Совет №7
Содержание:
- Why is the robots meta tag important for SEO?
- The Effect of NOINDEX,NOFOLLOW
- Which search engine supports which robots meta tag values?
- Why Is Robots.txt Important?
- Что такое meta name robots?
- How do search engines interpret conflicting directives?
- Conflicting parameters, and robots.txt files
- Атрибут rel=“nofollow”
- How to avoid crawlability and (de)indexation mistakes
- Другие полезные мета-теги
- Польза метатега robots и X-Robots-Tag для SEO
- Популярные статьи
- How Can I Combine Noindex and Disallow?
- Причины для запрета попадания пагинации в индекс
- What Is Robots.txt?
- Утекает ли вес ссылки через nofollow?
- Список параметров мета-тега name robots:
- Use topic properties to override the default value for some pages
- Директивы Meta Robots и какие поисковые системы их учитывают
- Test robots.txt using Search Console
- How to Set Up Robots Meta Tags and X‑Robots-Tag
- Влияние внутренних ссылок на индексацию сайта
Why is the robots meta tag important for SEO?
The meta robots tag is commonly used to prevent pages showing up in search results, although it does have other uses (more on those later).
There are various types of content that you might want to prevent search engines from indexing:
- Thin pages with little or no value for the user;
- Pages in the staging environment;
- Admin and thank-you pages;
- Internal search results;
- PPC landing pages;
- Pages about upcoming promotions, contests or product launches;
- Duplicate content (use canonical tags to suggest the best version for indexing);
Generally, the bigger your website is, the more you’ll deal with managing crawlability and indexation. You also want Google and other search engines to crawl and index your pages as efficiently as possible. Correctly combining page-level directives with robots.txt and sitemaps is crucial for SEO.
The Effect of NOINDEX,NOFOLLOW
The NOINDEX value tells search engines NOT to index this page, so basically this page should not show up in search results.
The NOFOLLOW value tells search engines NOT to follow (discover) the pages that are LINKED TO on this page.
Sometimes developers will add the NOINDEX,NOFOLLOW meta robots tag on development websites, so that search engines don’t accidentally start sending traffic to a website that is still under construction.
Or you might have your current (live) website on www.example.com, but you also keep a development copy on www.dev.example.com/. In this case it is advisable to noindex,nofollow the Dev version, so as to avoid many potential issues.
What often happens is that people will accidentally add this tag to live websites, forget to add it to development copies, or worse of all: forget to remove it from live websites after going live.
Yes, the same results and issues can arise from a poor robots.txt file in the root of a website, but that’s beyond the topic of this post.
Which search engine supports which robots meta tag values?
This table shows which search engines support which values. Note that the documentation provided by some search engines is sparse, so there are many unknowns.
| Robots value | Yahoo | Bing | Ask | Baidu | Yandex | |
|---|---|---|---|---|---|---|
| Indexing controls | ||||||
| index | Y* | Y* | Y* | ? | Y | Y |
| noindex | Y | Y | Y | ? | Y | Y |
| noimageindex | Y | N | N | ? | N | N |
| Whether links should be followed | ||||||
| follow | Y* | Y* | Y* | ? | Y | Y |
| nofollow | Y | Y | Y | ? | Y | Y |
| none | Y | ? | ? | ? | N | Y |
| all | Y | ? | ? | ? | N | Y |
| Snippet/preview controls | ||||||
| noarchive | Y | Y | Y | ? | Y | Y |
| nocache | N | N | Y | ? | N | N |
| nosnippet | Y | N | Y | ? | N | N |
| nositelinkssearchbox | Y | N | N | N | N | N |
| nopagereadaloud | Y | N | N | N | N | N |
| notranslate | Y | N | N | ? | N | N |
| max-snippet: | Y | Y | N | N | N | N |
| max-video-preview: | Y | Y | N | N | N | N |
| max-image-preview: | Y | Y | N | N | N | N |
| Miscellaneous | ||||||
| rating | Y | N | N | N | N | N |
| unavailable_after | Y | N | N | ? | N | N |
| noodp | N | Y** | Y** | ? | N | N |
| noydir | N | Y** | N | ? | N | N |
| noyaca | N | N | N | N | N | Y |
* Most search engines have no specific documentation for this, but we’re assuming that support for excluding parameters (e.g., ) implies support for the positive equivalent (e.g., ).** Whilst the noodp and noydir attributes may still be ‘supported’, these directories no longer exist, and it’s likely that these values do nothing.
Why Is Robots.txt Important?
I can’t tell how many clients come to me after a website migration or launching a new website and ask me: Why isn’t my site ranking after months of work?
I’d say 60% of the reason is that the robots.txt file wasn’t updated correctly.
Meaning, your robots.txt file still looks like this:
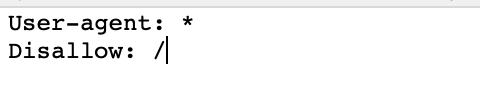
This will block all web crawlers are visiting your site.
Another reason robots.txt is important is that Google has this thing called a crawl budget.
Google states:
Advertisement
Continue Reading Below
So, if you have a big site with low-quality pages that you don’t want Google to crawl, you can tell Google to “Disallow” them in your robots.txt file.
This would free up your crawl budget to only crawl the high-quality pages you want Google to rank you for.
There are no hard and fast rules for robots.txt files…yet.
Google announced a proposal in July 2019 to begin implementing certain standards, but for now, I’m following the best practices I’ve done for the past few years.
Что такое meta name robots?
Прошу не путать с robots.txt, так как это совершенно разные файлы. Meta robots необходим, а Robots.txt призван для того чтобы создавать правила индексирования страниц для поисковых роботов.
Чтоб было нагляднее давайте разберем на примере:
Это пример файла robots.txt
Читайте в нашем блоге: Как проиндексировать сайт в Яндексе и Google?
Кстати, совсем недавно написал полноценную статью про правильную настройку robots.txt
Вот это пример мета-тега robots с атрибутами name и content
Как вы видете синтаксис довольно прост + параметры данного тега нечувствительны к регистру. Можно написать и в таком формате
В принципе синтаксис мы уже увидели. Данный тег должен располагаться в разделе <head> тут</head> и нигде больше! Но использовать данный тег можно несколько раз на странице.
How do search engines interpret conflicting directives?
As you can imagine, when you start stacking directives, it’s easy to mess up. If a scenario presents itself where there are conflicting directives, Google will default to the most restrictive one.
Take for example the following directives:
Verdict: Google will err on the side of caution and not index the page.
But, the way conflicting directives are interpreted can differ among search engines. Let’s take another example:
Google will not index this page, but Yandex will do the exact opposite and index it.
So keep this in mind, and make sure that your robots directives work right for the search engines that are important to you.
Conflicting parameters, and robots.txt files
It’s important to remember that meta robots tags work differently to instructions in your robots.txt file, and that conflicting rules may cause unexpected behaviors. For example, search engines won’t be able to see your tags if the page is blocked via .
You should also take care to avoid setting conflicting values in your meta robots tag (such as using both and parameters) – particularly if you’re setting different rules for different search engines. In cases of conflict, the most restrictive interpretation is usually chosen (i.e., “don’t show” usually beats “show”).
Adding a or to a post or page is a breeze if you’re on WordPress. Read how to use Yoast SEO to keep a post out of the search results.
Атрибут rel=“nofollow”
Что такое атрибут rel=“nofollow”
rel=“nofollow” — это атрибут ссылки <a></a>, который закрывает от поисковых роботов определенные ссылки, во избежание их индексации.
Атрибут rel=“nofollow” используется в разметке в таком виде:
<a href="http://mysite.com/" rel="nofollow">название ссылки</a>
Случаи использования rel=“nofollow”
- закрытие внешних ссылок или крауд-ссылок, когда вы не можете отвечать за содержание и надежность контента;
- закрытие внутренних ссылок служебных страниц, которые предназначены для регистрации или входа в личный профиль;
- закрытие проплаченных рекламных ссылок с атрибутом rel=”sponsored”, что убережет ваш сайт от возможных санкций со стороны поисковых систем.
В описанных случаях лучше скрывать ссылки от роботов и грамотно распределять ссылочный вес на сайте, что поможет сэкономить им краулинговый бюджет.
Краулинговый бюджет — это определенное количество страниц на сайте, с которым поисковые роботы могут справится за одну проверку на ресурсе.
Какой вес у ссылки с атрибутом rel=“nofollow”?
Весом ссылки называют относительный показатель, который влияет на ранжирование сайта в поисковой выдаче. Чем выше вес, тем приоритетнее ссылка для роботов.
Нужно понимать что ссылка по факту будет просмотрена, но будет иметь гораздо меньше веса, сравнительно с остальными. Этот факт говорит нам что на ранжирование страниц, ссылка с данным атрибутом, практически не повлияет.
Исключения есть. Это случаи когда мы ссылаемся на социальные сети, такие как: Twitter и Facebook. Google попросту игнорирует атрибут rel=“nofollow” и вносит в общий index.
Детальнее об этом вы можете прочитать в официальной документации от Google и Yandex:
https://support.google.com/webmasters/answer/96569https://yandex.ru/support/webmaster/controlling-robot/html.xml
How to avoid crawlability and (de)indexation mistakes
You want to show all valuable pages, avoid duplicate content, issues and keep specific pages out of the index. If you manage a huge website then crawl budget management is another thing to pay attention to.
Let’s have a look at the most common mistakes people make regarding robots directives.
Mistake #1: Adding noindex directives to pages disallowed in robots.txt
Never disallow crawling of content that you’re trying to get deindexed in robots.txt. Doing so prevents search engines from recrawling the page and discovering the noindex directive.
If you feel you may have made that mistake in the past, crawl your site with Ahrefs Site Audit. Look for pages with “Noindex page receives organic traffic” errors.

Noindexed pages that receive organic traffic are clearly still indexed. If you didn’t add the noindex tag recently, chances are this is due to a crawl block in your robots.txt file. Check for issues and fix them as appropriate.
Mistake #2: Bad sitemaps management
If you’re trying to get content deindexed using a meta robots tag or x‑robots-tag, don’t remove it from your sitemap until it’s been successfully deindexed. Otherwise, Google may be slower to recrawl the page.
To potentially speed up the deindexing process further, set the lastmod date in your sitemap to the date you added the noindex tag. This encourages recrawling and reprocessing.
Sidenote. John is talking about 404 pages here. That said, we’re assuming that this also makes sense for other changes like when you add or remove a noindex directive.
IMPORTANT NOTE
Don’t include noindexed pages in your sitemap in the long-term. Once content has been deindexed, remove it from your sitemap.
If you’re worried that old, successfully deindexed content may still exist in your sitemap, check the “Noindex page sitemap” error in Ahrefs Site Audit.

Mistake #3: Not removing noindex directives from the production environment
Preventing robots from crawling and indexing anything in the staging environment is a good practice. However, it sometimes gets pushed into production, forgotten, and your organic traffic plunges.
Even worse, the organic traffic drop might not be that noticeable if you’re involved in a site migration using 301 redirects. If the new URLs contain the noindex directive or are disallowed in robots.txt, you’ll still receive organic traffic from the old ones for some time. It can take Google up to a few weeks to deindex the old URLs.
Whenever there are such changes on your website, keep an eye on the “Noindex page” warnings in Ahrefs Site Audit:

To help prevent similar issues in the future, enrich the dev team’s checklist with instructions for removing disallow rules from robots.txt and noindex directives before pushing to production.
Mistake #4: Adding “secret” URLs to robots.txt instead of noindexing them
Developers often try to hide pages about upcoming promotions, discounts, or product launches by disallowing access to them in the site’s robots.txt file. This is bad practice because humans can still view a robots.txt file. As such, these pages are easily leaked.
Fix this by keeping “secret” pages out of robots.txt and noindexing them instead.
Другие полезные мета-теги
Ниже я приведу еще несколько мета-тегов, которые напрямую не влияют на индексацию и ранжирование страниц, но их тоже важно знать специалисту по SEO
Мета-тег Viewport
Синтаксис
<meta name="viewport" content="width=device-width, initial-scale=1" />
Тег должен находиться внутри контейнера <head>…</head> в любом месте. Актуальность тега возросла с переходом значительной части аудитории в Mobile. В случае применения адаптивной верстки, наличие этого тега позволяет правильно учитывать размер используемого устройства (ПК, планшет, смартфон).
Значение адаптирует ширину окна просмотра к экрану устройства. Значение обеспечивает соотношение 1:1 между пикселями CSS и независимыми пикселями устройства.
В случае отсутствия этого тега страница будет отображаться как на десктопе, даже если адаптивная верстка настроена корректно. Поэтому при анализе соответствия сайта требованиям для мобильных устройств, наличие мета-тега ViewPort является обязательным и для Google, и для Яндекса.
Мета-тег NoYDIR
Синтаксис
<meta name="slurp" content="noydir" /> или <meta name="robots" content="noydir" />
Тег должен находиться внутри контейнера <head>…</head> в любом месте. Этот тег используется в следующих случаях. Если сайт был добавлен в каталог Yahoo!, то некоторые поисковые системы могут выводить описание сайта, взятое из Yahoo! Directory. Если это не нужно, то добавляется этот тег.
Мета-тег Generator
Синтаксис
<meta name="generator" content="WordPress 4.6.6" />
Тег должен находиться внутри контейнера <head>…</head> в любом месте.
Эти мета-теги используются некоторыми CMS с целью предоставления информации о том, на каком движке или на какой версии движка сделан данный сайт. Если он указан, специалисту будет легко определить CMS сайта.
Мета-теги Author и Copyright
Синтаксис
<meta name="author" content="Иван Иванович" />
<meta name="copyright" lang="ru" content="ООО Ромашка" />
Тег должен находиться внутри контейнера <head>…</head> в любом месте.
Теги используются соответственно для указания авторства и авторских прав. Не стоит путать эти мета-теги с возможностями микроразметки. Если необходимо корректно настроить авторство, лучше обратиться к этим статьям:
Польза метатега robots и X-Robots-Tag для SEO
Рассмотрим, когда стоит использовать данные теги и как это помогает оптимизировать сайт.
1. Управление индексацией страниц
Не все страницы сайта полезны для привлечения органического трафика. Индексация некоторых из них, например, дублей, может и вовсе навредить видимости ресурса. Поэтому с помощью команды noindex обычно скрывают:
- дубликаты страниц;
- страницы сортировки и фильтров;
- страницы поиска и пагинации;
- служебные и технические страницы;
- сервисные сообщения для клиентов (об успешной регистрации, заказе и т.д.);
- посадочные страницы для рекламных кампаний и тестирования гипотез;
- страницы в процессе наполнения и разработки (лучше закрывать паролем);
- информацию, которая пока не актуальна (будущая акция, запуск новинки, анонсы запланированных мероприятий);
- устаревшие и неэффективные страницы, которые не приносят трафик;
- страницы, которые нужно закрыть от некоторых видов ботов.
2. Управление индексацией файлов определенного формата
От робота можно скрывать не только html-страницы, но и документ с другим расширением, например, страницу изображения или pdf-файл.
3. Сохранение веса страницы
Запрещая роботам переходить по ссылкам с помощью команды nofollow, можно сохранить вес страницы — он не будет передаваться сторонним ресурсам или другим страницам сайта, которые не приоритетны для индексации.
4. Рациональный расход краулингового бюджета
Чем больше ресурс, тем важнее направлять робота только на самые важные страницы. Если поисковики будут сканировать все подряд, краулинговый бюджет исчерпается до того, как робот начнет сканировать ценный для пользователей и SEO-контент. Соответственно, эти страницы не попадут в индекс или окажутся там с опозданием.
Популярные статьи

- 6.4K
- 5 мин.
Алгоритм BERT – чем грозит вашему сайту и как с ним бороться
Обзор алгоритма BERT – как поменяется поиск Google в России с его внедрением, какое влияние окажет на позиции и трафик сайтов. Рассказываем несколько способов, как подготовить сайт заранее и избежать негативных последствий.
- 26 февраля 2020
- Продвижение

- 67K
- 8 мин.
Зачем вам нужен AMP Google? И нужен ли?
Google продолжает борьбу за улучшение мобильной поисковой выдачи. В продолжение mobile-friendly активно развивается проект AMP – так называемые «ускоренные мобильные страницы». Давайте посмотрим, как AMP будет помогать пользователям мобильных устройств, и, что еще важнее, сможет ли AMP помочь продвижению вашего сайта.
- 4 марта 2018
- Продвижение

- 6.9K
- 16 мин.
Эволюция не по Дарвину: все алгоритмы Яндекса с 2007 по 2019 год
С каждым годом поисковые алгоритмы Яндекса обновляются, меняется подход к ранжированию сайтов. В статье мы расскажем о хронологии всех основных алгоритмов Яндекса по порядку с 2007 года и на сегодняшний день с обзором нововведений. Вы узнаете о работе поисковика и поймете, что нужно учитывать при продвижении своего ресурса.
- 6 февраля 2020
- Продвижение
How Can I Combine Noindex and Disallow?
Noindex (page) + Disallow: Disallow can’t be combined with noindex on the page, because the page is blocked and therefore search engines won’t crawl it to know that they’re not supposed to leave the page out of the index.
Noindex (robots.txt) + Disallow: This prevents pages appearing in the index, and also prevents the pages being crawled. However, remember that no PageRank can pass through this page.
To combine a disallow with a noindex in your robots.txt, simply add both directives to your robots.txt file:
Disallow: /example-page-1/
Disallow: /example-page-2/
Noindex: /example-page-1/
Noindex: /example-page-2/
Причины для запрета попадания пагинации в индекс
В случае, если ваш шаблон поддерживает формирования пагинации и для нее не прописан noindex, то она будет формироваться автоматически, без участия админ-панели WordPress. Несмотря на правильную цель, с учетом реализации, попадание таких страниц в выдачу (к примеру Яндекса) только пессимизирует проект. Для коммерции это спровоцирует падение в органике товаров.
Эта ВордПресс рубрика не привносит ничего нового, не добавляет ценности ресурсу, но имеет канонические адреса и содержит много внутренних ссылок с заимствованных из других материалов вырезками.
Говоря про простановку title & description надо знать также и то, что они созданы автоматически и по большей части нечитабельны и содержат кучу ключей и предлогов. В самой системе нельзя запрещать их автоматическое генерирование.
What Is Robots.txt?
A robots.txt file tells crawlers what should be crawled.
It’s part of the robots exclusion protocol (REP).
Googlebot is an example of a crawler.
Google deploys Googlebot to crawl websites and record information on that site to understand how to rank the site in Google’s search results.
You can find any site’s robots.txt file by add /robots.txt after the web address like this:
www.mywebsite.com/robots.txt
Here is what a basic, fresh, robots.txt file looks like:
The asterisk * after user-agent tells the crawlers that the robots.txt file is for all bots that come to the site.
Advertisement
Continue Reading Below
The slash / after “Disallow” tells the robot to not go to any pages on the site.
Here is an example of Moz’s robots.txt file.

You can see they are telling the crawlers what pages to crawl using user-agents and directives. I’ll dive into those a little later.
Утекает ли вес ссылки через nofollow?
А вот с Яндексом вопрос не явный. Он четко пишет в своей документации, что данный атрибут запрещает индексацию таких ссылок.

А если мы перейдем в описание атрибута robots nofollow, то здесь уже видим запрет на переход, и не слово про индексацию.

Но, раньше можно было это проверить, если применить в поиске такую конструкцию url: ваш урл << inlink:(“анкор ссылки”), и Яндекс нам отображал только те страницы, где содержится наш искомый анкор ссылки. Сейчас же этот метод не работает, поисковая система Яндекс запретила использовать такую конструкцию в поиске. Поэтому можно с большей долью вероятностью сказать, что Яндекс может учитывать такие ссылки, потому что они появляются в Яндекс Вебмастер.
Видно, например, что Яндекс учитывает ссылки с Твиттера, даже если они отдаются через редирект и закрыты nofollow.
В целом можно сказать, что применение данного атрибута для поисковых роботов не всегда является запретом, если особенно сайт авторитетный.
Список параметров мета-тега name robots:
Для всех поисковых систем
index – позволяет индексировать текст страницы
noindex – не индексировать текст страницы
follow – индексировать ссылки на этой странице
nofollow – не индексировать ссылки на этой странице
all – индексировать текст и ссылки на странице
none — не индексировать текст и ссылки на странице
noarchive – не показывает ссылку на сохраненную копию на странице поисковой системы
Только для Яндекса:
noyaca – не использовать описание Яндекс Каталога в результатах выдачи Яндекса
Только для Google:
nosnippet – не использует фрагмент содержания в результах поиска Google
noodp – не использует описание из каталогов ODP/DMOZ в результатах поиска Google
unavailable_after:: — возможность указать точную дату и время, когда необходимо прекратить индексирование страницы
noimageindex – не использует картинки сайта в качестве источника ссылки, которая отображается в поисковой системе Google
Если тег meta name robots отсутствует на страницы, то мы автоматически разрешаем роботу индексировать текст и ссылки на странице.
Читайте в нашем блоге: Google Песочница — как не попасть под фильтр?
Итак, разберем каждый пример отдельно
Этот пример позволит закрыть от индексации текст страницы, но будет учитывать все ссылки на сайте и соответственно проиндексирует их. Та же ситуация произойдет если, мы добавим follow
Разницы нет, писать можно так и так.
Если мы хотим полностью закрыть страницу от индексации через тег meta name, то есть два способа:
(Также можно использовать на странице тег noindex и и атрибут nofollow)
Оба варианта позволят роботу не учитывать текст и ссылки на странице.
Этот тег учитывает все ссылки и текст
Далее я расскажу в каких случаях использовать.
Use topic properties to override the default value for some pages
To make the template as flexible as possible, we can leverage topic properties to override the default Robots meta tag value for some specific topics.
1. Handle topic properties in the template

We first need to update our function to check if a specific topic has an overridden value in its topic properties. In HelpNDoc’s template editor:
- Navigate to the “Script files” section
- Select the “topics.pas.html” file, which is the one used to produce each topic’s HTML content
- Click “Edit Script”
- Replace the previously created function with this one:
- Click “Save” to save the script file
- Click “Save” to save the template
2. Override the robots meta tag value for some topics
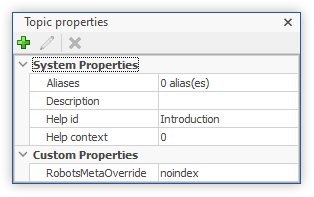
Now that the template is in place, we can simply override the default robots meta tag value for some topics as follows:
- In HelpNDoc’s table of contents editor, navigate to the desired topic
- In the “Topic properties” panel, click the “+” icon to create a new custom property
- Specify its name: “RobotsMetaOverride”
- Click “OK”
- In the “Topic properties” panel, select and edit the value of the newly created custom property. For example: to hide this page from search results
Директивы Meta Robots и какие поисковые системы их учитывают
Всего существует чуть больше десятка основных директив Meta Robots, которые можно комбинировать между собой:
- — запрещает индексирование страницы.
- — запрещает роботу переходить по ссылкам с этой страницы.
- — аналогичен комбинации noindex, nofollow.
- — нет ограничений на индексирование и показ контента. Директива используется по умолчанию и не влияет на работу поисковых роботов, если нет других указаний.
- — не индексировать изображения на этой странице.
- — запрещает показывать ссылку «Сохраненная копия» для определенной страницы.
- — указывает на необходимость отправить запрос на сервер для валидации ресурса перед использованием кэшированных данных.
- — запрещает показывать видео или фрагмент текста в результатах поиска.
- — запрещает предлагать перевод этой страницы в результатах поиска.
- — указывает точную дату и время, когда нужно прекратить сканирование и индексирование этой страницы.
- — не использовать метаданные из проекта Open Directory для заголовков или фрагментов этой страницы.
- — не брать название сайта и его описание из Yahoo! Directory (каталога Yahoo!).
- — не использовать описание из Яндекс.Каталога для сниппета в результатах поиска.
Некоторые из директив по-разному воспринимаются роботами тех или иных поисковых систем. В таблице ниже собрана информация о том, как боты систем Google, Yahoo, Bing и Яндекс работают с директивами Meta Robots.
| Директивы | Yahoo | Bing | Яндекс | |
|---|---|---|---|---|
| index | Да* | Да* | Да* | Да |
| noindex | Да | Да | Да | Да |
| follow | Да* | Да* | Да* | Да |
| nofollow | Да | Да | Да | Да |
| none | Да | ? | ? | Да |
| all | Да | ? | ? | Да |
| noimageindex | Да | Нет | Нет | Нет |
| noarchive | Да | Да | Да | Да |
| nocache | Нет | Нет | Да | Нет |
| nosnippet | Да | Нет | Да | Нет |
| notranslate | Да | Нет | Нет | Нет |
| unavailable_after | Да | Нет | Нет | Нет |
| noodp | Нет | Да** | Да** | Нет |
| noydir | Нет | Да** | Нет | Нет |
| noyaca | Нет | Нет | Нет | Да |
* Поисковая система не имеет официальной документации, которая бы подтверждала поддержку этой директивы. Но предполагается, что поддержка исключающего значения (например, nofollow) подразумевает поддержку положительного (например, follow).
** Теги noodp и noydir перестали поддерживаться, и, вероятно, не работают.
Test robots.txt using Search Console
The robots.txt Tester tool in Search Console (under Crawl) is a popular and largely effective way to check a new version of your file for any errors before it goes live, or test a specific URL to see whether it’s blocked:

However, this tool doesn’t work exactly the same way as Google, with some subtle differences in conflicting Allow/Disallow rules which are the same length.
The robots.txt testing tool reports these as Allowed, however Google has said ‘If the outcome is undefined, robots.txt evaluators may choose to either allow or disallow crawling. Because of that, it’s not recommended to rely on either outcome being used across the board.’
For more detail, read .
How to Set Up Robots Meta Tags and X‑Robots-Tag
Setting up robots meta tags is, generally, easier than the x-robots-tag, but the implementation of both methods of controlling how search engines crawl and index your site can differ depending on your CMS and/or server type.
Here’s how yo use meta robots tags and the x-robots-tag on common setups:
Using Robots Meta Tags in HTML Code
If you can edit your page’s HTML code, simply add your robots meta tags straight into the <head> section of the page.
If you want search engines not to index the page but want links to be followed, as an example, use:
Using Robots Meta Tags on WordPress
If you’re using Yoast SEO, open up the ‘advanced’ tab in the block below the page editor.
You can set the «noindex» directive by setting the «Allow search engines to show this page in search results?» dropdown to no or prevent links from being followed by setting the «Should search engines follow links on this page?» to no.
For any other directives, you will need to implement these in the «Meta robots advanced» field.
If you’re using RankMath, you can select the robots directives that you wish apply straight from the Advanced tag of the meta box:
Image courtesy of RankMath
Using Robots Meta Tags on Shopify
If you need to implement robots meta tags on Shopify, you’ll need to do this by editing the <head> section of your theme.liquid layout file.
To set the directives for a specific page, add the below code to this file:
This code will instruct search engines, not to index /page-name/ but to follow all of the links on the page.
You will need to make separate entries to set the directives across different pages.
Using X-Robots-Tag on an Apache Server
To use the x-robots-tag on an Apache web server, add the following to your site’s .htaccess file or httpd.config file.
The example above sets the file type of .pdf and instructs search engines not to index the file but to follow any links on it.
Using X-Robots-Tag on an Nginx Server
If you’re running an Nginx server, add the below to your site’s .conf file:
This will apply a noindex attribute and follow any links on a .pdf file.
Влияние внутренних ссылок на индексацию сайта
Внутренние ссылки являются основной и практически единственной причиной того, что нам приходится закрывать ненужные и попавшие в индекс страницы разными метатегами и директивами robots.txt. Однако реальность такова, что ненужные роботам страницы очень даже нужны пользователям сайта, а следовательно должны быть и ссылки на эти самые страницы.
А что же делать? При любом варианте запрета индексации ссылок (rel=”nofollow”) и страниц (robots.txt, meta robots), вес сайта просто теряется, утекает на закрытые страницы.
Вариант №1. Большинство распространенных CMS имеют возможность использования специальных тегов (в DLE точно это есть, я сам этим очень активно пользуюсь) при создании шаблонов оформления, которые позволяют регулировать вывод определенной информации. Например, показывать какой-либо текст только гостям или группе пользователей с определенным id и т.д. Если таких тегов вдруг нет, то наверняка на помощь придут логические конструкции (такие конструкции есть в WordPress, а так же форумных движках IPB и vbulletin, опять же, я сам пользуюсь этими возможностями), представляющие из себя простейшие условные алгоритмы на php.
Так вот, логично было бы скрывать неважные и ненужные ссылки от гостей (обычно эту роль играют и роботы при посещении любого сайта), а так же скрывать ссылки на страницы, которые выдают сообщение о том, что вы не зарегистрированы, не имеете прав доступа и все такое. При необходимости можно специально для гостей выводить блок с информацией о том, что после регистрации у них появится больше прав и возможностей, а значит и соответствующие ссылки появятся 😉
Но бывают такие моменты, что ссылку нельзя скрыть или удалить, потому что она нужна, и нужна сразу всем – гостям, пользователям… А вот роботам не нужна. Что делать?
Вариант №2. В редких случаях (хотя последнее время все чаще и чаще) бывает необходимо, чтобы ссылки или даже целые блоки сайта были недоступны и невидны роботам, а вот людям отображались и работали в полной мере, вне зависимости от групп и привилегий. Вы уже, наверное, догадались, что я говорю про сокрытие контента при помощи JavaScript или AJAX. Как это делается технически, я не буду расписывать, это очень долго. Но есть замечательный пост Димы Dimox’а о том, как загрузить часть контента с помощью AJAX на примере WordPress (линк). В примере рассказывается про подгрузку целого сайдбара, но таким же методом можно подгрузить одну только ссылку, например. В общем, немного покопаетесь и разберетесь.
Так вот, если хочется какую-то часть контента роботам не показывать, то лучший выбор – JavaScript. А после того как провернете всю техническую часть, проверить это на работоспособность поможет замечательный плагин для FireFox под названием QuickJava. Просто с помощью плагина отключите для браузера обработку яваскрипта и перезагрузите страницу, весь динамически подгружаемый контент должен пропасть 😉 Но помните, что тут тоже надо знать меру!
И, кстати, еще парочка интересных моментов, которые необходимо знать:
Яндексу в индексации сайтов помогает Яндекс.Метрика, которая автоматически пингует в индекс все посещенные страницы, на которых установлен код Метрики. Но эту функцию можно отключить при получении кода счетчика, установив соответсвующую галочку.
Возможно как то в индексации замешаны Яндекс.Бар и сборка браузера Хром от Яндекса, но в этом я не уверен.
Но вот для Гугла есть информация, что роль поискового робота выполняет сам браузер Google Chrome. Такие уж они хитрецы.
Так что, как видим, скрыть информацию от роботов почти невозможно, если не предпринимать специальные меры.







