса.
# Examples
The following sections demonstrate how to use to address some common use cases.
Synchronous response to storage updates
If you’re interested in tracking changes made to a data object, you can add a listener to its event. Whenever anything changes in storage, that event fires. Here’s sample code to listen for saved changes:
We can take this idea even further. In this example we have an options page that allows the user to toggle a «debug mode» in the extension (implementation not shown here). Changes to this setting are immediately saved to sync storage by the options page and the background script uses to apply the setting as soon as possible.
Asynchronous preload from storage
Since service workers are not always running, Manifest V3 extensions sometimes need to asynchronously load data from storage before they execute their event handlers. To do this, the below snippet uses an async event handler that waits for the global to be populated before executing its logic.
Types
StorageArea
Properties
-
clear
functionPromise
Removes all items from storage.
The clear function looks like this:
-
get
functionPromise
Gets one or more items from storage.
The get function looks like this:
-
keys
string | string[] | object optionalA single key to get, list of keys to get, or a dictionary specifying default values (see description of the object). An empty list or object will return an empty result object. Pass in to get the entire contents of storage.
-
callback
functionCallback with storage items, or on failure (in which case will be set).
The parameter should be a function that looks like this:
-
-
getBytesInUse
functionPromise
Gets the amount of space (in bytes) being used by one or more items.
The getBytesInUse function looks like this:
-
keys
string | string[] optionalA single key or list of keys to get the total usage for. An empty list will return 0. Pass in to get the total usage of all of storage.
-
callback
functionCallback with the amount of space being used by storage, or on failure (in which case will be set).
The parameter should be a function that looks like this:
-
-
onChanged
<function>Chrome 73+
Fired when one or more items change.
-
listener
functionThe listener parameter should be a function that looks like this:
-
-
remove
functionPromise
Removes one or more items from storage.
The remove function looks like this:
-
keys
string | string[]A single key or a list of keys for items to remove.
-
callback
function optionalCallback on success, or on failure (in which case will be set).
If you specify the parameter, it should be a function that looks like this:
-
-
set
functionPromise
Sets multiple items.
The set function looks like this:
-
items
objectAn object which gives each key/value pair to update storage with. Any other key/value pairs in storage will not be affected.
Primitive values such as numbers will serialize as expected. Values with a and will typically serialize to , with the exception of (serializes as expected), , and (serialize using their representation).
-
callback
function optionalCallback on success, or on failure (in which case will be set).
If you specify the parameter, it should be a function that looks like this:
-
Properties
-
newValue
any optionalThe new value of the item, if there is a new value.
-
oldValue
any optionalThe old value of the item, if there was an old value.
SAN
Storage area network, она же сеть хранения данных, является технологией организации системы хранения данных с использованием выделенной сети, позволяя таким образом подключать диски к серверам с использованием специализированного оборудования. Так решается вопрос с утилизацией дискового пространства серверами, а также устраняются точки отказа, неизбежно присутствующие в системах хранения данных на основе DAS. Сеть хранения данных чаще всего использует технологию Fibre Channel, однако явной привязки к технологии передачи данных — нет. Накопители используются в блочном режиме, для общения с накопителями используются протоколы SCSI и NVMe, инкапсулируемые в кадры FC, либо в стандартные пакеты TCP, например в случае использования SAN на основе iSCSI.
Давайте разберем более детально устройство SAN, для этого логически разделим ее на две важных части, сервера с HBA и дисковые полки, как оконечные устройства, а также коммутаторы (в больших системах — маршрутизаторы) и кабели, как средства построения сети. HBA — специализированный контроллер, размещаемый в сервере, подключаемом к SAN. Через этот контроллер сервер будет «видеть» диски, размещаемые в дисковых полках. Сервера и дисковые полки не обязательно должны размещаться рядом, хотя для достижения высокой производительности и малых задержек это рекомендуется. Сервера и полки подключаются к коммутатору, который организует общую среду передачи данных. Коммутаторы могут также соединяться с собой с помощью межкоммутаторных соединений, совокупность всех коммутаторов и их соединений называется фабрикой. Есть разные варианты реализации фабрики, я не буду тут останавливаться подробно. Для отказоустойчивости рекомендуется подключать минимум две фабрики к каждому HBA в сервере (иногда ставят несколько HBA) и к каждой дисковой полке, чтобы коммутаторы не стали точкой отказа SAN.
Недостатками такой системы являются большая стоимость и сложность, поскольку для обеспечения отказоустойчивости требуется обеспечить несколько путей доступа (multipath) серверов к дисковым полкам, а значит, как минимум, задублировать фабрики. Также в силу физических ограничений (скорость света в общем и емкость передачи данных в информационной матрице коммутаторов в частности) хоть и существует возможность неограниченного подключения устройств между собой, на практике чаще всего есть ограничения по числу соединений (в том числе и между коммутаторами), числу дисковых полок и тому подобное.
How it works
Objects are discrete units of data that are stored in a structurally flat data environment. There are no folders, directories, or complex hierarchies as in a file-based system. Each object is a simple, self-contained repository that includes the data, metadata (descriptive information associated with an object), and a unique identifying ID number (instead of a file name and file path). This information enables an application to locate and access the object. You can aggregate object storage devices into larger storage pools and distribute these storage pools across locations. This allows for unlimited scale, as well as improved data resiliency and disaster recovery.
Object storage removes the complexity and scalability challenges of a hierarchical file system with folders and directories. Objects can be stored locally, but most often reside on cloud servers, with accessibility from anywhere in the world.
Objects (data) in an object-storage system are accessed via Application Programming Interfaces (APIs). The native API for object storage is an HTTP-based RESTful API (also known as a RESTful Web service). These APIs query an object’s metadata to locate the desired object (data) via the Internet from anywhere, on any device. RESTful APIs use HTTP commands like “PUT” or “POST” to upload an object, “GET” to retrieve an object, and “DELETE” to remove it. (HTTP stands for Hypertext Transfer Protocol and is the set of rules for transferring text, graphic images, sound, video, and other multimedia files on the Internet).
You can store any number of static files on an object storage instance to be called by an API. Additional RESTful API standards are emerging that go beyond creating, retrieving, updating, and deleting objects. These allow applications to manage the object storage, its containers, accounts, multi-tenancy, security, billing, and more.
For example, suppose you want to store all the books in a very large library system on a single platform. You will need to store the contents of the books (data), but also the associated information like the author, publication date, publisher, subject, copyrights, and other details (metadata). You could store all of this data and metadata in a relational database, organized in folders under a hierarchy of directories and subdirectories.
But with millions of books, the search and retrieval process will become cumbersome and time-consuming. An object storage system works well here since the data is static or fixed. In this example, the contents of the book will not change. The objects (data, metadata, and ID) are stored as “packages” in a flat structure and easily located and retrieved with a single API call. Further, as the number of books continues to grow, you can aggregate storage devices into larger storage pools, and distribute these storage pools for unlimited scale.
Benefits
There are many reasons to consider an object-storage-based solution to store your data, particularly in this era of the Internet and digital communications that is producing large volumes of web-based, multimedia data at an increasing rate.
Storing/managing unstructured data
Cloud-based object storage is ideal for long-term data retention. Use object storage to replace traditional archives, such as Network Attached Storage (NAS), reducing your IT infrastructure. Easily archive and store mandated, regulatory data that must be retained for extended periods of time. Cost-effectively preserve large amounts of rich media content (images, videos, etc.) that is not frequently accessed.
Scalability
Unlimited scale is perhaps the most significant advantage of object-based data storage. Objects, or discrete units of data (in any quantity), are stored in a structurally flat data environment, within a storage device such as a server. You simply add more devices/servers in parallel to an object storage cluster for additional processing and to support the higher throughputs required by large files such as videos or images.
Reduced complexity
Object storage removes the complexity that comes with a hierarchical file system with folders and directories. There is less potential for performance delay and you will realize efficiencies when retrieving data since there are no folders, directories or complex hierarchies to navigate. This improves performance, particularly when managing very large quantities of data.
Disaster recovery/availability
You can configure object storage systems so that they replicate content. If a disk within a cluster fails, a duplicate disk is available, ensuring that the system continues running with no interruption or performance degradation. Data can be replicated within nodes and clusters and among distributed data centers for additional back-up off-site and even across geographical regions.
Object storage is a more efficient alternative to tape backup solutions, which require tapes that need to be physically loaded into and removed from tape drives and moved off-site for geographic redundancy. You can use object storage to automatically back up on-premises databases to the cloud and/or to cost-effectively replicate data among distributed data centers. Add additional back-up off-site and even across geographical regions to ensure disaster recovery.
For a deeper dive on disaster recovery, check out «Backup and Disaster Recovery: A Complete Guide.»
Customizable metadata
Remember that each object is a self-contained repository that includes metadata or descriptive information associated with it. Objects use this metadata for important functions such as policies for retention, deletion and routing, disaster recovery strategies (data protection), or validating content authenticity. You can also customize the metadata with additional context that can be later extracted and leveraged to perform business insights and analytics around customer service or market trends, for example.
Affordability
Object storage services use pay-as-you-go pricing that incurs no upfront costs or capital investment. You simply pay a monthly subscription fee for a specified amount of storage capacity, data retrieval, bandwidth usage, and API transactions. Pricing is usually tiered-based or volume-based, which means that you will pay less for very large volumes of data.
Additional cost savings come from the use of commodity server hardware since object storage solutions have limited hardware constraints and can be deployed on most properly configured commodity servers. This limits the need to purchase new hardware when deploying an object storage platform on-premises. You can even use hardware from multiple vendors.
Cloud compatibility
Object storage goes hand in hand with cloud or hosted environments that deliver multi-tenant storage as a service. This allows many companies or departments within a company to share the same storage repository, with each having access to a separate portion of the storage space. This shared storage approach inherently optimizes scale and costs. You will reduce your organization’s on-site IT infrastructure by using low-cost cloud storage while keeping your data accessible when needed. Your enterprise, for example, can use a cloud-based object storage solution to collect and store large amounts of unstructured IoT and mobile data for your smart device applications.
What Can Cloud Storage Do for You?
The very best cloud storage solutions play nicely with other apps and services, making the experience of viewing or editing your files feel natural. Especially in business settings, you want your other software and apps to be able to retrieve or access your files, so making sure you use a service that easily authenticates with the other tools you use is a big deal. Box and Dropbox are particularly strong in this regard.
The range of capabilities of cloud-based storage services is incredible. Many of them specialize in a specific area. For example, Dropbox and SugarSync focus on keeping a synced folder accessible everywhere. SpiderOak emphasizes security. Some cloud storage services, such as Apple iCloud, Google Drive and Microsoft OneDrive, are generalists, offering not only folder and file syncing, but also media-playing and device syncing. These products even double as collaboration software, offering real-time document co-editing.
Distinct from but overlapping in some cases with cloud storage are online backup services. Some of these, such as Carbonite, are all about disaster recovery, while IDrive combines that goal with syncing and sharing capabilities.
Most cloud services do offer some level of backup, almost as a consequence of their intended function. It follows logically that any files uploaded to a cloud service are also protected from disk failures, since there are copies of them in the cloud. But true online backup services can back up all of your computer’s files, not just those in a synced folder structure. Whereas syncing is about managing select files, backup tends to be a bulk, just-in-case play. With syncing, you choose the folders, documents, and media that you want ready access to and save them in the cloud for easy access. With backup, you protect everything you think you might regret losing. Easy, immediate access is not guaranteed with online backup, nor is it the point. Peace of mind is.
File storage and IBM Cloud
IBM Cloud File Storage solutions are durable, fast and flexible. You will gain protection against data loss during maintenance or failures with at-rest data encryption, along with volume duplication and snapshots and replication. With IBM data centers located around the world, you are assured of high-level data protection, replication, and disaster recovery.
IBM Cloud offers four, pre-defined Endurance tiers with per-gigabyte (GB) pricing that locks in your costs, ensuring predictable hourly or monthly billing for your short-term or long-term data storage needs. File Storage Endurance tiers support performance up to 10,000 (10K) IOPS/GB and can meet the needs of most workloads, whether you require low-intensity, general purpose, or high-intensity performance.
With IBM File Storage, you’ll be able to increase or decrease your IOPS and expand existing volumes on the fly. And you can further protect your data by subscribing to IBM’s Snapshot feature, which creates read-only images of your file storage volume at particular points, from which you can easily restore your data in case of accidental loss or damage.
Learn more about IBM’s File Storage Endurance tiers and performance options.
Sign up for a free, two-month trial and start building for free on IBM Cloud.
Key capabilities
| Robust operations |
Firebase SDKs for Cloud Storage perform uploads and downloads regardless of network quality. Uploads and downloads are robust, meaning they restart where they stopped, saving your users time and bandwidth. |
| Strong security |
Firebase SDKs for Cloud Storage integrate with Firebase Authentication to provide simple and intuitive authentication for developers. You can use our declarative security model to allow access based on filename, size, content type, and other metadata. |
| High scalability |
Cloud Storage is built for exabyte scale when your app goes viral. Effortlessly grow from prototype to production using the same infrastructure that powers Spotify and Google Photos. |
Object storage and Kubernetes
As more developers compete to deploy and scale applications faster, containerization has emerged as a growing solution.
Containerization is an application packaging approach that is quickly maturing and delivering unprecedented benefits to developers, infrastructure and operations teams. «Containerization: A Complete Guide» will give you a full overview of all things containerization.
Kubernetes, in turn, has become a leading container management solution. Kubernetes eases management tasks such as scaling containerized applications. It also helps you roll out new versions of applications, and provides monitoring, logging and debugging services, among other functions. Kubernetes is an open-source platform and conforms to the Open Container Initiative (OCI) standards for container image formats and runtimes.
What does Kubernetes have to do with object storage? The key term here is scale.
Kubernetes enables the management of containers at scale. It is capable of orchestrating containers across multiple hosts and scaling containerized applications and their resources dynamically (auto-scaling is one of the key features of Kubernetes). Object storage systems handle storage at scale. These systems are capable of storing massive volumes of unstructured data at petabyte-scale and even greater. These two scale-out approaches, used together, create an ideal environment for today’s and tomorrow’s massive and growing data workloads.
Running an object storage system on top of Kubernetes is a natural fit. Use Kubernetes for provisioning and managing distributed containerized applications. Likewise, Kubernetes can be the unified management interface to handle the orchestration of distributed object storage pools, whether these are local or distributed across data centers or even across geographical regions.
To learn all about Kubernetes, see «Kubernetes: A Complete Guide.»
To back up a bit and start from the core concepts, see our video «Container Orchestration Explained.»
Операции
Общественное хранилище в Лос-Анджелесе
Общественное хранилище в Онтарио
Места самостоятельного хранения, как правило, находятся в плотных кластерах в крупных городах, особенно возле автострад и перекрестков. В Public Storage очень мало сотрудников для компании такого размера. Доступ клиентов к каждому месту хранения автоматизирован. В некоторых местах есть пара муж-жена, которые живут на месте и получают зарплату, близкую к минимальной, за наблюдение за учреждением.
Неуплата арендной платы
Содержимое хранилища выставляется на аукцион, если арендная плата не оплачивается в течение шестидесяти дней. Хотя телешоу Storage Wars вызвало повышенный интерес на аукционах, большинство единиц не содержат ничего значительного с экономической точки зрения. Иногда аукцион собственности арендатора может привести к спорам между Public Storage и арендатором. В 2007 году вещи клиента были проданы с аукциона за неуплату, когда он служил в армии США в Ираке. Получив негативную огласку, Public Storage извинилась и выплатила ему 8000 долларов в качестве компенсации за проданные им вещи.
Коридор общественного хранилища с дверцами для хранения вещей
Кража, страхование и ущерб
В 2005 году Public Storage сообщила в публичной документации, что «растет число исков и судебных тяжб против владельцев и управляющих арендуемой недвижимостью, связанных с проникновением влаги, которое может привести к образованию плесени или другому повреждению имущества». В договоре аренды компании говорится, что она не несет ответственности за содержимое хранилища, даже если повреждение вызвано дефектами в нем, а The Wall Street Journal сообщила, что было «на удивление мало средств правовой защиты» от кражи или повреждения имущества на объектах самостоятельного хранения. .
Многие клиенты Public Storage подали жалобы в Better Business Bureau относительно страховых полисов, продаваемых представителями Public Storage, после того, как они столкнулись со взломом их хранилищ, а затем отказали в их страховых требованиях. Журналисты-расследователи новостных телеканалов в Калифорнии, Канзасе и Вашингтоне сообщали о трудностях, с которыми сталкивались потребители при подаче страховых исков за кражи со взломом в Willis и The New Hampshire Insurance Company, которые связаны с Public Storage. Например, претензии были отклонены, потому что блок хранения был неповрежденным; аффилированные страховые компании ссылались на недостаточные доказательства насильственного проникновения, хотя грабители часто заменяют замок устройства, пытаясь скрыть кражу со взломом. Комиссары по страхованию в двух штатах раскритиковали практику страховых компаний, связанных с Public Storage. В продолжающемся коллективном иске утверждается, что Public Storage вводит потребителей в заблуждение, заставляя их думать, что страховые взносы взимаются по себестоимости, тогда как значительная часть этих премий удерживается в качестве прибыли Public Storage. Продажи этих страховых полисов действительно приносят высокую прибыль, но приносят менее пяти процентов от общего дохода компании.
Storage account billing
Azure Storage bills based on your storage account usage. All objects in a storage account are billed together as a group. Storage costs are calculated according to the following factors:
- Region refers to the geographical region in which your account is based.
- Account type refers to the type of storage account you’re using.
- Access tier refers to the data usage pattern you’ve specified for your general-purpose v2 or Blob storage account.
- Capacity refers to how much of your storage account allotment you’re using to store data.
- Redundancy determines how many copies of your data are maintained at one time, and in what locations.
- Transactions refer to all read and write operations to Azure Storage.
- Data egress refers to any data transferred out of an Azure region. When the data in your storage account is accessed by an application that isn’t running in the same region, you’re charged for data egress. For information about using resource groups to group your data and services in the same region to limit egress charges, see .
The Azure Storage pricing page provides detailed pricing information based on account type, storage capacity, replication, and transactions. The Data Transfers pricing details provides detailed pricing information for data egress. You can use the Azure Storage pricing calculator to help estimate your costs.
Azure services cost money. Azure Cost Management helps you set budgets and configure alerts to keep spending under control. Analyze, manage, and optimize your Azure costs with Cost Management. To learn more, see the quickstart on analyzing your costs.
Inputs
You can use the pipeline operator to pass an MSFT_PhysicalDisk object to the PhysicalDisk parameter to get the storage pool associated with the PhysicalDisk object.
You can use the pipeline operator to pass an MSFT_ResiliencySetting object to the ResiliencySetting parameter to get the storage pool associated with the ResiliencySetting object.
You can use the pipeline operator to pass an MSFT_StorageNode object to the StorageNode parameter to get the storage pool associated with the StorageNode object.
You can use the pipeline operator to pass an MSFT_StorageSubsystem object to the StorageSubsystem parameter to get the storage pool associated with the StorageSubsystem object.
You can use the pipeline operator to pass an MSFT_StorageTier object to the StorageTier parameter to get the storage pool associated with the StorageTier object.
You can use the pipeline operator to pass an MSFT_VirtualDisk object to the VirtualDisk parameter to get the storage pool associated with the VirtualDisk object.
How it works
Storage Spaces Direct is the evolution of Storage Spaces, first introduced in Windows Server 2012. It leverages many of the features you know today in Windows Server, such as Failover Clustering, the Cluster Shared Volume (CSV) file system, Server Message Block (SMB) 3, and of course Storage Spaces. It also introduces new technology, most notably the Software Storage Bus.
Here’s an overview of the Storage Spaces Direct stack:
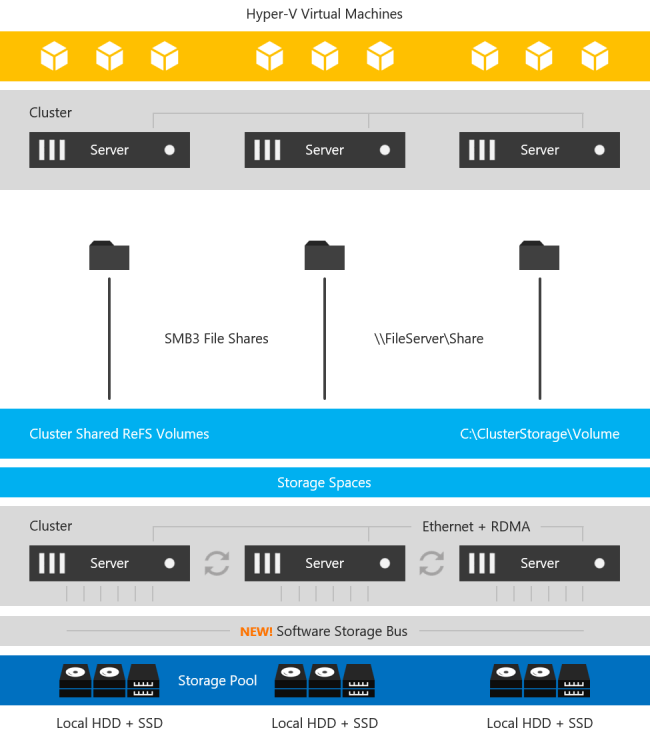
Networking Hardware. Storage Spaces Direct uses SMB3, including SMB Direct and SMB Multichannel, over Ethernet to communicate between servers. We strongly recommend 10+ GbE with remote-direct memory access (RDMA), either iWARP or RoCE.
Storage Hardware. From 2 to 16 servers with local-attached SATA, SAS, or NVMe drives. Each server must have at least 2 solid-state drives, and at least 4 additional drives. The SATA and SAS devices should be behind a host-bus adapter (HBA) and SAS expander. We strongly recommend the meticulously engineered and extensively validated platforms from our partners (coming soon).
Failover Clustering. The built-in clustering feature of Windows Server is used to connect the servers.
Software Storage Bus. The Software Storage Bus is new in Storage Spaces Direct. It spans the cluster and establishes a software-defined storage fabric whereby all the servers can see all of each other’s local drives. You can think of it as replacing costly and restrictive Fibre Channel or Shared SAS cabling.
Storage Bus Layer Cache. The Software Storage Bus dynamically binds the fastest drives present (e.g. SSD) to slower drives (e.g. HDDs) to provide server-side read/write caching that accelerates IO and boosts throughput.
Storage Pool. The collection of drives that form the basis of Storage Spaces is called the storage pool. It is automatically created, and all eligible drives are automatically discovered and added to it. We strongly recommend you use one pool per cluster, with the default settings. Read our Deep Dive into the Storage Pool to learn more.
Storage Spaces. Storage Spaces provides fault tolerance to virtual «disks» using mirroring, erasure coding, or both. You can think of it as distributed, software-defined RAID using the drives in the pool. In Storage Spaces Direct, these virtual disks typically have resiliency to two simultaneous drive or server failures (e.g. 3-way mirroring, with each data copy in a different server) though chassis and rack fault tolerance is also available.
Resilient File System (ReFS). ReFS is the premier filesystem purpose-built for virtualization. It includes dramatic accelerations for .vhdx file operations such as creation, expansion, and checkpoint merging, and built-in checksums to detect and correct bit errors. It also introduces real-time tiers that rotate data between so-called «hot» and «cold» storage tiers in real-time based on usage.
Cluster Shared Volumes. The CSV file system unifies all the ReFS volumes into a single namespace accessible through any server, so that to each server, every volume looks and acts like it’s mounted locally.
Scale-Out File Server. This final layer is necessary in converged deployments only. It provides remote file access using the SMB3 access protocol to clients, such as another cluster running Hyper-V, over the network, effectively turning Storage Spaces Direct into network-attached storage (NAS).
Examples
Example 1: Get all storage pools
This example lists all storage pools, (when run without parameter) from all Storage Management Providers, from all storage subsystems.
This list may optionally be filtered using one or more parameters.
Example 2: Get all storage pools (not including primordial pools)
This example lists all (concrete) storage pools, excluding primordial pools (which store physical disks that have yet to be added to a concrete storage pool).
Example 3: Get all storage pools that support the Mirror resiliency setting
This example uses the Get-ResiliencySetting cmdlet to retrieve ResiliencySetting objects that represent each storage pool that supports the specified resiliency setting (also known as storage layout), in this case Mirror, and then pipes the array of objects to the Get-StoragePool cmdlet.
Что такое Internal Storage и где находится
Internal Storage в Android, как и следует из названия, – это внутренняя память устройства. Она есть у каждого девайса независимо от того, поддерживаются ли карты памяти. Внутреннее хранилище является защищённой областью встроенной памяти, где может безопасно храниться пользовательская информация. Папка Internal Storage в Android находится в системном разделе /data.
Пользователи часто ошибочно считают, что внутренняя память и встроенная – одно и то же, но это не так. Android SDK определяет внутреннее хранилище как отдельный уникальный каталог, где программа будет размещать свои файлы. Если приложение хранит информацию во встроенной памяти, другой софт, равно как и пользователь, не будут иметь доступ к этим данным, за исключением намеренного использования таких привилегий после получения на устройстве root-прав.
ВАЖНО
Стоит помнить, что ограничение доступа реализовано в Android не просто так, такие меры приняты, чтобы предупредить нарушение функций девайса в результате изменения, удаления системного каталога по неосторожности или незнанию пользователя.. Удаление программы с устройства подразумевает и автоматическое очищение системой внутренней памяти от связанных файлов, которые в отсутствии данного софта не нужны, что позволяет Android не накапливать лишний мусор
Удаление программы с устройства подразумевает и автоматическое очищение системой внутренней памяти от связанных файлов, которые в отсутствии данного софта не нужны, что позволяет Android не накапливать лишний мусор.
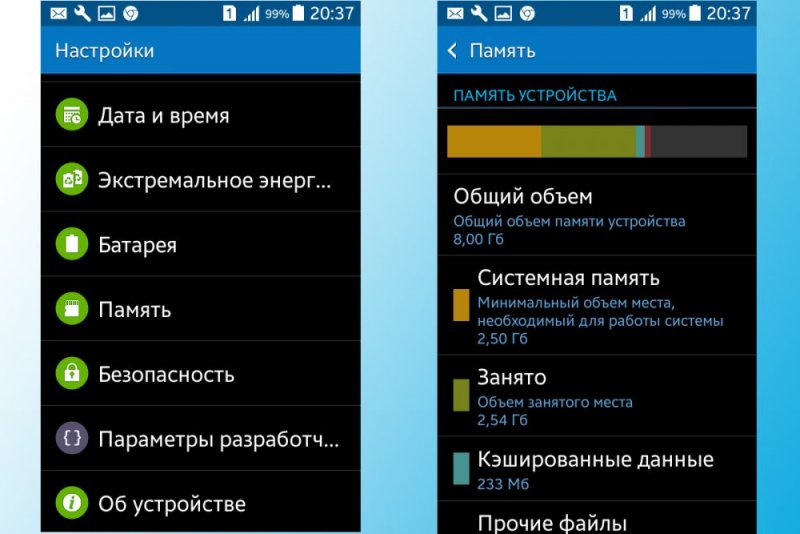
Объем памяти в настройках смартфона
Обычно найти папку можно в папке data/data/your.application.package.appname/someDirectory/
ВНИМАНИЕ. Конкретное расположение, где будут размещены файлы на Android-устройстве, может отличаться в зависимости от модели девайса и версии ОС, поэтому не нужно использовать заданные пути.. Пространство внутренней памяти устройства ограничено, и если требуется сохранить большой объём данных, лучше использовать другой тип хранения
Пространство внутренней памяти устройства ограничено, и если требуется сохранить большой объём данных, лучше использовать другой тип хранения.
СОВЕТ. Хотя приложения и устанавливаются по умолчанию в Internal Storage, в файле манифеста можно указать атрибут android:installLocation, после чего программу можно установить и на External Storage. Эта возможность выручает, когда файл слишком большой.







