Кодировка шрифта windows 1251 как установить
Содержание:
- Введение
- Кодовая страница ANSI
- Задания¶
- Таблица кодов символов Windows-1251
- Неправильная кодировка результатов из базы данных MySQL
- Базы банных
- Кодировки в windows / песочница / хабр
- за что отвечает и как работает
- Кодировка сайта | Что такое кодировка Юникод
- Таблица кодов символов Windows-1251
- Почему до сих пор используется 1251
Введение
Консольные приложения до сих пор остаются наиболее востребованным видом приложений, большинство разработчиков оттачивают архитектуру и бизнес-логику именно в консоли. При этом они нередко сталкиваются с проблемой локализации — русский текст, который вполне адекватно отражается в исходном файле, при выводе на консоль приобретает вид т.н. «кракозябр».
В целом, локализация консоли Windows при наличии соответствующего языкового пакета не представляется сложной. Тем не менее, полное и однозначное решение этой проблемы, в сущности, до сих пор не найдено. Причина этого, главным образом, кроется в самой природе консоли, которая, являясь компонентом системы, реализованным статическим классом System.Console, предоставляет свои методы приложению через системные программы-оболочки, такие как командная строка или командный процессор (cmd.exe), PowerShell, Terminal и другие. По сути, консоль находится под двойным управлением — приложения и оболочки, что является потенциально конфликтной ситуацией, в первую очередь в части использования кодировок.
Данный материал не предлагает строгий алгоритм действий, а направлен на описание узловых проблем, с которыми неизбежно сталкивается разработчик локализованного консольного приложения, а также некоторые возможные пути их разрешения. Предполагается, что это позволит разработчику сформировать стратегию работы с локализованной консолью и эффективно реализовать существующие технические возможности, большая часть которых хорошо описана и здесь опущена.
Кодовая страница ANSI
| Псевдоним (а) | ANSI (неверное название) |
|---|---|
| Стандарт | Стандарт кодирования WHATWG |
| Расширяется | US-ASCII |
| Предшествует | ISO 8859 |
| Преемник | Юникод UTF-16 (в Win32 API) |
Кодовые страницы ANSI (официально называемые «кодовыми страницами Windows» после того, как Microsoft приняла неправильное употребление первого термина) используются для приложений, не поддерживающих Unicode (скажем, ориентированных на байты ), использующих графический пользовательский интерфейс в системах Windows. Термин «ANSI» является неправильным, потому что эти кодовые страницы Windows не соответствуют ни одному стандарту ANSI; Кодовая страница 1252 была основана на раннем проекте ANSI, который стал международным стандартом ISO 8859-1 , который добавляет еще 32 управляющих кода и пространство для 96 печатаемых символов. Среди других отличий кодовые страницы Windows выделяют печатаемые символы в дополнительное пространство управляющего кода, что делает их в лучшем случае неразборчивыми для совместимых со стандартами операционных систем.)
Большинство устаревших кодовых страниц «ANSI» имеют номера кодовых страниц в шаблоне 125x. Тем не менее, (тайский) и восточноазиатские многобайтовые кодовые страницы ANSI ( , , , ), все из которых также используются в качестве кодовых страниц OEM, пронумерованы для соответствия аналогичным (но не идентичным) кодовым страницам IBM. кодировки. Хотя кодовая страница 1258 также используется как кодовая страница OEM, она является оригинальной для Microsoft, а не расширением существующей кодировки. IBM присвоила свои собственные, разные номера вариантам Microsoft, они приведены для справки в приведенных ниже списках, где это применимо.
Все кодовые страницы Windows 125x, а также 874 и 936, помечены Internet Assigned Numbers Authority (IANA) как « номер Windows», хотя «Windows-936» рассматривается как синоним « GBK ». Кодовая страница Windows 932 вместо этого помечена как «Windows-31J».
Кодовые страницы ANSI Windows, и особенно кодовая страница , были так названы, поскольку они якобы были основаны на черновиках, представленных или предназначенных для ANSI. Однако ANSI и ISO не стандартизировали ни одну из этих кодовых страниц. Вместо этого они либо:
- Надмножества стандартных наборов, таких как ISO 8859 и различных национальных стандартов (например, Windows-1252 и ISO-8859-1 ),
- Основные их модификации (делающие их несовместимыми в разной степени, например, Windows-1250 и ISO-8859-2 )
- Отсутствие параллельного кодирования (например, Windows-1257 против ISO-8859-4 ; ISO-8859-13 был введен намного позже). Кроме того, Windows-1251 не следует ни ISO-стандартизированному ISO-8859-5, ни преобладающему в то время KOI-8 .
Microsoft присвоила около двенадцати типографских и деловых символов (включая, в частности, знак евро , €) в CP1252 кодовые точки 0x80–0x9F, которые в ISO 8859 присвоены управляющим кодам C1 . Эти назначения также присутствуют во многих других кодовых страницах ANSI / Windows в тех же кодовых точках. Windows не использовала управляющие коды C1, поэтому это решение не имело прямого влияния на пользователей Windows. Однако при включении в файл, передаваемый на совместимую со стандартами платформу, такую как Unix или MacOS, информация была невидимой и потенциально опасной.
Задания¶
-
Доработайте прототип чата из прошлого урока таким образом, чтобы он корректно работал с русским языком (используйте методы кодирования и декодирования байтовых строк).
2. Напишите функцию для шифрования файла шифром Цезаря.
Расшифруйте:
key = 2 s = 'Oquv uvctu ctg qdugtxgf vq dg ogodgtu qh dkpctb uvct ubuvgou'
3. Напишите функцию для шифрования файла шифром пар.
Расшифруйте:
d_1 = 109, 122, 106, 115, 100, 99, 105, 120, 110, 98, 121, 118, 107 d_2 = 112, 103, 108, 104, 111, 102, 119, 117, 97, 101, 116, 113, 114 s = 'A hynk wh na nhykdadpwfnj delbfy fdahwhywaz dc n jxpwadxh hmsbkdwo dc mjnhpn sbjo ydzbysbk et wyh dia zknqwyt.'
Таблица кодов символов Windows-1251

Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Данная кодировка пользуется довольно большой популярностью в восточно-европейских странах.
Windows-1251 выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в традиционной русской типографике для обычного текста (отсутствует только знак ударения). Кириллические символы идут в алфавитном порядке.
Windows-1251 также содержит все символы для близких к русскому языку языков: белорусского, украинского, сербского, македонского и болгарского.
На практике этого оказалось достаточно, чтобы кодировка Windows-1251 закрепилась в интернете вплоть до распространения UTF-8.
| 000 | 00 | NOP | 128 | 80 | Ђ |
| 001 | 01 | SOH | 129 | 81 | Ѓ |
| 002 | 02 | STX | 130 | 82 | ‚ |
| 003 | 03 | ETX | 131 | 83 | ѓ |
| 004 | 04 | EOT | 132 | 84 | „ |
| 005 | 05 | ENQ | 133 | 85 | … |
| 006 | 06 | ACK | 134 | 86 | † |
| 007 | 07 | BEL | 135 | 87 | ‡ |
| 008 | 08 | BS | 136 | 88 | € |
| 009 | 09 | TAB | 137 | 89 | ‰ |
| 010 | 0A | LF | 138 | 8A | Љ |
| 011 | 0B | VT | 139 | 8B | ‹ |
| 012 | 0C | FF | 140 | 8C | Њ |
| 013 | 0D | CR | 141 | 8D | Ќ |
| 014 | 0E | SO | 142 | 8E | Ћ |
| 015 | 0F | SI | 143 | 8F | Џ |
| 016 | 10 | DLE | 144 | 90 | ђ |
| 017 | 11 | DC1 | 145 | 91 | ‘ |
| 018 | 12 | DC2 | 146 | 92 | ’ |
| 019 | 13 | DC3 | 147 | 93 | “ |
| 020 | 14 | DC4 | 148 | 94 | ” |
| 021 | 15 | NAK | 149 | 95 | • |
| 022 | 16 | SYN | 150 | 96 | – |
| 023 | 17 | ETB | 151 | 97 | — |
| 024 | 18 | CAN | 152 | 98 | |
| 025 | 19 | EM | 153 | 99 | |
| 026 | 1A | SUB | 154 | 9A | љ |
| 027 | 1B | ESC | 155 | 9B | › |
| 028 | 1C | FS | 156 | 9C | њ |
| 029 | 1D | GS | 157 | 9D | ќ |
| 030 | 1E | RS | 158 | 9E | ћ |
| 031 | 1F | US | 159 | 9F | џ |
| 032 | 20 | SP | 160 | A0 | |
| 033 | 21 | ! | 161 | A1 | Ў |
| 034 | 22 | “ | 162 | A2 | ў |
| 035 | 23 | # | 163 | A3 | Ћ |
| 036 | 24 | $ | 164 | A4 | ¤ |
| 037 | 25 | % | 165 | A5 | Ґ |
| 038 | 26 | & | 166 | A6 | ¦ |
| 039 | 27 | ‘ | 167 | A7 | § |
| 040 | 28 | ( | 168 | A8 | Ё |
| 041 | 29 | ) | 169 | A9 | |
| 042 | 2A | * | 170 | AA | Є |
| 043 | 2B | + | 171 | AB | |
| 044 | 2C | , | 172 | AC | ¬ |
| 045 | 2D | – | 173 | AD | |
| 046 | 2E | . | 174 | AE | |
| 047 | 2F | 175 | AF | Ї | |
| 048 | 30 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± |
| 050 | 32 | 2 | 178 | B2 | І |
| 051 | 33 | 3 | 179 | B3 | і |
| 052 | 34 | 4 | 180 | B4 | ґ |
| 053 | 35 | 5 | 181 | B5 | µ |
| 054 | 36 | 6 | 182 | B6 | ¶ |
| 055 | 37 | 7 | 183 | B7 | · |
| 056 | 38 | 8 | 184 | B8 | ё |
| 057 | 39 | 9 | 185 | B9 | № |
| 058 | 3A | 186 | BA | є | |
| 059 | 3B | ; | 187 | BB | |
| 060 | 3C | 190 | BE | ѕ | |
| 063 | 3F | ? | 191 | BF | ї |
| 064 | 40 | @ | 192 | C0 | А |
| 065 | 41 | A | 193 | C1 | Б |
| 066 | 42 | B | 194 | C2 | В |
| 067 | 43 | C | 195 | C3 | Г |
| 068 | 44 | D | 196 | C4 | Д |
| 069 | 45 | E | 197 | C5 | Е |
| 070 | 46 | F | 198 | C6 | Ж |
| 071 | 47 | G | 199 | C7 | З |
| 072 | 48 | H | 200 | C8 | И |
| 073 | 49 | I | 201 | C9 | Й |
| 074 | 4A | J | 202 | CA | К |
| 075 | 4B | K | 203 | CB | Л |
| 076 | 4C | L | 204 | CC | М |
| 077 | 4D | M | 205 | CD | Н |
| 078 | 4E | N | 206 | CE | О |
| 079 | 4F | O | 207 | CF | П |
| 080 | 50 | P | 208 | D0 | Р |
| 081 | 51 | Q | 209 | D1 | С |
| 082 | 52 | R | 210 | D2 | Т |
| 083 | 53 | S | 211 | D3 | У |
| 084 | 54 | T | 212 | D4 | Ф |
| 085 | 55 | U | 213 | D5 | Х |
| 086 | 56 | V | 214 | D6 | Ц |
| 087 | 57 | W | 215 | D7 | Ч |
| 088 | 58 | X | 216 | D8 | Ш |
| 089 | 59 | Y | 217 | D9 | Щ |
| 090 | 5A | Z | 218 | DA | Ъ |
| 091 | 5B | 219 | DB | Ы | |
| 092 | 5C | 220 | DC | Ь | |
| 093 | 5D | 221 | DD | Э | |
| 094 | 5E | ^ | 222 | DE | Ю |
| 095 | 5F | _ | 223 | DF | Я |
| 096 | 60 | ` | 224 | E0 | а |
| 097 | 61 | a | 225 | E1 | б |
| 098 | 62 | b | 226 | E2 | в |
| 099 | 63 | c | 227 | E3 | г |
| 100 | 64 | d | 228 | E4 | д |
| 101 | 65 | e | 229 | E5 | е |
| 102 | 66 | f | 230 | E6 | ж |
| 103 | 67 | g | 231 | E7 | з |
| 104 | 68 | h | 232 | E8 | и |
| 105 | 69 | i | 233 | E9 | й |
| 106 | 6A | j | 234 | EA | к |
| 107 | 6B | k | 235 | EB | л |
| 108 | 6C | l | 236 | EC | м |
| 109 | 6D | m | 237 | ED | н |
| 110 | 6E | n | 238 | EE | о |
| 111 | 6F | o | 239 | EF | п |
| 112 | 70 | p | 240 | F0 | р |
| 113 | 71 | q | 241 | F1 | с |
| 114 | 72 | r | 242 | F2 | т |
| 115 | 73 | s | 243 | F3 | у |
| 116 | 74 | t | 244 | F4 | ф |
| 117 | 75 | u | 245 | F5 | х |
| 118 | 76 | v | 246 | F6 | ц |
| 119 | 77 | w | 247 | F7 | ч |
| 120 | 78 | x | 248 | F8 | ш |
| 121 | 79 | y | 249 | F9 | щ |
| 122 | 7A | z | 250 | FA | ъ |
| 123 | 7B | { | 251 | FB | ы |
| 124 | 7C | | | 252 | FC | ь |
| 125 | 7D | } | 253 | FD | э |
| 126 | 7E | ~ | 254 | FE | ю |
| 127 | 7F | DEL | 255 | FF | я |
Описание специальных (управляющих) символов
Первоначально управляющие символы таблицы ASCII (диапазон 00-31, плюс 127) были разработаны для того, чтобы управлять устройствами аппаратных средств, таких как телетайп, ввод данных на перфоленту и др.Управляющие символы (кроме горизонтальной табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
КодОписание
NUL, 00
Null, пустой
SOH, 01
Start Of Heading, начало заголовка
STX, 02
Start of TeXt, начало текста
ETX, 03
End of TeXt, конец текста
EOT, 04
End of Transmission, конец передачи
ENQ, 05
Enquire. Прошу подтверждения
ACK, 06
Acknowledgement. Подтверждаю
BEL, 07
Bell, звонок
BS, 08
Backspace, возврат на один символ назад
TAB, 09
Tab, горизонтальная табуляция
LF, 0A
Line Feed, перевод строкиСейчас в большинстве языков программирования обозначается как
VT, 0B
Vertical Tab, вертикальная табуляция
FF, 0C
Form Feed, прогон страницы, новая страница
CR, 0D
Carriage Return, возврат кареткиСейчас в большинстве языков программирования обозначается как
SO, 0E
Shift Out, изменить цвет красящей ленты в печатающем устройстве
SI, 0F
Shift In, вернуть цвет красящей ленты в печатающем устройстве обратно
DLE, 10
Data Link Escape, переключение канала на передачу данных
DC1, 11 DC2, 12DC3, 13DC4, 14
Device Control, символы управления устройствами
NAK, 15
Negative Acknowledgment, не подтверждаю
SYN, 16
Synchronization. Символ синхронизации
ETB, 17
End of Text Block, конец текстового блока
CAN, 18
Cancel, отмена переданного ранее
EM, 19
End of Medium, конец носителя данных
SUB, 1A
Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче
ESC, 1B
Escape Управляющая последовательность
FS, 1C
File Separator, разделитель файлов
GS, 1D
Group Separator, разделитель групп
RS, 1E
Record Separator, разделитель записей
US, 1F
Unit Separator, разделитель юнитов
DEL, 7F
Delete, стереть последний символ.
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:
Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8. Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin
Для этого:
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
mysql -u root -p
Если вы забыли имя базы данных, то выполните команду:
SHOW DATABASES;
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
USE information_schema;
Если вы забыли имя таблиц, выполните:
SHOW TABLES;
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
SHOW FULL COLUMNS FROM имя_таблицы;
Например:
SHOW FULL COLUMNS FROM GLOBAL_STATUS;
Вы увидите примерно следующее:
Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
SET NAMES UTF8 SET CHARACTER SET UTF8 SET character_set_client = UTF8 SET character_set_connection = UTF8 SET character_set_results = UTF8
В PHP это можно сделать примерно так:
$this->mysqli = new mysqli($server, $username, $password, $basename); if ($this->mysqli->connect_error) { $this->errorHandler_c->logError(1, ‘Connect Error (‘ . $this->mysqli->connect_errno . ‘) ‘ . $this->mysqli->connect_error, $_SERVER ); } $this->mysqli->query(«SET NAMES UTF8»); $this->mysqli->query(«SET CHARACTER SET UTF8»); $this->mysqli->query(«SET character_set_client = UTF8»); $this->mysqli->query(«SET character_set_connection = UTF8»); $this->mysqli->query(«SET character_set_results = UTF8»);
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
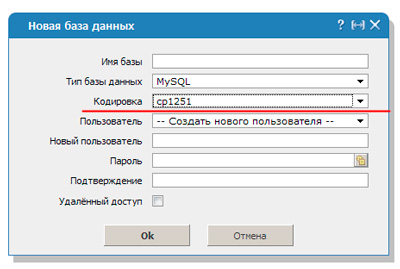
Кодировки в windows / песочница / хабр
В данной статье пойдёт речь о кодировках в Windows. Все в жизни хоть раз использовали и писали консольные приложения как таковые. Нету разницы для какой причины. Будь-то выбивание процесса или же просто написать «Привет!!! Я не могу сделать кодировку нормальной, поэтому я смотрю эту статью!».
Тем, кто ещё не понимает, о чём проблема, то вот Вам:
А тут было написано:
echo Я абракадабра, написанная автором.
Но никто ничего не понял.
В любом случае в Windows до 10 кодировка BAT и других языков, не использует кодировку поддерживающую Ваш язык, поэтому все русские символы будут писаться неправильно.
1. Настройка консоли в батнике
Сразу для тех, кто пишет chcp 1251 лучше написать это:
assoc .bat = .mp4
Первый способ устранения проблемы, это
Notepad
. Для этого Вам нужно открыть Ваш батник таким способом:
Не бойтесь, у Вас откроется код Вашего батника, а затем Вам нужно будет сделать следующие действия:
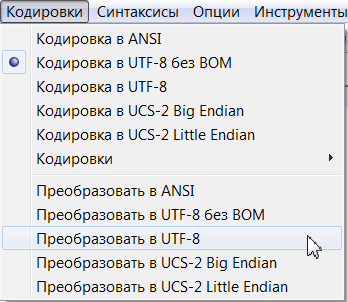
Если Вам ничего не помогло, то преобразуйте в UTF-8 без BOM.
2. Написание консольных программ Нередко люди пишут консольные программы(потому что на некоторых десктопные писать невозможно), а кодировка частая проблема.
Первый способ непосредственно Notepad , но а если нужно сначала одну кодировку, а потом другую?
Сразу для использующих chcp 1251 пишите это:
del C:Program Data echo Mne pofig pause
Второй способ это написать десктопную программу, или же использовать Visual Studio. Если же не помогает, то есть первое: изменение кодировки вывода(Пример на C ).
#include #include int main() { SetConsoleCP(номер_кодировки); SetConsoleOutputCP(номер_кодировки); }
Если же не сработает:
#include //Не забываем про библиотеку Math. char bufRus; char* Rus(const char* text) { CharToOem(text, bufRus); return bufRus } int main { cout << «Тут пишите, что угодно!» << endl; system(«pause») return 0 }
3. Изменение chcp 1251
Если же у Вас батник, то напишите в начало:
chcp 1251 >nul for /f «delims=» %%A in («Мой текст») do >nul chcp 866& echo.%%A
Теперь у Нас будет нормальный вывод в консоль. На других языках (С ):
SetConsoleOutputCP(1251) //А тут добавляете тот цикл, который был в батнике
4. Сделать жизнь мёдом
При использовании данного способа Вы не сможете:
- Разрабатывать приложения на Windows ниже 10
- Спасти мир от данной проблемы
- Думать о других людях
- Разрабатывать десктопные приложения, так как Вам жизнь покажется мёдом
- Сменить Windows на версию ниже 10
- Ну и понимать людей, у которых Windows ниже 10
:/> Установка Windows 10 на диск MBR и GPT при наличии BIOS или UEFI Установить Windows 10. Там кодировка консоли специально подходит для языка страны, и Вам больше не нужно будет беспокоиться об этой проблеме. Но у Вас появится ещё 6 проблем, и вернуться к предыдущей лицензионной версии Windows Вы не сможете.
за что отвечает и как работает
В начале 90-х, когда произошел развал СССР и границы России были открыты, к нам стали поступать программные продукты западного производства. Естественно, все они были англоязычными. В это же время начинает развиваться Интернет. Остро встала проблема русификации ресурсов и программ. Тогда и была придумана русская кодировка Windows 1251. Она позволяет корректно отображать буквы славянских алфавитов:
- русского;
- украинского;
- белорусского;
- сербского;
- болгарского;
- македонского.
Разработка велась русским представительством Microsoft совместно с компаниями «Диалог» и «Параграф». За основу были взяты самописные разработки, которые в 1990-91гг имели хождение среди немногочисленных идеологов ИТ в России.
На сегодняшний день разработан более универсальный способ кодировать символы — UTF-8 (Юникод). В нем представлено почти 90% всех программных и веб-ресурсов. Windows 1251 применяется в 1,6% случаев. (Информация по исследованиям Web Technology Surveys)
Кодировка сайта utf 8 или Windows 1251?
Чтобы ответить на этот вопрос, необходимо немного понять, что такое кодировка и чем они отличаются. Текстовая информация, как впрочем, и любая другая, в компьютере хранится в закодированном виде. Нам легче представить ее как числа. Каждый символ может занимать один или более байт. Windows 1251 является однобайтной кодировкой, а UTF-8 восьмибайтной. Это значит, что в Windows 1251 можно закодировать всего 256 символов.Так как все сводится к двоичной системе исчисления, а байт – это 8 бит (0 и 1), то и максимальное число сочетаний составляет 28 = 256. Юникод позволяет представлять куда большее число символов, да и на каждый может быть выделен больший размер.
Отсюда и следуют преимущества Юникода:
- В шапке сайта следует указать кодировку, которая используется. Иначе вместо символов отобразятся «кракозяблы». А Юникод является стандартным для всех браузеров – они ловят его «на лету» как установленный по умолчанию.
- Символы сайта останутся одними и теми же, независимо от того, в какой стране загружается ресурс. Это зависит не от географического расположения серверов, а от языка программного обеспечения рабочих станций клиента. Житель Португалии, очевидно, использует клавиатуру и все ПО, включая операционную систему, на родном языке. В его компьютере, скорее всего вообще отсутствует Windows 1251. А если это так, то и сайты на русском языке корректно открываться не будут. Юникод, в свою очередь, «зашит» в любую ОС на любом языке.
- UTF-8 позволяет закодировать большее количество символов. На данный момент используется 6 байт из 8-ми, а русские символы кодируются двумя байтами.Именно поэтому предпочтительней использовать универсальную кодировку, а не узкоспециализированную, которая применяется только в славянских странах.
Таблица кодировки Windows 1251
Для программистов и разработчиков сайтов бывает необходимо знать номера символов. Для этого используются специальные таблицы кодировки. Ниже представлена таблица для Windows 1251.
Что делать, если слетела кодировка командной строки?
Иногда Вы можете столкнуться с ситуацией, когда в командной строке вместо русских отображаются непонятные символы. Это означает, что возникла проблема кодировки командной строки Windows 7. Почему 7-ка? Потому что, начиная с 8-й версии, используется UTF-8, а в семерке еще Windows 1251.Единовременно помочь решить проблему может команда chcp 866. Текущий сеанс будет работать корректно. А вот чтобы исправить ошибку кардинально, понадобится реестр.
- Нажмите Win+R и наберите команду regedit. Это позволит попасть в редактор реестра.
- Перейдите по ветке HKEY_CURRENT_USER\Console и посмотрите, чему равно значение для CodePage. Скорее всего, вы увидите что-то, отличное от 866 (правильный вариант).
- Исправьте на 866 в положении «Десятичная».
- Закройте и откройте вновь командную строку. Ситуация должна исправиться.
Кодировка сайта | Что такое кодировка Юникод
Кодировка сайта (Encoding) представляет собой соответствие числового ряда символам (числа, буквы, знаки и другие спецсимволы). Наиболее распространенными кодировками считаются ASCII совместно с Юникодом UTF-8 и Windows-1251. В контенте за кодировку отвечает специальный мета-тег: , который устанавливает определенный тип кода для страниц. В данном случае это юникод UTF-8.
Что такое кодировка сайта
Простыми словами это стандартные символы и цифры, которые соответствуют определенному типу набору письменных букв, чисел, знаков и прочих элементов. Чаще всего на сайте используется один тип кодировки, но бывают исключения, когда может быть установлено сразу несколько кодировок. Однако это может привести к некорректному отображению всего веб-ресурса.
Множество сайтов используют стандарт кодировки — UTF-8, так как именно этот вид кода поддерживается многими известнымибраузерами, поисковыми машинами, серверами и другими платформами. Очень часто встречаются ситуации, когда указанная на веб-сайте кодировка не совпадает с той, что установлена на сервере.
Каждый символ, который виден на сайте, для компьютера представляет всего лишь набор битов (некоторый набор из нулей и прочих единиц).
Виды кодировок сайта
Всего в мире интернета существует несколько видов кодировок:
- ASCII – самая первая кодировка, которая была принята Американским национальным институтом мировых стандартов. Для кодировки использовалось всего 7 бит, где впервые 128 значения размещается English алфавит, а также все числа, знаки и символы. Данная кодировка не является универсальной и чаще всего использовалась на англоязычных сайтах.
- Кириллица – истинно отечественный вариант. Кодировка использовала вторую часть основной кодовой таблицы, а точнее знаков с 129 по 256. Используется на русскоязычных сайтах и блогах.
- Кодировки 1250-1258 (системы MS Windows и Windows) – стандартные 8-ми битные кодировки, которые появились сразу после выхода известной операционной системы Microsoft Windows. Числа 1250 по 1258 направлены на используемый кодировкой язык. 1250 – это языки центральной Европы, а 1251 вариант для кириллического алфавита.
- КОИ8 – расшифровывается как код обмена информацией 8-ми битный. Обычно применяются стандарты русской кириллицы в системах Юникс и подобных, где действует стандарт KOI-7, KOI8-R и KOI8-U.
- Юникод (оригинальное название Unicode) – является известным стандартом для кодирования символов, который позволяет описывать знаки буквально всех мировых языков. Часто обозначается «U+xxxx», где «хххх» — это 16-ричные значения. Наиболее распространенным семейством данной кодировки считается UTF (Unicode-Transformation Format), то есть UTF-8, 16 и 32.
Каждый отдельный вид может использоваться непосредственно на любом сайте.
Универсальные и популярные кодировки
На сегодняшний день наиболее популярной и всем известной считается кодировка UTF-8, а именно благодаря ей возможно обеспечить максимальную совместимость со всеми старыми системами, которые использовали обычные 8-бит типы символов. Кодировка UTF-8 включает в себя большинство сайтов, которые находятся в интернете, а именно данный стандарт считается универсальным. UTF-8 поддерживает как кириллицу, так и латиницу.
Таблица кодов символов Windows-1251
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Данная кодировка пользуется довольно большой популярностью в восточно-европейских странах.
Windows-1251 выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в традиционной русской типографике для обычного текста (отсутствует только знак ударения). Кириллические символы идут в алфавитном порядке.
Windows-1251 также содержит все символы для близких к русскому языку языков: белорусского, украинского, сербского, македонского и болгарского.
На практике этого оказалось достаточно, чтобы кодировка Windows-1251 закрепилась в интернете вплоть до распространения UTF-8.
| 000 | 00 | NOP | 128 | 80 | Ђ |
| 001 | 01 | SOH | 129 | 81 | Ѓ |
| 002 | 02 | STX | 130 | 82 | ‚ |
| 003 | 03 | ETX | 131 | 83 | ѓ |
| 004 | 04 | EOT | 132 | 84 | „ |
| 005 | 05 | ENQ | 133 | 85 | … |
| 006 | 06 | ACK | 134 | 86 | † |
| 007 | 07 | BEL | 135 | 87 | ‡ |
| 008 | 08 | BS | 136 | 88 | € |
| 009 | 09 | TAB | 137 | 89 | ‰ |
| 010 | 0A | LF | 138 | 8A | Љ |
| 011 | 0B | VT | 139 | 8B | ‹ |
| 012 | 0C | FF | 140 | 8C | Њ |
| 013 | 0D | CR | 141 | 8D | Ќ |
| 014 | 0E | SO | 142 | 8E | Ћ |
| 015 | 0F | SI | 143 | 8F | Џ |
| 016 | 10 | DLE | 144 | 90 | ђ |
| 017 | 11 | DC1 | 145 | 91 | ‘ |
| 018 | 12 | DC2 | 146 | 92 | ’ |
| 019 | 13 | DC3 | 147 | 93 | “ |
| 020 | 14 | DC4 | 148 | 94 | ” |
| 021 | 15 | NAK | 149 | 95 | • |
| 022 | 16 | SYN | 150 | 96 | – |
| 023 | 17 | ETB | 151 | 97 | — |
| 024 | 18 | CAN | 152 | 98 | |
| 025 | 19 | EM | 153 | 99 | |
| 026 | 1A | SUB | 154 | 9A | љ |
| 027 | 1B | ESC | 155 | 9B | › |
| 028 | 1C | FS | 156 | 9C | њ |
| 029 | 1D | GS | 157 | 9D | ќ |
| 030 | 1E | RS | 158 | 9E | ћ |
| 031 | 1F | US | 159 | 9F | џ |
| 032 | 20 | SP | 160 | A0 | |
| 033 | 21 | ! | 161 | A1 | Ў |
| 034 | 22 | “ | 162 | A2 | ў |
| 035 | 23 | # | 163 | A3 | Ћ |
| 036 | 24 | $ | 164 | A4 | ¤ |
| 037 | 25 | % | 165 | A5 | Ґ |
| 038 | 26 | & | 166 | A6 | ¦ |
| 039 | 27 | ‘ | 167 | A7 | § |
| 040 | 28 | ( | 168 | A8 | Ё |
| 041 | 29 | ) | 169 | A9 | |
| 042 | 2A | * | 170 | AA | Є |
| 043 | 2B | + | 171 | AB | |
| 044 | 2C | , | 172 | AC | ¬ |
| 045 | 2D | – | 173 | AD | |
| 046 | 2E | . | 174 | AE | |
| 047 | 2F | 175 | AF | Ї | |
| 048 | 30 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± |
| 050 | 32 | 2 | 178 | B2 | І |
| 051 | 33 | 3 | 179 | B3 | і |
| 052 | 34 | 4 | 180 | B4 | ґ |
| 053 | 35 | 5 | 181 | B5 | µ |
| 054 | 36 | 6 | 182 | B6 | ¶ |
| 055 | 37 | 7 | 183 | B7 | · |
| 056 | 38 | 8 | 184 | B8 | ё |
| 057 | 39 | 9 | 185 | B9 | № |
| 058 | 3A | 186 | BA | є | |
| 059 | 3B | ; | 187 | BB | |
| 060 | 3C | 190 | BE | ѕ | |
| 063 | 3F | ? | 191 | BF | ї |
| 064 | 40 | @ | 192 | C0 | А |
| 065 | 41 | A | 193 | C1 | Б |
| 066 | 42 | B | 194 | C2 | В |
| 067 | 43 | C | 195 | C3 | Г |
| 068 | 44 | D | 196 | C4 | Д |
| 069 | 45 | E | 197 | C5 | Е |
| 070 | 46 | F | 198 | C6 | Ж |
| 071 | 47 | G | 199 | C7 | З |
| 072 | 48 | H | 200 | C8 | И |
| 073 | 49 | I | 201 | C9 | Й |
| 074 | 4A | J | 202 | CA | К |
| 075 | 4B | K | 203 | CB | Л |
| 076 | 4C | L | 204 | CC | М |
| 077 | 4D | M | 205 | CD | Н |
| 078 | 4E | N | 206 | CE | О |
| 079 | 4F | O | 207 | CF | П |
| 080 | 50 | P | 208 | D0 | Р |
| 081 | 51 | Q | 209 | D1 | С |
| 082 | 52 | R | 210 | D2 | Т |
| 083 | 53 | S | 211 | D3 | У |
| 084 | 54 | T | 212 | D4 | Ф |
| 085 | 55 | U | 213 | D5 | Х |
| 086 | 56 | V | 214 | D6 | Ц |
| 087 | 57 | W | 215 | D7 | Ч |
| 088 | 58 | X | 216 | D8 | Ш |
| 089 | 59 | Y | 217 | D9 | Щ |
| 090 | 5A | Z | 218 | DA | Ъ |
| 091 | 5B | 219 | DB | Ы | |
| 092 | 5C | 220 | DC | Ь | |
| 093 | 5D | 221 | DD | Э | |
| 094 | 5E | ^ | 222 | DE | Ю |
| 095 | 5F | _ | 223 | DF | Я |
| 096 | 60 | ` | 224 | E0 | а |
| 097 | 61 | a | 225 | E1 | б |
| 098 | 62 | b | 226 | E2 | в |
| 099 | 63 | c | 227 | E3 | г |
| 100 | 64 | d | 228 | E4 | д |
| 101 | 65 | e | 229 | E5 | е |
| 102 | 66 | f | 230 | E6 | ж |
| 103 | 67 | g | 231 | E7 | з |
| 104 | 68 | h | 232 | E8 | и |
| 105 | 69 | i | 233 | E9 | й |
| 106 | 6A | j | 234 | EA | к |
| 107 | 6B | k | 235 | EB | л |
| 108 | 6C | l | 236 | EC | м |
| 109 | 6D | m | 237 | ED | н |
| 110 | 6E | n | 238 | EE | о |
| 111 | 6F | o | 239 | EF | п |
| 112 | 70 | p | 240 | F0 | р |
| 113 | 71 | q | 241 | F1 | с |
| 114 | 72 | r | 242 | F2 | т |
| 115 | 73 | s | 243 | F3 | у |
| 116 | 74 | t | 244 | F4 | ф |
| 117 | 75 | u | 245 | F5 | х |
| 118 | 76 | v | 246 | F6 | ц |
| 119 | 77 | w | 247 | F7 | ч |
| 120 | 78 | x | 248 | F8 | ш |
| 121 | 79 | y | 249 | F9 | щ |
| 122 | 7A | z | 250 | FA | ъ |
| 123 | 7B | { | 251 | FB | ы |
| 124 | 7C | | | 252 | FC | ь |
| 125 | 7D | } | 253 | FD | э |
| 126 | 7E | ~ | 254 | FE | ю |
| 127 | 7F | DEL | 255 | FF | я |
Описание специальных (управляющих) символов
Первоначально управляющие символы таблицы ASCII (диапазон 00-31, плюс 127) были разработаны для того, чтобы управлять устройствами аппаратных средств, таких как телетайп, ввод данных на перфоленту и др.Управляющие символы (кроме горизонтальной табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
КодОписание
NUL, 00
Null, пустой
SOH, 01
Start Of Heading, начало заголовка
STX, 02
Start of TeXt, начало текста
ETX, 03
End of TeXt, конец текста
EOT, 04
End of Transmission, конец передачи
ENQ, 05
Enquire. Прошу подтверждения
ACK, 06
Acknowledgement. Подтверждаю
BEL, 07
Bell, звонок
BS, 08
Backspace, возврат на один символ назад
TAB, 09
Tab, горизонтальная табуляция
LF, 0A
Line Feed, перевод строкиСейчас в большинстве языков программирования обозначается как
VT, 0B
Vertical Tab, вертикальная табуляция
FF, 0C
Form Feed, прогон страницы, новая страница
CR, 0D
Carriage Return, возврат кареткиСейчас в большинстве языков программирования обозначается как
SO, 0E
Shift Out, изменить цвет красящей ленты в печатающем устройстве
SI, 0F
Shift In, вернуть цвет красящей ленты в печатающем устройстве обратно
DLE, 10
Data Link Escape, переключение канала на передачу данных
DC1, 11 DC2, 12DC3, 13DC4, 14
Device Control, символы управления устройствами
NAK, 15
Negative Acknowledgment, не подтверждаю
SYN, 16
Synchronization. Символ синхронизации
ETB, 17
End of Text Block, конец текстового блока
CAN, 18
Cancel, отмена переданного ранее
EM, 19
End of Medium, конец носителя данных
SUB, 1A
Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче
ESC, 1B
Escape Управляющая последовательность
FS, 1C
File Separator, разделитель файлов
GS, 1D
Group Separator, разделитель групп
RS, 1E
Record Separator, разделитель записей
US, 1F
Unit Separator, разделитель юнитов
DEL, 7F
Delete, стереть последний символ.
Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
Ввод специальных символов в документах системы windows
- Многие программисты php используют стандартную кодировку, поскольку OC Windows ее поддерживает в режиме по умолчанию. И хотя в последнее время разработчики стали активно внедрять UTF-8, все же 1251 пока не сдает свои активные позиции
- Если брать для примера старую версию MySQL до четвертой, то стоит отметить, что при включении даже тестового режима, вылезало множество ошибок в UTF-8. Только после выпуска 4.1 многие «глюки» были исправлены. Существует категория программистов, которая вовсе остается верна 1251, а их последователи рьяно берут с них пример и даже не собираются использовать нечто другое
- Поскольку один символ в системе 1251 весит меньше (один байт), то вполне логично, что возникает некая экономия в отличие от последнего варианта.
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
- Возможно включение любых знаков из набора Юникода. Кроме того, вполне логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти от стандартных смайликов до апострофа абсолютно все. Их использование возможно в любом документе. Кроме того, их можно прочитать даже в редакторе, что исключает вероятность появления нечитабельных знаков
- Ранее существовало мнение о том, что современный utf занимает больше места. В итоге оказалось, что символы также весят всего лишь байт. Значит, стоит сделать вывод о том, что увеличение веса странички не происходит и ее использование такое же легкое. Однако, если используется только русский алфавит, то в таком случае размер будет увеличен вдвое, поскольку изначально кириллица не включена в систему
- Система считается одной из самых универсальных, которые уже смогли достать. В таком случае можно создавать сайты для любого населения мира. Можно уже не думать о том, какая кодировка используется, поскольку Юникод является универсальной вещью
- UTF – это оптимальный вариант работы с php страницами.
Важно отметить, что изначально многие разработчики стали использовать 1251. И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
,
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.
Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием







