Linux grep command
Содержание:
- Grep NOT
- 2. Примеры использования команды Grep
- grep примеры использования
- ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ
- Расширенные регулярные выражения
- Назначение операторов find и grep
- Other options
- Why do we use grep?
- Checking for the given string in multiple files.
- Регулярные выражения Linux
- Context line control
- Catch space or tab
- Grep OR Operator
Grep NOT
7. Grep NOT using grep -v
Using grep -v you can simulate the NOT conditions. -v option is for invert match. i.e It matches all the lines except the given pattern.
grep -v 'pattern1' filename
For example, display all the lines except those that contains the keyword “Sales”.
$ grep -v Sales employee.txt 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 400 Nisha Manager Marketing $9,500
You can also combine NOT with other operator to get some powerful combinations.
For example, the following will display either Manager or Developer (bot ignore Sales).
$ egrep 'Manager|Developer' employee.txt | grep -v Sales 200 Jason Developer Technology $5,500 400 Nisha Manager Marketing $9,500
2. Примеры использования команды Grep
Теперь мы увидим, как использовать команду Grep в Linux.
Как использовать Grep в общем
Чтобы понять, как работает Grep, мы посмотрим в каталоге / etc / passwd все результаты, связанные с нашим пользователем:
grep solvetic / etc / passwd
В качестве дополнительного момента помните, что можно сказать, что grep игнорирует прописные и строчные буквы в результатах, для этого мы выполним следующее:
grep -i "resoltic" / etc / passwd
Grep идеально подходит для поиска определенных терминов в известных файлах, например, мы выполним следующий поиск:
grep Solvetic Solvetic.txt
Этот же термин можно искать в разных файлах одновременно, для этого мы будем использовать следующую строку:
grep Solvetic Solvetic.txt Solvetic1.txt
Более сокращенный способ сделать это — выполнить следующее:
grep solvetic *. *
Как использовать grep для перенаправления результатов в файл в Linux
Это полезно в тех случаях, когда мы должны выполнить административные задачи над файлами позже, поэтому можно перенаправить вывод команды grep в определенный файл, например, мы сделаем следующее:
grep Solvetic Solvetic.txt> Solvetic2.txt
Как использовать grep для поиска в каталогах
Благодаря параметру -r мы сможем найти значение в доступных подкаталогах, выполним следующее:
grep -r Solvetic / домашний / решающий
Как использовать grep для отображения номера строки
Для задач аудита или расширенной поддержки идеально отображать номер строки, в которой находится указанный шаблон поиска, для этого мы можем использовать параметр -n следующим образом. Там мы находим номер строки, где находится каждое значение.
grep -n Solvetic Solvetic.txt
Как использовать grep для выделения результатов
Поскольку мы знаем, что текст во многих случаях может сбить с толку, по этой причине решение состоит в том, чтобы выделить критерии поиска, которые фокусируют наше представление непосредственно на этой строке, для этого мы будем использовать параметр цвета, например:
grep -color Solvetic Solvetic.txt
Как использовать grep для отображения строк, начинающихся или заканчивающихся указанным шаблоном
Мы можем захотеть визуализировать только результаты строк, которые начинаются или заканчиваются критериями поиска, для этого, если мы хотим найти строки, которые начинаются, мы будем использовать следующую строку:
grep ^ Solvetic Solvetic.txt
Теперь, чтобы отобразить строки, которые заканчиваются, мы будем использовать следующее:
grep Solvetic $ Solvetic.txt
Как использовать grep для печати всех строк, не видя совпадающих
Если мы хотим увидеть все строки, кроме тех, где задано желаемое значение, мы должны использовать параметр -v следующим образом:
grep -v Solvetic Solvetic.txt
Как использовать grep с другими командами
Grep, как и многие команды Linux, можно использовать одновременно с другими командами для получения более четких результатов, например, если мы хотим развернуть процессы HTTP, мы будем использовать grep рядом с ps следующим образом:
ps -ef | grep http
Как использовать grep, чтобы посчитать, сколько слов повторяется в файле
Если мы хотим узнать, сколько раз шаблон повторяется в данном файле, мы будем использовать параметр -c:
grep -c Solvetic Solvetic.txt
Как использовать grep для обратного поиска
Хотя это звучит странно, это не что иное, как отображение в результате слов, которые мы не указываем, это достигается с помощью параметра -v:
grep -v Solvetic Solvetic2.txt
Как использовать grep для просмотра сведений об оборудовании
Ранее мы видели, что мы можем комбинировать grep с другими командами для отображения результата, ну, если мы хотим получить конкретные сведения об оборудовании, мы можем использовать cat с grep следующим образом:
cat / proc / cpuinfo | grep -i 'Модель'
Во всем мире мы узнали, как использовать команду grep для доступа к гораздо более конкретным результатам поиска в Linux.
grep примеры использования
В принципе для работы grep не обязательно указывать даже файл или директорию, но это крайне желательно, если Вы хотите найти всё быстрее и точнее. Например:
Найдет файлы с упоминанием меня любимого, если таковые есть. Точнее не файлы, а строки с упоминанием указанного слова, т.е в данном случае sonikelf. Здесь стоит упомянуть, что строкой grep считает все символы, находящиеся между двумя символами новой строки.
| grep sonikelf file.txt | поиск sonikelf в файле file.txt, с выводом полностью совпавшей строкой |
| grep -o sonikelf file.txt | поиск sonikelf в файле file.txt и вывод только совпавшего куска строки |
| grep -i sonikelf file.txt | игнорирование регистра при поиске |
| grep -bn sonikelf file.txt | показать строку (-n) и столбец (-b), где был найден sonikelf |
| grep -v sonikelf file.txt | инверсия поиска (найдет все строки, которые не совпадают с шаблоном sonikelf) |
| grep -A 3 sonikelf file.txt | вывод дополнительных трех строк, после совпавшей |
| grep -B 3 sonikelf file.txt | вывод дополнительных трех строк, перед совпавшей |
| grep -C 3 sonikelf file.txt | вывод три дополнительные строки перед и после совпавшей |
| grep -r sonikelf $HOME | рекурсивный поиск по директории $HOME и всем вложенным |
| grep -c sonikelf file.txt | подсчет совпадений |
| grep -L sonikelf *.txt | вывести список txt-файлов, которые не содержат sonikelf |
| grep -l sonikelf *.txt | вывести список txt-файлов, которые содержат sonikelf |
| grep -w sonikelf file.txt | совпадение только с полным словом sonikelf |
| grep -f sonikelfs.txt file.txt | поиск по нескольким sonikelf из файла sonikelfs.txt, шаблоны разделяются новой строкой |
| grep -I sonikelf file.txt | игнорирование бинарных файлов |
| grep -v -f file2 file1 > file3 | вывод строк, которые есть в file1 и нет в file2 |
| grep -in -e ‘python’ `find -type f` | рекурсивный поиск файлов, содержащих слово python с выводом номера строки и совпадений |
| grep -inc -e ‘test’ `find -type f` | grep -v :0 | рекурсивный поиск файлов, содержащих слово python с выводом количества совпадений |
| grep . *.py | вывод содержимого всех py-файлов, предваряя каждую строку именем файла |
| grep «Http404» apps/**/*.py | рекурсивный поиск упоминаний Http404 в директории apps в py-файлах |
ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ
С теорией покончено, теперь перейдем к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
ПОИСК ТЕКСТА В ФАЙЛАХ
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
ВЫВЕСТИ НЕСКОЛЬКО СТРОК
Например, мы хотим выбрать все ошибки из лог файла, но знаем что в следующей сточке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк, ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после нее.
Выведет целевую строку и 4 строчки до нее
Выведет по две строки с верху и снизу от вхождения.
РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ В GREP
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах grep. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
Поиск в конце строки, спецсимвол «$»:
Найдем все строки которые содержат цифры:
Вообще, регулярные выражения grep это очень обширная тема, в этой статье я лишь показал несколько примеров, чтобы дать вам понять что это. Как вы увидели, таким образом, поиск текста в файлах grep становиться еще гибче. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим их и пойдем дальше.
РЕКУРСИВНОЕ ИСПОЛЬЗОВАНИЕ GREP
Если вам нужно провести поиск текста grep в нескольких файлах, размещенных в одном каталоге или подкаталогах, например, в файлах конфигурации Apache — /etc/apache2/ — используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займется поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
В выводе вы получите:
Здесь перед найденной строкой указано имя файла в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
ПОИСК СЛОВ В GREP
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить grep искать по содержимому файлов в linux только те строки, которые выключают искомые слова с помощью опции -w:
ПОИСК ДВУХ СЛОВ
Можно искать по содержимому файла не одно слово, а целых несколько. Чтобы искать два разных слова используйте команду egrep:
КОЛИЧЕСТВО ВХОЖДЕНИЙ СТРОКИ
Утилита Grep может сообщить сколько раз определенная строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки в которой найдено вхождение, например:
Получим:
ИНВЕРТИРОВАННЫЙ ПОИСК В GREP
Команда grep linux может быть использована для поиска строк в файле Linux которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
ВЫВОД ИМЕНИ ФАЙЛА
Вы можете указать grep выводить только имя файла в котом было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
Расширенные регулярные выражения
Команду Grep можно также использовать с расширенным языком регулярных выражений при помощи флага «-E» или же вызывая команду «egrep» вместо «grep».
Эти команды открывают возможности «расширенных регулярных выражений». Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для выражения более сложных совпадений.
Группирование
Одна из простейших и полезнейших возможностей, которые открывают расширенные регулярные выражения, – это возможность группировать выражения и использовать их как единое целое.
Для группирования выражений используются круглые скобки. При необходимости использовать круглые скобки вне расширенных регулярных выражений, их можно «избежать» при помощи обратной косой
Приведенные выше выражения являются эквивалентами.
Чередование
Подобно тому, как квадратные скобки задают различные возможные варианты совпадения одного символа, чередование позволяет указать альтернативные совпадения для строк символов или наборов выражений.
Для обозначения чередования используется символ вертикальной черты «|». Чередование часто применяется в группировании для того, чтобы указать, что один из двух или более возможных вариантов должен рассматриваться как совпадение.
В данном примере нужно найти «GPL» или «General Public License»:
Чередование можно использовать для выбора между двумя и более вариантами; для этого нужно ввести остальные варианты в группу отбора, отделяя каждый при помощи символа вертикальной черты «|».
Кванторы
В расширенных регулярных выражениях существуют метасимволы, указывающие частоту повторения символа, подобно тому, как метасимвол «*» указывает на совпадения предыдущего символа или строки символов 0 или более раз.
Чтобы указать совпадение символа 0 или больше раз, можно использовать символ «?». Он сделает предыдущий символ или ряд символов, по сути, необязательными.
В данном примере при помощи внесения последовательности «copy» в факультативную группу выведены совпадения «copyright» и «right»:
Символ «+» ищет совпадения выражений 1 или больше раз. Он работает почти как символ «*», но при использовании «+» выражение должно совпасть хотя бы 1 раз.
Приведенное ниже выражение ищет совпадения строки «free» плюс 1 или больше символов, которые не являются пробельными:
Количество повторений совпадений
При необходимости указать количество повторения совпадений можно использовать фигурные скобки («{ }»). Эти символы используются для указания точного количества, диапазона, а также верхнего и нижнего предела количества совпадений выражения.
При необходимости найти все строки, что содержат сочетание трех гласных, можно использовать следующее выражение:
Назначение операторов find и grep
Команда find в Linux является оператором командной строки для работы с файлами в обход существующей иерархии. Она позволяет производить поиск файлов с использованием множества фильтров, а также выполнять некие действия над файлами после их успешного поиска. Среди критериев поиска файлов – практически все доступные атрибуты, от даты создания до разрешения.
Команда grep в Linux также относится к поисковым, но внутри файлов. Буквальный перевод команды – «глобальная печать регулярных выражений», но под печатью здесь понимается вывод результатов работы на устройство по умолчанию, каковым обычно является монитор. Обладая огромным потенциалом, оператор используется достаточно часто и позволяет производить поиск внутри одного или нескольких файлов по заданным фрагментам (шаблонам). Поскольку терминология в Linuxе существенно отличается от таковой в среде Windows, очень многие пользователи испытывают значительные трудности с использованием этих команд. Постараемся устранить этот недостаток.
Other options
| —line-buffered | Use line buffering on output. This can cause a performance penalty. |
| —mmap | If possible, use the mmap system call to read input, instead of the default read system call. In some situations, —mmap yields better performance. However, —mmap can cause undefined behavior (including core dumps) if an input file shrinks while grep is operating, or if an I/O error occurs. |
| -U, —binary | Treat the file(s) as binary. By default, under MS-DOS and MS-Windows, grep guesses the file type by looking at the contents of the first 32 KB read from the file. If grep decides the file is a text file, it strips the CR characters from the original file contents (to make regular expressions with ^ and $ work correctly). Specifying -U overrules this guesswork, causing all files to be read and passed to the matching mechanism verbatim; if the file is a text file with CR/LF pairs at the end of each line, this causes some regular expressions to fail. This option has no effect on platforms other than MS-DOS and MS-Windows. |
| -z, —null-data | Treat the input as a set of lines, each terminated by a zero byte (the ASCII NUL character) instead of a newline. Like the -Z or —null option, this option can be used with commands like sort -z to process arbitrary file names. |
Why do we use grep?
Grep is a command-line tool that Linux users use to search for strings of text. You can use it to search a file for a certain word or combination of words, or you can pipe the output of other Linux commands to grep, so grep can show you only the output that you need to see.
Let’s look at some really common examples. Say that you need to check the contents of a directory to see if a certain file exists there. That’s something you would use the “ls” command for.
But, to make this whole process of checking the directory’s contents even faster, you can pipe the output of the ls command to the grep command. Let’s look in our home directory for a folder called Documents.
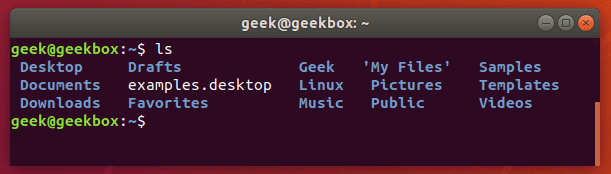
And now, let’s try checking the directory again, but this time using grep to check specifically for the Documents folder.
$ ls | grep Documents
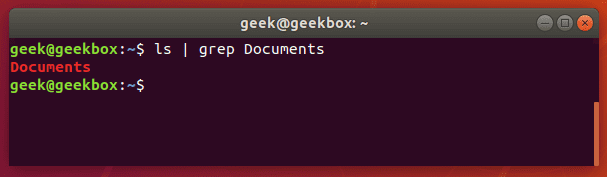
As you can see in the screenshot above, using the grep command saved us time by quickly isolating the word we searched for from the rest of the unnecessary output that the ls command produced.
If the Documents folder didn’t exist, grep wouldn’t return any output. So if grep returns nothing, that means that it couldn’t find the word you are searching for.
Checking for the given string in multiple files.
Syntax: grep "string" FILE_PATTERN
This is also a basic usage of grep command. For this example, let us copy the demo_file to demo_file1. The grep output will also include the file name in front of the line that matched the specific pattern as shown below. When the Linux shell sees the meta character, it does the expansion and gives all the files as input to grep.
$ cp demo_file demo_file1 $ grep "this" demo_* demo_file:this line is the 1st lower case line in this file. demo_file:Two lines above this line is empty. demo_file:And this is the last line. demo_file1:this line is the 1st lower case line in this file. demo_file1:Two lines above this line is empty. demo_file1:And this is the last line.
Регулярные выражения Linux
В регулярных выражениях могут использоваться два типа символов:
- обычные буквы;
- метасимволы.
Обычные символы — это буквы, цифры и знаки препинания, из которых состоят любые строки. Все тексты состоят из букв и вы можете использовать их в регулярных выражениях для поиска нужной позиции в тексте.
Метасимволы — это кое-что другое, именно они дают силу регулярным выражениям. С помощью метасимволов вы можете сделать намного больше чем поиск одного символа. Вы можете искать комбинации символов, использовать динамическое их количество и выбирать диапазоны. Все спецсимволы можно разделить на два типа, это символы замены, которые заменяют собой обычные символы, или операторы, которые указывают сколько раз может повторяться символ. Синтаксис регулярного выражения будет выглядеть таким образом:
обычный_символ спецсимвол_оператор
спецсимвол_замены спецсимвол_оператор
Если оператор не указать, то будет считаться, что символ обязательно должен встретится в строке один раз. Таких конструкций может быть много. Вот основные метасимволы, которые используют регулярные выражения bash:
- \ — с обратной косой черты начинаются буквенные спецсимволы, а также он используется если нужно использовать спецсимвол в виде какого-либо знака препинания;
- ^ — указывает на начало строки;
- $ — указывает на конец строки;
- * — указывает, что предыдущий символ может повторяться 0 или больше раз;
- + — указывает, что предыдущий символ должен повторится больше один или больше раз;
- ? — предыдущий символ может встречаться ноль или один раз;
- {n} — указывает сколько раз (n) нужно повторить предыдущий символ;
- {N,n} — предыдущий символ может повторяться от N до n раз;
- . — любой символ кроме перевода строки;
- — любой символ, указанный в скобках;
- х|у — символ x или символ y;
- — любой символ, кроме тех, что указаны в скобках;
- — любой символ из указанного диапазона;
- — любой символ, которого нет в диапазоне;
- \b — обозначает границу слова с пробелом;
- \B — обозначает что символ должен быть внутри слова, например, ux совпадет с uxb или tuxedo, но не совпадет с Linux;
- \d — означает, что символ — цифра;
- \D — нецифровой символ;
- \n — символ перевода строки;
- \s — один из символов пробела, пробел, табуляция и так далее;
- \S — любой символ кроме пробела;
- \t — символ табуляции;
- \v — символ вертикальной табуляции;
- \w — любой буквенный символ, включая подчеркивание;
- \W — любой буквенный символ, кроме подчеркивания;
- \uXXX — символ Unicdoe.
Важно отметить, что перед буквенными спецсимволами нужно использовать косую черту, чтобы указать, что дальше идет спецсимвол. Правильно и обратное, если вы хотите использовать спецсимвол, который применяется без косой черты в качестве обычного символа, то вам придется добавить косую черту
Например, вы хотите найти в тексте строку 1+ 2=3. Если вы используете эту строку в качестве регулярного выражения, то ничего не найдете, потому что система интерпретирует плюс как спецсимвол, который сообщает, что предыдущая единица должна повториться один или больше раз. Поэтому его нужно экранировать: 1 \+ 2 = 3. Без экранирования наше регулярное выражение соответствовало бы только строке 11=3 или 111=3 и так далее. Перед равно черту ставить не нужно, потому что это не спецсимвол.
Context line control
| -A NUM,—after-context=NUM | Print NUM lines of trailing context after matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -B NUM,—before-context=NUM | Print NUM lines of leading context before matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -C NUM, —NUM,—context=NUM | Print NUM lines of output context. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
Catch space or tab
As we mentioned earlier in our explanation of how to search for a string, you can wrap text inside quotes if it contains spaces. The same method will work for tabs, but we’ll explain how to put a tab in your grep command in a moment.
Put a space or multiple spaces inside quotes to have grep search for that character.
$ grep " " sample.txt
There are a few different ways you can search for a tab with grep, but most of the methods are experimental or can be inconsistent across different distributions.
The easiest way is to just search for the tab character itself, which you can produce by hitting ctrl+v on your keyboard, followed by tab.
Normally, pressing tab in a terminal window tells the terminal that you want to auto-complete a command, but pressing the ctrl+v combination beforehand will cause the tab character to be written out as you’d normally expect it to in a text editor.
$ grep " " sample.txt
Knowing this little trick is especially useful when greping through configuration files in Linux since tabs are frequently used to separate commands from their values.
Grep OR Operator
Use any one of the following 4 methods for grep OR. I prefer method number 3 mentioned below for grep OR operator.
1. Grep OR Using \|
If you use the grep command without any option, you need to use \| to separate multiple patterns for the or condition.
grep 'pattern1\|pattern2' filename
For example, grep either Tech or Sales from the employee.txt file. Without the back slash in front of the pipe, the following will not work.
$ grep 'Tech\|Sales' employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
2. Grep OR Using -E
grep -E option is for extended regexp. If you use the grep command with -E option, you just need to use | to separate multiple patterns for the or condition.
grep -E 'pattern1|pattern2' filename
For example, grep either Tech or Sales from the employee.txt file. Just use the | to separate multiple OR patterns.
$ grep -E 'Tech|Sales' employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
3. Grep OR Using egrep
egrep is exactly same as ‘grep -E’. So, use egrep (without any option) and separate multiple patterns for the or condition.
egrep 'pattern1|pattern2' filename
For example, grep either Tech or Sales from the employee.txt file. Just use the | to separate multiple OR patterns.
$ egrep 'Tech|Sales' employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
4. Grep OR Using grep -e
Using grep -e option you can pass only one parameter. Use multiple -e option in a single command to use multiple patterns for the or condition.
grep -e pattern1 -e pattern2 filename
For example, grep either Tech or Sales from the employee.txt file. Use multiple -e option with grep for the multiple OR patterns.
$ grep -e Tech -e Sales employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000







