Коэффициент корреляции
Содержание:
- Что такое корреляция простыми словами
- Предвзятость средств массовой информации
- Распространенные заблуждения
- Как рассчитать коэффициент корреляции в Excel
- Корреляция и диверсификация
- Как проводится корреляционный анализ в Excel
- Как вы можете рассчитать корреляцию с помощью Excel? — 2019
- 9.1.3. Простая линейная регрессия
- Обследование данных
- Примеры
- Задачи, виды и показатели корреляционно-регрессионного анализа
Что такое корреляция простыми словами
Не хочу вас сразу грузить формулами и расчётами, об этом поговорим ближе к концу. Давайте сначала разберемся, что по своей сути означает цифра коэффициента корреляции, которую вы можете встретить в какой-нибудь книге или статье.
Значение коэффициента может меняться от -1 до +1:

Если значение близко к единице или минус единице — значит два явления так или иначе сильно взаимосвязаны. Впрочем, причины этого не всегда очевидны — явление А может влиять на явление B, может быть наоборот. Нередко бывает, что существует явление C, которое приводит в движение А и В одновременно. В общем, природа корреляции — это уже второй вопрос, которым должны заниматься исследователи.
Околонулевые значения, в свою очередь, говорят об отсутствии какой-либо зависимости между явлениями. Нет конкретного предела, где заканчивается случайность и начинается взаимосвязь, все зависит от предмета исследования и количества данных. Навскидку, обычно при значениях от -0.3 до 0.3 можно говорить о том, что зависимость отсутствует.
При высокой положительной корреляции вслед за графиком А растёт и график B, и чем выше значение, тем слаженнее оба движутся. Для наглядности, вот как выглядит корреляция +1:
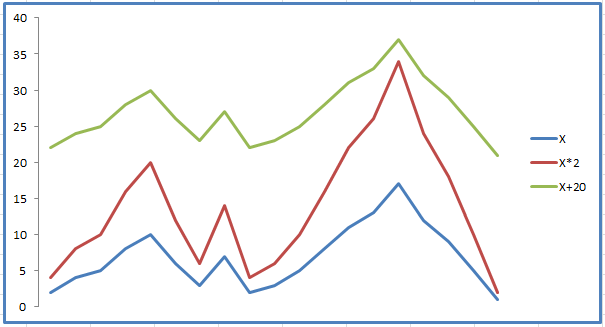
Движения графиков полностью повторяют друг друга, причем это как в случае простого добавления, так и с множителем.
При сильной отрицательной корреляции рост графика А приводит к падению графика B и наоборот. Вот так выглядит корреляция -1:

Движения графиков похожи на зеркальные отражения.
Коэффициент корреляции — удобный инструмент для анализа во многих сферах науки и жизни. Его легко рассчитать в Excel и применить, поэтому самая большая сложность в работе с ним — грамотно подобрать данные для расчёта. Основное правило — чем больше данных, тем лучше. Многие взаимосвязи проявляют себя лишь на длинной дистанции.
Также нужно следить за тем, чтобы найденные корреляции не были ложными.
Предвзятость средств массовой информации
Рассмотрим, как наличие корреляционной связи может быть неправильно истолковано. Группу британских студентов, отличающихся плохим поведением, опросили относительно того, курят ли их родители. Потом тест опубликовали в газете. Результат показал сильную корреляцию между курением родителей и правонарушениями их детей. Профессор, который проводил это исследование, даже предложил поместить на пачки сигарет предупреждение об этом. Однако существует целый ряд проблем с таким выводом. Во-первых, корреляция не показывает, какая из величин является независимой. Поэтому вполне можно предположить, что пагубная привычка родителей вызвана непослушанием детей. Во-вторых, нельзя с уверенностью сказать, что обе проблемы не появились из-за какого-то третьего фактора. Например, низкого дохода семей. Следует отметить эмоциональный аспект первоначальных выводов профессора, который проводил исследование. Он был ярым противником курения. Поэтому нет ничего удивительного в том, что он интерпретировал результаты своего исследования именно так.
Распространенные заблуждения
Корреляция и причинно-следственная связь
Традиционное изречение, что « корреляция не подразумевает причинной связи », означает, что корреляция не может использоваться сама по себе для вывода причинной связи между переменными. Это изречение не должно означать, что корреляции не могут указывать на потенциальное существование причинно-следственных связей. Однако причины, лежащие в основе корреляции, если таковые имеются, могут быть косвенными и неизвестными, а высокие корреляции также пересекаются с отношениями идентичности ( тавтологиями ), где не существует причинных процессов. Следовательно, корреляция между двумя переменными не является достаточным условием для установления причинно-следственной связи (в любом направлении).
Корреляция между возрастом и ростом у детей довольно прозрачна с точки зрения причинно-следственной связи, но корреляция между настроением и здоровьем людей менее очевидна. Приводит ли улучшение настроения к улучшению здоровья, или хорошее здоровье приводит к хорошему настроению, или и то, и другое? Или в основе обоих лежит какой-то другой фактор? Другими словами, корреляция может рассматриваться как свидетельство возможной причинной связи, но не может указывать на то, какой может быть причинная связь, если таковая имеется.
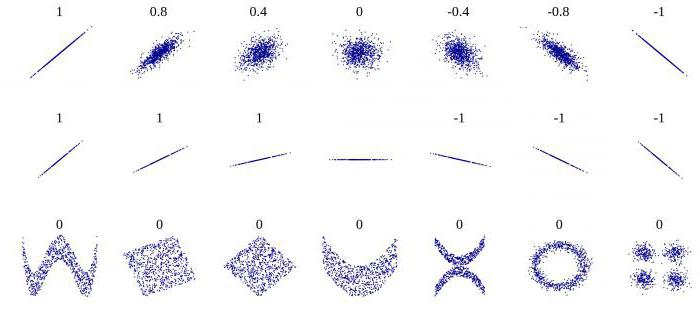
Простые линейные корреляции
Четыре набора данных с одинаковой корреляцией 0,816
Коэффициент корреляции Пирсона указывает на силу линейной связи между двумя переменными, но его значение, как правило, не полностью характеризует их взаимосвязь. В частности, если условное среднее из дано , обозначается , не является линейным в , коэффициент корреляции будет не в полной мере определить форму .
Y{\ displaystyle Y}Икс{\ displaystyle X}E(Y∣Икс){\ displaystyle \ operatorname {E} (Y \ mid X)}Икс{\ displaystyle X}E(Y∣Икс){\ displaystyle \ operatorname {E} (Y \ mid X)}
Прилегающие изображение показывает разброс участков из квартет энскомбы , набор из четырех различных пар переменных , созданный Фрэнсис Анскомбами . Четыре переменные имеют одинаковое среднее значение (7,5), дисперсию (4,12), корреляцию (0,816) и линию регрессии ( y = 3 + 0,5 x ). Однако, как видно на графиках, распределение переменных сильно отличается. Первый (вверху слева), кажется, распределен нормально и соответствует тому, что можно было бы ожидать, рассматривая две коррелированные переменные и следуя предположению о нормальности. Второй (вверху справа) не распространяется нормально; хотя можно наблюдать очевидную взаимосвязь между двумя переменными, она не является линейной. В этом случае коэффициент корреляции Пирсона не указывает на то, что существует точная функциональная связь: только степень, в которой эта связь может быть аппроксимирована линейной зависимостью. В третьем случае (внизу слева) линейная зависимость идеальна, за исключением одного выброса, который оказывает достаточное влияние, чтобы снизить коэффициент корреляции с 1 до 0,816. Наконец, четвертый пример (внизу справа) показывает другой пример, когда одного выброса достаточно для получения высокого коэффициента корреляции, даже если связь между двумя переменными не является линейной.
у{\ displaystyle y}
Эти примеры показывают, что коэффициент корреляции как сводная статистика не может заменить визуальный анализ данных. Иногда говорят, что примеры демонстрируют, что корреляция Пирсона предполагает, что данные следуют нормальному распределению , но это верно лишь отчасти. Корреляцию Пирсона можно точно рассчитать для любого распределения, имеющего конечную матрицу ковариаций , которая включает большинство распределений, встречающихся на практике. Однако коэффициент корреляции Пирсона (вместе с выборочным средним и дисперсией) является достаточной статистикой только в том случае, если данные взяты из многомерного нормального распределения. В результате коэффициент корреляции Пирсона полностью характеризует взаимосвязь между переменными тогда и только тогда, когда данные взяты из многомерного нормального распределения.
Как рассчитать коэффициент корреляции в Excel
В сегодняшней статье речь пойдет о том, как переменные могут быть связаны друг с другом. С помощью корреляции мы сможем определить, существует ли связь между первой и второй переменной. Надеюсь, это занятие покажется вам не менее увлекательным, чем предыдущие!
Корреляция измеряет мощность и направление связи между x и y. На рисунке представлены различные типы корреляции в виде графиков рассеяния упорядоченных пар (x, y). По традиции переменная х размещается на горизонтальной оси, а y — на вертикальной.
График А являет собой пример положительной линейной корреляции: при увеличении х также увеличивается у, причем линейно. График В показывает нам пример отрицательной линейной корреляции, на котором при увеличении х у линейно уменьшается. На графике С мы видим отсутствие корреляции между х и у. Эти переменные никоим образом не влияют друг на друга.
Наконец, график D — это пример нелинейных отношений между переменными. По мере увеличения х у сначала уменьшается, потом меняет направление и увеличивается.
Оставшаяся часть статьи посвящена линейным взаимосвязям между зависимой и независимой переменными.
Коэффициент корреляции
Коэффициент корреляции, r, предоставляет нам как силу, так и направление связи между независимой и зависимой переменными. Значения r находятся в диапазоне между — 1.0 и + 1.0. Когда r имеет положительное значение, связь между х и у является положительной (график A на рисунке), а когда значение r отрицательно, связь также отрицательна (график В). Коэффициент корреляции, близкий к нулевому значению, свидетельствует о том, что между х и у связи не существует график С).
Сила связи между х и у определяется близостью коэффициента корреляции к — 1.0 или +- 1.0. Изучите следующий рисунок.
График A показывает идеальную положительную корреляцию между х и у при r = + 1.0. График В — идеальная отрицательная корреляция между х и у при r = — 1.0. Графики С и D — примеры более слабых связей между зависимой и независимой переменными.
Коэффициент корреляции, r, определяет, как силу, так и направление связи между зависимой и независимой переменными. Значения r находятся в диапазоне от — 1.0 (сильная отрицательная связь) до + 1.0 (сильная положительная связь). При r= 0 между переменными х и у нет никакой связи.
Мы можем вычислить фактический коэффициент корреляции с помощью следующего уравнения:
Ну и ну! Я знаю, что выглядит это уравнение как страшное нагромождение непонятных символов, но прежде чем ударяться в панику, давайте применим к нему пример с экзаменационной оценкой. Допустим, я хочу определить, существует ли связь между количеством часов, посвященных студентом изучению статистики, и финальной экзаменационной оценкой. Таблица, представленная ниже, поможет нам разбить это уравнение на несколько несложных вычислений и сделать их более управляемыми.
Как видите, между числом часов, посвященных изучению предмета, и экзаменационной оценкой существует весьма сильная положительная корреляция. Преподаватели будут весьма рады узнать об этом.
Какова выгода устанавливать связь между подобными переменными? Отличный вопрос. Если обнаруживается, что связь существует, мы можем предугадать экзаменационные результаты на основе определенного количества часов, посвященных изучению предмета. Проще говоря, чем сильнее связь, тем точнее будет наше предсказание.
Использование Excel для вычисления коэффициентов корреляции
Я уверен, что, взглянув на эти ужасные вычисления коэффициентов корреляции, вы испытаете истинную радость, узнав, что программа Excel может выполнить за вас всю эту работу с помощью функции КОРРЕЛ со следующими характеристиками:
КОРРЕЛ (массив 1; массив 2),
массив 1 = диапазон данных для первой переменной,
массив 2 = диапазон данных для второй переменной.
Например, на рисунке показана функция КОРРЕЛ, используемая при вычислении коэффициента корреляции для примера с экзаменационной оценкой.
Корреляция и диверсификация
Как знания о корреляции активов могут помочь лучше вкладывать деньги? Думаю, вы все хорошо знакомы с золотым правилом инвестора — не клади все яйца в одну корзину. Речь, естественно, идёт о диверсификации инвестиционных активов в портфеле. Корреляция и диверсификация неразрывно связаны, что понятно даже из названия — английское diversify означает «разнообразить», а как коэффициент корреляции как раз показывает схожесть или различие двух явлений.
Другими словами, инвестировать в финансовые инструменты с высокой корреляцией не очень хорошо. Почему? Все просто — похожие активы плохо диверсифицируются. Вот пример портфеля двух активов с корреляцией +1:
Как видите, график портфеля во всех деталях повторяет графики каждого из активов — рост и падение обоих активов синхронны. Диверсификация в теории должна снижать инвестиционные риски за счёт того, что убытки одного актива перекрываются за счёт прибыли другого, но здесь этого не происходит совершенно. Все показатели просто усредняются:
Портфель даёт небольшой выигрыш в снижении рисков — но только по сравнению с более доходным Активом 1. А так, никаких преимуществ по сути нет, нам лучше просто вложить все деньги в Актив 1 и не париться.
А вот пример портфеля двух активов с корреляцией близкой к 0:
Где-то графики следуют друг за другом, где-то в противоположных направлениях, какой-либо однозначной связи не наблюдается. И вот здесь диверсификация уже работает:
Мы видим заметное снижение СКО, а значит портфель будет менее волатильным и более стабильно расти. Также видим небольшое снижение максимальной просадки, особенно если сравнивать с Активом 1. Инвестиционные инструменты без корреляции достаточно часто встречаются и из них имеет смысл составлять портфель.
Впрочем, это не предел. Наиболее эффективный инвестиционный портфель можно получить, используя активы с корреляцией -1:
Уже знакомое вам «зеркало» позволяет довести показатели риска портфеля до минимальных:
Несмотря на то, что каждый из активов обладает определенным риском, портфель получился фактически безрисковым. Какая-то магия, не правда ли? Очень жаль, но на практике такого не бывает, иначе инвестирование было бы слишком лёгким занятием.
Как проводится корреляционный анализ в Excel
Суть данного анализа сводится к выявлению зависимостей между различными факторами, представленными в таблицах. Таким образом можно определить как повлияет уменьшение или увеличение определенных показателей на исследуемые данные.
Если была выявлена зависимость, то определяется уже коэффициент корреляции. Коэффициент будет варьироваться в значениях от -1 до +1. При положительной корреляции, увеличение одного показателя повлечет за собой увеличение другого. Соответственно при отрицательной будет уменьшение. Чем больше значение корреляции, тем сильнее оказываемое влияние.
Для примера возьмем таблицу, где представлена прямая зависимость одних показателей от других. Например, зарплата сотрудников и величина прибыли компании. Далее рассмотрим два способа реализации корреляционного анализа на примере этой таблицы.
Вариант 1: Вызов через Мастер функций
В отличии от некоторых других типов анализов, корреляционный анализ можно вызвать с помощью функций. За него отвечает функция КОРРЕЛ вида: КОРРЕЛ(массив1;массив2):
- Выделите ячейку в таблицу, куда хотите вставить полученный результат. В строке ввода формул воспользуйтесь значком функции.

Откроется окно мастера функций. В поле “Категория” нужно поставить значение “Полный алфавитный перечень”, чтобы отобразились все доступные для применения функции. Там отыщите пункт “КОРРЕЛ” нажмите по нему и затем на кнопку “Ок”.
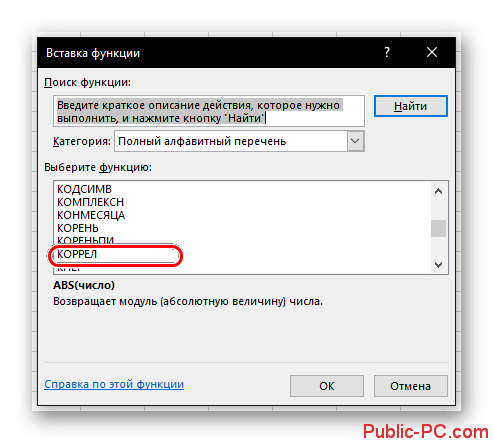
Вам потребуется заполните в окошке настройки функции два поля, то есть указать два массива ячеек. В первый массив укажите номера ячеек, зависимость которых следует определить. Для рассматриваемой таблицы это будет массив столбца дохода компании. Номера можно вписать вручную или выделить их, кликнув по иконке таблицы в поле.
Во втором же массиве потребуется указать перечень ячеек, которые предположительно должны оказывать влияние на первый массив. В рассматриваемой таблице это величина зарплат сотрудников.
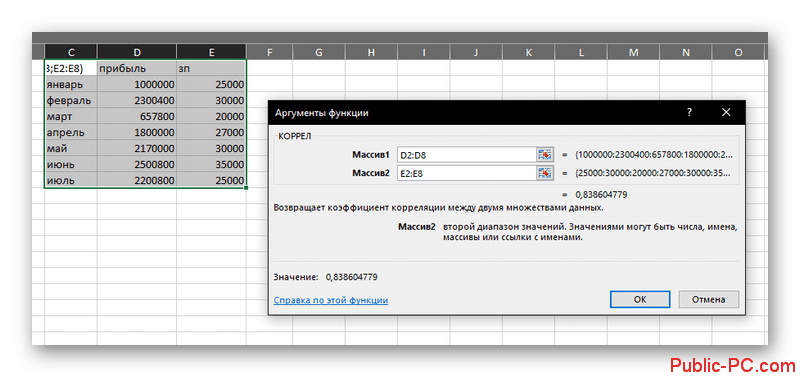
Закончив с заполнением нажмите кнопку “Ок”. Подсчет будет произведен автоматически и выведен в указанной ранее ячейке.
Если полученный коэффициент оказался больше +/-0.5, то это значит, что одна величина сильно зависима от другой.

Вариант 2: Применение пакета анализа
Вы можете использовать уже заданный шаблон корреляционного анализа, используя один из представленных пакетов анализа. По умолчанию пакеты анализа в Excel отключены, поэтому вам потребуется их включать отдельно.
- Перейдите во вкладку “Файл”, что расположена в верхней части окна.
В левой части переключитесь в раздел “Параметры”.
Откройте подраздел “Надстройки”, что находятся в левой части окна с параметрами.
У строки “Управление”, что расположена в нижней части открывшегося окна, установите значение “Надстройки Excel”. Нажмите “Перейти”, чтобы увидеть перечень доступных надстроек.
В открывшемся окне установите галочку у пункта “Пакет анализа” и нажмите “Ок”. После этого у вас должны появится дополнительные инструменты в верхней панели Excel.
Нужные нам инструменты расположена во вклакде “Данные”. Там должен будет появится дополнительный блок инструментов — “Анализ”. Воспользуйтесь в нем единственным инструментом — “Анализом данных”.
Открывается список с различными вариантами анализа данных. Укажите пункт “Корреляция”. Нажмите “Ок” для применения.
В открывшемся окошке настройки анализа уже потребуется заполнить только поле “Входной интервал”. Туда добавляется сразу два массива. В нашем случае это столбцы с зарплатой и доходом фирмы.
В блоке ниже можно указать, куда будет выводится результат. По умолчанию он выводит на новый рабочий лист, но вы можете настроить вывод в новую книгу или в определенных ячейках на текущем листе. Нажмите для применения и расчетов.
В итоге вы получите тот же результат, что и в первом способе. Единственное, в некоторых таблицах, при обработке большего количества данных значений может быть гораздо больше (в основном носят вспомогательный характер).
Первый рассмотренный нами способ подойдет для большинства таблиц, в то время как второй больше подходит для таблиц с большим перечнем данных, где еще желательно отследить логику проводимого анализа.
Как вы можете рассчитать корреляцию с помощью Excel? — 2019
a:
Корреляция измеряет линейную зависимость двух переменных. Измеряя и связывая дисперсию каждой переменной, корреляция дает представление о силе взаимосвязи. Или, говоря иначе, корреляция отвечает на вопрос: сколько переменная A (независимая переменная) объясняет переменную B (зависимую переменную)?
Формула корреляции
Корреляция объединяет несколько важных и связанных статистических понятий, а именно дисперсию и стандартное отклонение. Разница — дисперсия переменной вокруг среднего, а стандартное отклонение — квадратный корень дисперсии.
Формула:
Поскольку корреляция требует оценки линейной зависимости двух переменных, то, что действительно необходимо, — это выяснить, какая сумма ковариации этих двух переменных и в какой степени такая ковариация отраженные стандартными отклонениями каждой переменной в отдельности.
Общие ошибки с корреляцией
Самая распространенная ошибка — предполагать, что корреляция, приближающаяся +/- 1, статистически значима. Считывание, приближающееся +/- 1, безусловно увеличивает шансы на фактическую статистическую значимость, но без дальнейшего тестирования это невозможно узнать.
Статистическое тестирование корреляции может усложняться по ряду причин; это совсем не так просто. Критическое предположение о корреляции состоит в том, что переменные независимы и связь между ними является линейной.
Вторая наиболее распространенная ошибка — забыть нормализовать данные в единую единицу. Если вычислять корреляцию по двум бетам, то единицы уже нормализованы: сама бета является единицей
Однако, если вы хотите скорректировать акции, важно, чтобы вы нормализовали их в процентном отношении, а не изменяли цены. Это происходит слишком часто, даже среди профессионалов в области инвестиций
Для корреляции цен на акции вы, по сути, задаете два вопроса: каково возвращение за определенное количество периодов и как этот доход коррелирует с возвратом другой безопасности за тот же период? Это также связано с тем, что корреляция цен на акции затруднена: две ценные бумаги могут иметь высокую корреляцию, если доход составляет ежедневно процентов за последние 52 недели, но низкая корреляция, если доход ежемесячно > изменения за последние 52 недели. Какая из них лучше»? На самом деле нет идеального ответа, и это зависит от цели теста. ( Улучшите свои навыки excel, пройдя курс обучения Excel в Академии Excel. ) Поиск корреляции в Excel
Существует несколько методов расчета корреляции в Excel
Самый простой способ — получить два набора данных и использовать встроенную формулу корреляции:
Это удобный способ расчета корреляции между двумя наборами данных. Но что, если вы хотите создать корреляционную матрицу во множестве наборов данных? Для этого вам нужно использовать плагин анализа данных Excel. Плагин можно найти на вкладке «Данные» в разделе «Анализ».
Выберите таблицу возвратов. В этом случае наши столбцы имеют названия, поэтому мы хотим установить флажок «Ярлыки в первой строке», поэтому Excel знает, как обрабатывать их как заголовки. Затем вы можете выбрать вывод на том же листе или на новом листе.
Как только вы нажмете enter, данные будут автоматически сделаны. Вы можете добавить текст и условное форматирование, чтобы очистить результат.
9.1.3. Простая линейная регрессия
Применение линейного регрессионного анализа имеет специфические черты по сравнению с другими методами обработки данных. Его непосредственное употребление ограничено, в основном, задачами о предсказании значений зависимой переменной по известным значениям аргумента (или аргументов), что в психологии задача не слишком востребованная. Однако, во-первых, линейная регрессия входит как часть во многие другие методы (например, анализ медиации и модерации, о которых речь пойдет в следующей главе), и, во-вторых, служит простым примером отыскания наилучших параметров для модели определенного типа, и психологу полезно понимать суть этого метода. Качество каждого набора параметров, а затем и модели в целом, оценивается процентом дисперсии, который остался вне предсказаний, сделанных моделью по данным значениям аргументов. Замечательным результатом для читателя будет здесь улавливание аналогий с двухфакторным дисперсионным анализом.
Обследование данных
Когда вы сталкиваетесь с новым набором данных, первая задача состоит в том, чтобы его обследовать с целью понять, что именно он содержит.
Файл all-london-2012-athletes.tsv достаточно небольшой. Мы можем обследовать данные при помощи pandas, как мы делали в первой серии постов «Python, исследование данных и выборы», воспользовавшись функцией :
Если выполнить этот пример в консоли интерпретатора Python либо в блокноте Jupyter, то вы должны увидеть следующий ниже результат:
Столбцы данных (нам повезло, что они ясно озаглавлены) содержат следующую информацию:
-
ФИО атлета
-
страна, за которую он выступает
-
возраст, лет
-
рост, см.
-
вес, кг.
-
пол «М» или «Ж»
-
дата рождения в виде строки
-
место рождения в виде строки (со страной)
-
число выигранных золотых медалей
-
число выигранных серебряных медалей
-
число выигранных бронзовых медалей
-
всего выигранных золотых, серебряных и бронзовых медалей
-
вид спорта, в котором он соревновался
-
состязание в виде списка, разделенного запятыми
Даже с учетом того, что данные четко озаглавлены, очевидно присутствие пустых мест в столбцах с ростом, весом и местом рождения
При наличии таких данных следует проявлять осторожность, чтобы они не сбили с толку
Визуализация данных
В первую очередь мы рассмотрим разброс роста спортсменов на Олимпийских играх 2012 г. в Лондоне. Изобразим эти значения роста в виде гистограммы, чтобы увидеть характер распределения данных, не забыв сначала отфильтровать пропущенные значения:
Этот пример сгенерирует следующую ниже гистограмму:
Как мы и ожидали, данные приближенно нормально распределены. Средний рост спортсменов составляет примерно 177 см. Теперь посмотрим на распределение веса олимпийских спортсменов:
Приведенный выше пример сгенерирует следующую ниже гистограмму:
Данные показывают четко выраженную асимметрию. Хвост с правой стороны намного длиннее, чем с левой, и поэтому мы говорим, что асимметрия — положительная. Мы можем оценить асимметрию данных количественно при помощи функции библиотеки pandas :
К счастью, эта асимметрия может быть эффективным образом смягчена путем взятия логарифма веса при помощи функции библиотеки numpy :
Этот пример сгенерирует следующую ниже гистограмму:
Теперь данные намного ближе к нормальному распределению. Из этого следует, что вес распределяется согласно логнормальному распределению.
Примеры
Допустим, в каком-то эксперименте в равные промежутки времени измеряют две величины, X и Y. Если их значения меняются, как на этом графике, то это полностью коррелированные величины с
коэффициентом корреляции, равным +1.
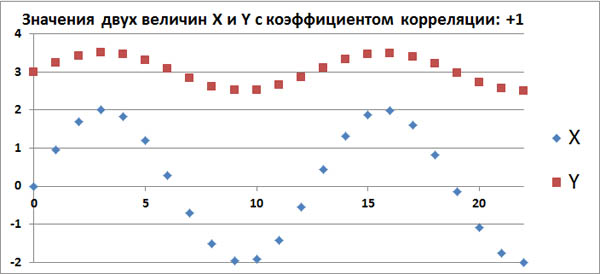
Этот факт говорит о том, что между величинами X и Y имеется строгая функциональная зависимость: Y=f(X).

Допустим, в каком-то эксперименте в равные промежутки времени измеряют две величины, X и Y. Если их значения меняются, как на следующем графике, то это полностью антикоррелированные величины
с коэффициентом корреляции, равным -1.

Этот факт также говорит о том, что между величинами X и Y имеется какая-то строгая функциональная зависимость: Y=g(X).

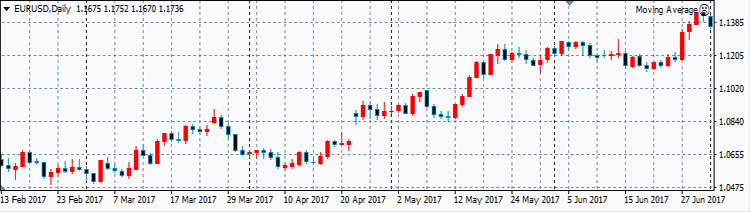
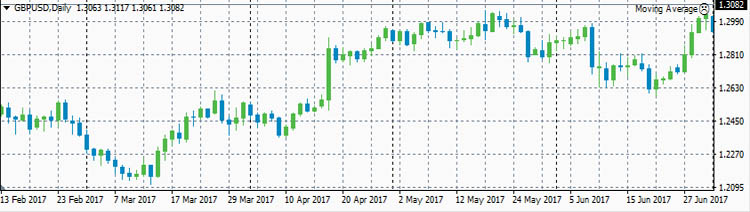
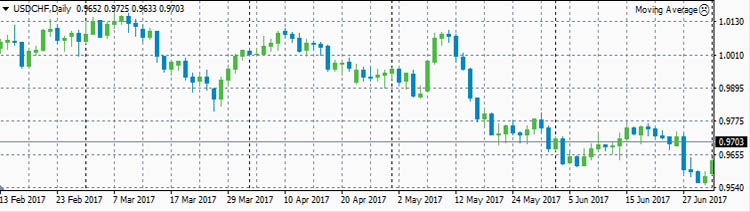
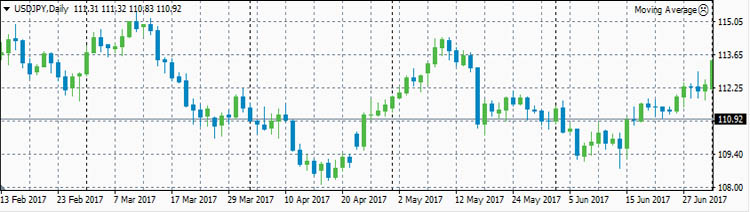
Теперь рассмотрим реальные цены. Для примера рассмотрим коэффициенты корреляции между ценами валютной пары EURUSD и ценами валютных пар GBPUSD, USDCHF и USDJPY. Для расчета возьмем дневные графики за
первую половину 2017 года.
EURUSD
GBPUSD
USDCHF
USDJPY
Расчеты, сделанные по ценам закрытия тайм-фреймов дают следующие коэффициенты корреляции за полгода:
- ρ(eurusd,gbpusd)=0.8030
- ρ(eurusd,usdchf)=-0.9598
- ρ(eurusd,usdjpy)=-0.4802
Эти коэффициенты корреляции достаточно ожидаемые.
Достаточно сильная корреляция между EURUSD и GBPUSD объясняется достаточно сильными связями экономики ЕвроЗоны и экономики Британии. Очень сильная антикорреляция между EURUSD и USDCHF объясняется еще
более сильной связью между экономиками ЕвроЗоны и Швейцарии. А знак минус получился потому что в валютной паре USDCHF швейцарский франк стоит в знаменателе, в то время как в валютной паре EURUSD евро
стоит в числителе.
Интересно посмотреть не только коэффициенты корреляции разных валютных пар, но и то, как эти коэффициенты изменяются со временем. Для этого возьмем внутри полугодового периода трехмесячный период и
посмотрим, как меняется коэффициент корреляции, если сдвигать этот трехмесячный период от начала полугодового периода до его конца. Всего за полгода будет 65 таких сдвижек.

В начале 2017 года корреляция между EURUSD и GBPUSD была небольшой и она даже немного уменьшалась. Но в середине полугодия корреляция между евро и фунтом усилилась. Таким образом, в определенное время
фунт может не слишком хорошо коррелировать с евро.
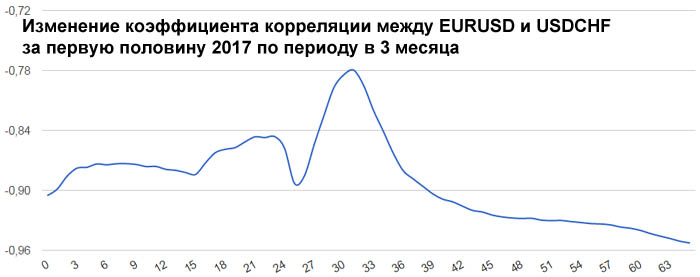
А вот в первую половину 2017 года швейцарский франк оказался привязанным к евро очень сильно. Коэффициент корреляции менялся в пределах от -0.96 до -0.78. Это и понятно, ведь Швейцария со всех сторон
окружена ЕвроЗоной. Поэтому её экономика должна быть сильно связана с экономикой ЕвроЗоны. Гораздо сильнее, чем британская экономика с экономикой ЕвроЗоны.
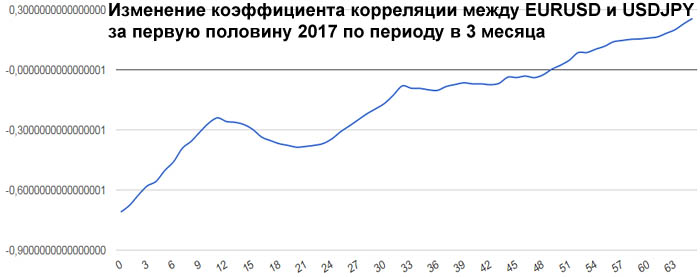
А вот что касается евро и йены, то тут ситуация самая интересная. В начале первого полугодия 2017 года была антикорреляция выше средней, примерно -0.71. Потом эта антикорреляция исчезла до нуля. Но на
этом изменения коэффициента корреляции не остановились. Коэффициент корреляции вырос до +0.2564. Так как евро в валютной паре EURUSD находится в числителе, а йена в валютной паре USDJPY находится в
знаменателе, то получается, что в начале года евро и йена сильно коррелировали, а к середине года стали слегка антикоррелировать.
Задачи, виды и показатели корреляционно-регрессионного анализа
Задачи КРА заключаются в:
- идентификации наиболее значимых факторов влияния на конкретный показатель деятельности предприятия;
- количественном измерении тесноты выявленных связей между показателями;
- определении неизвестных причин возникновения связей;
- всесторонней оценке факторов, которые признаны наиболее важными для рассматриваемого показателя;
- выведении формулы уравнения регрессии;
- составлении прогноза возможного результата деятельности при изменении ключевых связанных факторов с учетом возможного влияния других факторных признаков.
КРА подразумевает использование нескольких видов корреляционных и регрессионных методов. Зависимости выявляются при помощи корреляций таких типов:
- парная, если связь устанавливается с участием двух признаков;
- частная – взаимосвязь оценивается между искомым показателем и одним из ключевых факторов, при этом условием задается постоянное значение комплекса других факторов (то есть числовое выражение всех остальных факторов в любых ситуациях будет приниматься за определенную неизменную величину);
- множественная – основу исследования составляет влияние на показатель деятельности не одного фактора, а сразу нескольких критериев (двух и более).
СПРАВОЧНО! Выявленные показатели степени тесноты связей отражаются коэффициентом корреляции.
На выбор коэффициента влияет шкала измерения признаков:
- Шкала номинальная, которая предназначена для приведения описательных характеристик объектов.
- Шкала ординальная нужна для вычисления степени упорядоченности объектов в привязке к одному и более признакам.
- Шкала количественная используется для отражения количественных значений показателей.
Регрессионный анализ пользуется методом наименьших квадратов. Регрессия может быть линейной и множественной. Линейный тип предполагает модель из связей между двумя параметрами. Например, при наличии таких двух критериев, как урожайность клубники и полив, понятно, что именно объем поступающей влаги будет влиять на объем выращенной и собранной клубники. Если полив будет чрезмерным, то урожай пропадет. Урожайность же клубники никак не может воздействовать на систему полива.
Множественная регрессия учитывает более двух факторов одновременно. В случае с клубникой при оценке ее урожайности могут использоваться факторы полива, плодородности почвы, температурного режима, отсутствия слизняков, сортовые особенности, своевременность внесения удобрений. Все перечисленные показатели в совокупности оказывают комплексное воздействие на искомое значение – урожайность ягод.
Система показателей анализа формируется критериями классификации. Например, при экстенсивном типе развития бизнеса в качестве показателей могут выступать такие факторы:
- количество сотрудников;
- число заключенных договоров за отчетный период;
- посевные площади;
- прирост поголовья скота;
- расширение дилерской сети;
- объем основных фондов.
При интенсивном типе развития могут применяться следующие показатели:
- производительность труда;
- рентабельность;
- урожайность;
- фондоотдача;
- ликвидность;
- средний объем поставок в отчетном периоде по одному договору.







