Get и post запросы c модулем requests в python
Содержание:
- Сбор данных веб-страницы с помощью Requests
- Python requests head method
- GET и POST запросы с использованием Python
- Использование Translate API
- Legacy interface¶
- Lower-Level Classes¶
- Параллелизм
- Python requests reading a web page
- Содержимое ответа
- Cookies¶
- Migrating to 2.x¶
- Работа с данными JSON в Python
- BeautifulSoup метод find_all() поиск всех тегов в HTML
- HTTP-коды состояний
- Содержимое ответа (response)
- Request Method
- Make a Request¶
- Main Classes¶
Сбор данных веб-страницы с помощью Requests
С помощью этих двух библиотек Python, можно проанализировать веб-страницу.
Перейдите в Python Interactive Console:
Импортируйте модуль Requests, чтобы собрать данные с веб-страницы:
Присвойте URL-адрес тестовой страницы (в данном случае это mockturtle.html) переменной url.
Затем можно присвоить результат запроса этой страницы переменной page с помощью . Передайте URL-адрес страницы, который был присвоен переменной url, этому методу.
Переменная page присвоена объекту Response.
Объект Response сообщает свойство status_code в квадратных скобках (в данном случае это 200). Этот атрибут можно вызвать явно:
Возвращаемый код 200 сообщает, что страница загружена успешно. Коды, начинающиеся с номера 2, обычно указывают на успешное выполнение операции, а коды, начинающиеся с 4 или 5, сообщают об ошибке. Вы можете узнать больше о кодах состояния HTTP по .
Чтобы работать с веб-данными, нужно получить доступ к текстовому содержимому веб-файлов. Прочитать содержимое ответа сервера можно с помощью page.text (или page.content, чтобы получить значение в байтах).
Нажмите Enter.
Полный текст страницы был отображен со всеми тегами HTML. Однако его трудно прочитать, поскольку между ними не так много пробелов.
Python requests head method
The method retrieves document headers.
The headers consist of fields, including date, server, content type,
or last modification time.
head_request.py
#!/usr/bin/env python3
import requests as req
resp = req.head("http://www.webcode.me")
print("Server: " + resp.headers)
print("Last modified: " + resp.headers)
print("Content type: " + resp.headers)
The example prints the server, last modification time, and content type
of the web page.
$ ./head_request.py Server: nginx/1.6.2 Last modified: Sat, 20 Jul 2019 11:49:25 GMT Content type: text/html
This is the output of the program.
GET и POST запросы с использованием Python
Существует два метода запросов HTTP (протокол передачи гипертекста): запросы GET и POST в Python.
Что такое HTTP/HTTPS?
HTTP — это набор протоколов, предназначенных для обеспечения связи между клиентами и серверами. Он работает как протокол запроса-ответа между клиентом и сервером.
Веб-браузер может быть клиентом, а приложение на компьютере, на котором размещен веб-сайт, может быть сервером.
Итак, чтобы запросить ответ у сервера, в основном используют два метода:
- GET: запросить данные с сервера. Т.е. мы отправляем только URL (HTTP) запрос без данных. Метод HTTP GET предназначен для получения информации от сервера. В рамках GET-запроса некоторые данные могут быть переданы в строке запроса URI в формате параметров (например, условия поиска, диапазоны дат, ID Объекта, номер счетчика и т.д.).
- POST: отправить данные для обработки на сервер (и получить ответ от сервера). Мы отправляем набор информации, набор параметров для API. Метод запроса POST предназначен для запроса, при котором веб-сервер принимает данные, заключённые в тело сообщения POST запроса.
Чтобы сделать HTTP-запросы в python, мы можем использовать несколько HTTP-библиотек, таких как:
- HTTPLIB
- URLLIB
- REQUESTS
Самая элегантная и простая из перечисленных выше библиотек — это Requests. Библиотека запросов не является частью стандартной библиотеки Python, поэтому вам нужно установить ее, чтобы начать работать с ней.
Если вы используете pip для управления вашими пакетами Python, вы можете устанавливать запросы, используя следующую команду:
pip install requests
Если вы используете conda, вам понадобится следующая команда:
conda install requests
После того, как вы установили библиотеку, вам нужно будет ее импортировать
Давайте начнем с этого важного шага:
import requests
Синтаксис / структура получения данных через GET/POST запросы к API
Есть много разных типов запросов. Наиболее часто используемый, GET запрос, используется для получения данных.
Когда мы делаем запрос, ответ от API сопровождается кодом ответа, который сообщает нам, был ли наш запрос успешным. Коды ответов важны, потому что они немедленно сообщают нам, если что-то пошло не так.
Чтобы сделать запрос «GET», мы будем использовать функцию.
Метод используется, когда вы хотите отправить некоторые данные на сервер.
Ниже приведена подборка различных примеров использования запросов GET и POST через библиотеку REQUESTS. Безусловно, существует еще больше разных случаев. Всегда прежде чем, писать запрос, необходимо обратиться к официальной документации API (например, у Yandex есть документация к API различных сервисов, у Bitrix24 есть документация к API, у AmoCRM есть дока по API, у сервисов Google есть дока по API и т.д.). Вы смотрите какие методы есть у API, какие запросы API принимает, какие данные нужны для API, чтобы он мог выдать информацию в соответствии с запросом. Как авторизоваться, как обновлять ключи доступа (access_token). Все эти моменты могут быть реализованы по разному и всегда нужно ответ искать в официальной документации у поставщика API.
#GET запрос без параметров
response = requests.get('https://api-server-name.com/methodname_get')
#GET запрос с параметрами в URL
response = requests.get("https://api-server-name.com/methodname_get?param1=ford¶m2=-234¶m3=8267")
# URL запроса преобразуется в формат https://api-server-name.com/methodname_get?key2=value2&key1=value1
param_request = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://api-server-name.com/methodname_get', params=param_request)
#GET запрос с заголовком
url = 'https://api-server-name.com/methodname_get'
headers = {'user-agent': 'my-app/0.0.1'}
response = requests.get(url, headers=headers)
#POST запрос с параметрами в запросе
response = requests.post('https://api-server-name.com/methodname_post', data = {'key':'value'})
#POST запрос с параметрами через кортеж
param_tuples =
response = requests.post('https://api-server-name.com/methodname_post', data=param_tuples)
#POST запрос с параметрами через словарь
param_dict = {'param': }
response = requests.post('https://api-server-name.com/methodname_post', data=payload_dict)
#POST запрос с параметрами в формате JSON
import json
url = 'https://api-server-name.com/methodname_post'
param_dict = {'param': 'data'}
response = requests.post(url, data=json.dumps(param_dict))
Использование Translate API
Теперь перейдем к чему-то более интересному. Мы используем API Яндекс.Перевод (Yandex Translate API) для выполнения запроса на перевод текста на другой язык.
Чтобы использовать API, нужно предварительно войти в систему. После входа в систему перейдите к Translate API и создайте ключ API. Когда у вас будет ключ API, добавьте его в свой файл в качестве константы. Далее приведена ссылка, с помощью которой вы можете сделать все перечисленное: https://tech.yandex.com/translate/
script.py
Ключ API нужен, чтобы Яндекс мог проводить аутентификацию каждый раз, когда мы хотим использовать его API. Ключ API представляет собой облегченную форму аутентификации, поскольку он добавляется в конце URL запроса при отправке.
Чтобы узнать, какой URL нам нужно отправить для использования API, посмотрим документацию Яндекса.
Там мы найдем всю информацию, необходимую для использования их Translate API для перевода текста.
Если вы видите URL с символами амперсанда (&), знаками вопроса (?) или знаками равенства (=), вы можете быть уверены, что это URL запроса GET. Эти символы задают сопутствующие параметры для URL.
Обычно все, что размещено в квадратных скобках ([]), будет необязательным. В данном случае для запроса необязательны формат, опции и обратная связь, но обязательны параметры key, text и lang.
Добавим код для отправки на этот URL. Замените первый созданный нами запрос на следующий:
script.py
Существует два способа добавления параметров. Мы можем прямо добавить параметры в конец URL, или библиотека Requests может сделать это за нас. Для последнего нам потребуется создать словарь параметров. Нам нужно указать три элемента: ключ, текст и язык. Создадим словарь, используя ключ API, текст и язык , т. к. нам требуется перевод с английского на испанский.
Другие коды языков можно посмотреть здесь. Нам нужен столбец 639-1.
Мы создаем словарь параметров, используя функцию , и передаем ключи и значения, которые хотим использовать в нашем словаре.
script.py
Теперь возьмем словарь параметров и передадим его функции .
script.py
Когда мы передаем параметры таким образом, Requests автоматически добавляет параметры в URL за нас.
Теперь добавим команду печати текста ответа и посмотрим, что мы получим в результате.
script.py
Мы видим три вещи. Мы видим код состояния, который совпадает с кодом состояния ответа, мы видим заданный нами язык и мы видим переведенный текст внутри списка. Итак, мы должны увидеть переведенный текст .
Повторите эту процедуру с кодом языка en-fr, и вы получите ответ .
script.py
Посмотрим заголовки полученного ответа.
script.py
Разумеется, заголовки должны быть другими, поскольку мы взаимодействуем с другим сервером, но в данном случае мы видим тип контента application/json вместо text/html. Это означает, что эти данные могут быть интерпретированы в формате JSON.
Если ответ имеет тип контента application/json, библиотека Requests может конвертировать его в словарь и список, чтобы нам было удобнее просматривать данные.
Для обработки данных в формате JSON мы используем метод на объекте response.
Если вы распечатаете его, вы увидите те же данные, но в немного другом формате.
script.py
Причина отличия заключается в том, что это уже не обычный текст, который мы получаем из файла res.text. В данном случае это печатная версия словаря.
Допустим, нам нужно получить доступ к тексту. Поскольку сейчас это словарь, мы можем использовать ключ текста.
script.py
Теперь мы видим данные только для этого одного ключа. В данном случае мы видим список из одного элемента, так что если мы захотим напрямую получить текст в списке, мы можем использовать указатель для доступа к нему.
script.py
Теперь мы видим только переведенное слово.
Разумеется, если мы изменим параметры, мы получим другие результаты. Изменим переводимый текст с на , изменим язык перевода на испанский и снова отправим запрос.
script.py
Попробуйте перевести более длинный текст на другие языки и посмотрите, какие ответы будет вам присылать API.
Legacy interface¶
The following functions and classes are ported from the Python 2 module
(as opposed to ). They might become deprecated at
some point in the future.
- (url, filename=None, reporthook=None, data=None)
-
Copy a network object denoted by a URL to a local file. If the URL
points to a local file, the object will not be copied unless filename is supplied.
Return a tuple where filename is the
local file name under which the object can be found, and headers is whatever
the method of the object returned by returned (for
a remote object). Exceptions are the same as for .The second argument, if present, specifies the file location to copy to (if
absent, the location will be a tempfile with a generated name). The third
argument, if present, is a callable that will be called once on
establishment of the network connection and once after each block read
thereafter. The callable will be passed three arguments; a count of blocks
transferred so far, a block size in bytes, and the total size of the file. The
third argument may be on older FTP servers which do not return a file
size in response to a retrieval request.The following example illustrates the most common usage scenario:
>>> import urllib.request >>> local_filename, headers = urllib.request.urlretrieve('http://python.org/') >>> html = open(local_filename) >>> html.close()If the url uses the scheme identifier, the optional data
argument may be given to specify a request (normally the request
type is ). The data argument must be a bytes object in standard
application/x-www-form-urlencoded format; see the
function.will raise when it detects that
the amount of data available was less than the expected amount (which is the
size reported by a Content-Length header). This can occur, for example, when
the download is interrupted.The Content-Length is treated as a lower bound: if there’s more data to read,
urlretrieve reads more data, but if less data is available, it raises the
exception.You can still retrieve the downloaded data in this case, it is stored in the
attribute of the exception instance.If no Content-Length header was supplied, urlretrieve can not check the size
of the data it has downloaded, and just returns it. In this case you just have
to assume that the download was successful.
- ()
-
Cleans up temporary files that may have been left behind by previous
calls to .
- class (proxies=None, **x509)
-
Deprecated since version 3.3.
Base class for opening and reading URLs. Unless you need to support opening
objects using schemes other than , , or ,
you probably want to use .By default, the class sends a User-Agent header
of , where VVV is the version number.
Applications can define their own User-Agent header by subclassing
or and setting the class attribute
to an appropriate string value in the subclass definition.The optional proxies parameter should be a dictionary mapping scheme names to
proxy URLs, where an empty dictionary turns proxies off completely. Its default
value is , in which case environmental proxy settings will be used if
present, as discussed in the definition of , above.Additional keyword parameters, collected in x509, may be used for
authentication of the client when using the scheme. The keywords
key_file and cert_file are supported to provide an SSL key and certificate;
both are needed to support client authentication.objects will raise an exception if the server
returns an error code.- (fullurl, data=None)
-
Open fullurl using the appropriate protocol. This method sets up cache and
proxy information, then calls the appropriate open method with its input
arguments. If the scheme is not recognized, is called.
The data argument has the same meaning as the data argument of
.This method always quotes fullurl using .
- (fullurl, data=None)
-
Overridable interface to open unknown URL types.
- (url, filename=None, reporthook=None, data=None)
-
If the url uses the scheme identifier, the optional data
argument may be given to specify a request (normally the request type
is ). The data argument must in standard
application/x-www-form-urlencoded format; see the
function.
-
Variable that specifies the user agent of the opener object. To get
to tell servers that it is a particular user agent, set this in a
subclass as a class variable or in the constructor before calling the base
constructor.
Lower-Level Classes¶
- class (method=None, url=None, headers=None, files=None, data=None, params=None, auth=None, cookies=None, hooks=None, json=None)
-
A user-created object.
Used to prepare a , which is sent to the server.
Parameters: - method – HTTP method to use.
- url – URL to send.
- headers – dictionary of headers to send.
- files – dictionary of {filename: fileobject} files to multipart upload.
-
data – the body to attach to the request. If a dictionary or
list of tuples is provided, form-encoding will
take place. - json – json for the body to attach to the request (if files or data is not specified).
-
params – URL parameters to append to the URL. If a dictionary or
list of tuples is provided, form-encoding will
take place. - auth – Auth handler or (user, pass) tuple.
- cookies – dictionary or CookieJar of cookies to attach to this request.
- hooks – dictionary of callback hooks, for internal usage.
Usage:
>>> import requests >>> req = requests.Request('GET', 'https://httpbin.org/get') >>> req.prepare() <PreparedRequest >- (event, hook)
-
Deregister a previously registered hook.
Returns True if the hook existed, False if not.
- ()
-
Constructs a for transmission and returns it.
- (event, hook)
-
Properly register a hook.
Параллелизм
requests также имеют один существенный недостаток: эта библиотека синхронна. Вызов request.get («http://example.org») блокирует программу до тех пор, пока HTTP-сервер не ответит полностью. Недостатком может быть то, что приложение во время запроса ожидает ответа и ничего не делает. Вполне возможно, что программа могла бы делать что-то еще, а не сидеть без дела.
Интеллектуальное приложение может смягчить эту проблему, используя пул потоков, подобных тем, которые предоставляются concurrent.futures. Это позволяет очень быстро распараллеливать HTTP-запросы.
Использование futures с requests
from concurrent import futures
import requests
with futures.ThreadPoolExecutor(max_workers=4) as executor:
futures = [
executor.submit(
lambda: requests.get("http://example.org"))
for _ in range(8)
]
results =
print("Results: %s" % results)
Этот шаблон довольно полезен, он был упакован в библиотеку requests-futures. С помощью его можно легко использовать объект Session:
from requests_futures import sessions
session = sessions.FuturesSession()
futures = [
session.get("http://example.org")
for _ in range(8)
]
results =
print("Results: %s" % results)
По умолчанию создается worker с двумя потоками, но программа может легко настроить это значение, передав аргумент max_workers или даже своего собственного исполнителя объекту FuturSession — например, так: FuturesSession (executor = ThreadPoolExecutor (max_workers = 10)).
Python requests reading a web page
The method issues a GET request; it fetches documents
identified by the given URL.
read_webpage.py
#!/usr/bin/env python3
import requests as req
resp = req.get("http://www.webcode.me")
print(resp.text)
The script grabs the content of the web page.
resp = req.get("http://www.webcode.me")
The method returns a response object.
print(resp.text)
The text attribute contains the content of the response, in Unicode.
$ ./read_webpage.py
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My html page</title>
</head>
<body>
<p>
Today is a beautiful day. We go swimming and fishing.
</p>
<p>
Hello there. How are you?
</p>
</body>
</html>
This is the output of the script.
The following program gets a small web page and strips its HTML tags.
strip_tags.py
#!/usr/bin/env python3
import requests as req
import re
resp = req.get("http://www.webcode.me")
content = resp.text
stripped = re.sub('<+?>', '', content)
print(stripped)
The script strips the HTML tags of the
web page.
stripped = re.sub('<+?>', '', content)
A simple regular expression is used to strip the HTML tags.
Содержимое ответа
Открой для себя мир моментальных анонсов новых статей. Подпишись на мой канал в Telegram.
Мы можем читать содержимое различными способами, используя атрибуты и функции, предоставляемые модулем requests.
r.status_code возвращает код, указывающий, был ли запрос успешным или нет. 200 означает успешный. Общие коды статусов, которые вы, вероятно, видели — 200, 404 и 500. 404 означает ошибку клиента, а 500 означает ошибку сервера.
r.encoding возвращает кодировку ответа, основанную на HTTP заголовках.
r.url возвращает запрошенный URL.
r.json возвращает разобранные JSON данные из ответа.
r.text возвращает ответ в текстовом формате
r.content возвращает ответ, отформатированный в байтах
Cookies¶
If a response contains some Cookies, you can quickly access them:
>>> url = 'http://example.com/some/cookie/setting/url' >>> r = requests.get(url) >>> r.cookies'example_cookie_name' 'example_cookie_value'
To send your own cookies to the server, you can use the
parameter:
>>> url = 'https://httpbin.org/cookies'
>>> cookies = dict(cookies_are='working')
>>> r = requests.get(url, cookies=cookies)
>>> r.text
'{"cookies": {"cookies_are": "working"}}'
Cookies are returned in a ,
which acts like a but also offers a more complete interface,
suitable for use over multiple domains or paths. Cookie jars can
also be passed in to requests:
Migrating to 2.x¶
Compared with the 1.0 release, there were relatively few backwards
incompatible changes, but there are still a few issues to be aware of with
this major release.
For more details on the changes in this release including new APIs, links
to the relevant GitHub issues and some of the bug fixes, read Cory’s blog
on the subject.
API Changes
-
There were a couple changes to how Requests handles exceptions.
is now a subclass of rather than
as that more accurately categorizes the type of error.
In addition, an invalid URL escape sequence now raises a subclass of
rather than a .requests.get('http://%zz/') # raises requests.exceptions.InvalidURLLastly, exceptions caused by incorrect chunked
encoding will now raise a Requests instead. -
The proxy API has changed slightly. The scheme for a proxy URL is now
required.proxies = { "http" "10.10.1.10:3128", # use http://10.10.1.10:3128 instead } # In requests 1.x, this was legal, in requests 2.x, # this raises requests.exceptions.MissingSchema requests.get("http://example.org", proxies=proxies)
Behavioural Changes
- Keys in the dictionary are now native strings on all Python
versions, i.e. bytestrings on Python 2 and unicode on Python 3. If the
keys are not native strings (unicode on Python 2 or bytestrings on Python 3)
they will be converted to the native string type assuming UTF-8 encoding. - Values in the dictionary should always be strings. This has
been the project’s position since before 1.0 but a recent change
(since version 2.11.0) enforces this more strictly. It’s advised to avoid
passing header values as unicode when possible.
Работа с данными JSON в Python
JSON (JavaScript Object Notation) — это язык API. JSON — это способ кодирования структур данных, который простоту чтения данных машинами. JSON — это основной формат, в котором данные передаются туда и обратно в API, и большинство серверов API отправляют свои ответы в формате JSON.
JSON выглядит так, как будто он содержит словари, списки, строки и целые числа Python. Вы можете думать о JSON как о комбинации этих объектов, представленных в виде строк.
Рассмотрим пример:
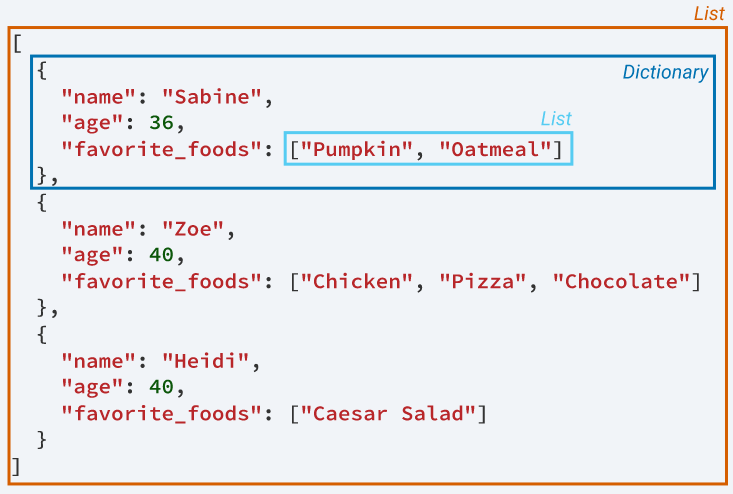
Python имеет отличный инструментарий для работы с данными в формате JSON (пакет json — является частью стандартной библиотеки). Мы можем конвертировать списки и словари в JSON, а также конвертировать строки в списки и словари.
Библиотека JSON имеет две основные функции:
- — принимает объект Python и преобразует его в строку.
- — принимает строку JSON и преобразует (загружает) ее в объект Python.
Функция особенно полезна, поскольку мы можем использовать ее для печати отформатированной строки, которая облегчает понимание вывода JSON.
Рассмотрим пример:
# Импорт библиотеки requests
import requests
# Запрос GET (Отправка только URL без параметров)
response = requests.get("http://api.open-notify.org/astros.json")
# Вывод кода
print(response.status_code)
# Вывод ответа, полученного от сервера API
print(response.json())
Результат:
200
{'people': , 'message': 'success', 'number': 3}
Теперь попробуем применить функцию dump() — структура данных станет более наглядна:
# Импорт библиотеки requests
import requests
# Импорт библиотеки json
import json
def jprint(obj):
# create a formatted string of the Python JSON object
text = json.dumps(obj, sort_keys=True, indent=4)
print(text)
# Запрос GET (Отправка только URL без параметров)
response = requests.get("http://api.open-notify.org/astros.json")
# Вывод ответа, через пользовательскую функцию jprint
jprint(response.json())
Результат:
{
"message": "success",
"number": 3,
"people":
}
BeautifulSoup метод find_all() поиск всех тегов в HTML
При помощи метода можно найти все элементы, которые соответствуют заданным критериям.
Python
#!/usr/bin/python3
from bs4 import BeautifulSoup
with open(«index.html», «r») as f:
contents = f.read()
soup = BeautifulSoup(contents, ‘lxml’)
for tag in soup.find_all(«li»):
print(«{0}: {1}».format(tag.name, tag.text))
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#!/usr/bin/python3 frombs4 importBeautifulSoup withopen(«index.html»,»r»)asf contents=f.read() soup=BeautifulSoup(contents,’lxml’) fortag insoup.find_all(«li») print(«{0}: {1}».format(tag.name,tag.text)) |
Код в примере позволяет найти и вывести на экран все теги.
Shell
$ ./find_all.py
li: Solaris
li: FreeBSD
li: Debian
li: NetBSD
|
1 2 3 4 5 |
$.find_all.py liSolaris liFreeBSD liDebian liNetBSD |
Это результат вывода.
Метод также при поиске использует список из названий тегов.
Python
#!/usr/bin/python3
from bs4 import BeautifulSoup
with open(«index.html», «r») as f:
contents = f.read()
soup = BeautifulSoup(contents, ‘lxml’)
tags = soup.find_all()
for tag in tags:
print(» «.join(tag.text.split()))
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#!/usr/bin/python3 frombs4 importBeautifulSoup withopen(«index.html»,»r»)asf contents=f.read() soup=BeautifulSoup(contents,’lxml’) tags=soup.find_all(‘h2′,’p’) fortag intags print(» «.join(tag.text.split())) |
В данном примере показано, как найти все и элементы, после чего вывести их содержимое на экран.
Метод также может использовать функцию, которая определяет, какие элементы должны быть выведены.
Python
#!/usr/bin/python3
from bs4 import BeautifulSoup
def myfun(tag):
return tag.is_empty_element
with open(«index.html», «r») as f:
contents = f.read()
soup = BeautifulSoup(contents, ‘lxml’)
tags = soup.find_all(myfun)
print(tags)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#!/usr/bin/python3 frombs4 importBeautifulSoup defmyfun(tag) returntag.is_empty_element withopen(«index.html»,»r»)asf contents=f.read() soup=BeautifulSoup(contents,’lxml’) tags=soup.find_all(myfun) print(tags) |
Данный пример выводит пустые элементы.
Shell
$ ./find_by_fun.py
[<meta charset=»utf-8″/>]
|
1 2 |
$.find_by_fun.py <meta charset=»utf-8″> |
Единственным пустым элементом в документе является .
Также можно найти запрашиваемые элементы, используя регулярные выражения.
Python
#!/usr/bin/python3
import re
from bs4 import BeautifulSoup
with open(«index.html», «r») as f:
contents = f.read()
soup = BeautifulSoup(contents, ‘lxml’)
strings = soup.find_all(string=re.compile(‘BSD’))
for txt in strings:
print(» «.join(txt.split()))
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#!/usr/bin/python3 importre frombs4 importBeautifulSoup withopen(«index.html»,»r»)asf contents=f.read() soup=BeautifulSoup(contents,’lxml’) strings=soup.find_all(string=re.compile(‘BSD’)) fortxt instrings print(» «.join(txt.split())) |
В данном примере выводится содержимое элементов, в которых есть строка с символами ‘BSD’.
Shell
$ ./regex.py
FreeBSD
NetBSD
FreeBSD is an advanced computer operating system used to power modern servers, desktops, and embedded platforms.
|
1 2 3 4 |
$.regex.py FreeBSD FreeBSD isan advanced computer operating system used topower modern servers,desktops,andembedded platforms. |
Это результат вывода.
HTTP-коды состояний
Первые данные, которые мы получим посредством Response, будут коды состояния. Они сообщают о статусе нашего запроса.
К примеру, статус 200 OK означает, что запрос был успешно выполнен. А известная всем ошибка 404 NOT FOUND скажет нам, что запрашиваемый ресурс найден не был. Таких статусных информационных кодов существует довольно много.
Давайте с помощью .status_code, увидим код состояния, возвращаемый с сервера.
>>> response.status_code 200
В нашем случае .status_code вернул 200, что означает успешно выполненный запрос.
Кстати, иногда полученная информация используется при написании кода:
if response.status_code == 200
print('Success!')
elif response.status_code == 404
print('Not Found.')
Содержимое ответа (response)
Теперь поговорим о том, как прочитать, что сервер ответил нам. В качестве примера снова будем использовать GitHub.
>>> import requests
>>> r = requests.get(‘https://api.github.com/events’)
>>> r.text
‘[{“repository”:{“open_issues”:0,”url”:”https://github.com/…
Ответ сервера поступает в закодированном виде. Библиотека Requests будет автоматически производить декодирование. Как правило, если ответ пришел в кодировке Unicode, то не должно возникать никаких проблем.
Если кодировка другая, Request пытается определить, какая она, основываясь на заголовке HTTP-запроса. Можно также изменить кодировку, используя r.encoding.
>>> r.encoding
‘utf-8’
>>> r.encoding = ‘ISO-8859-1’
Последовательность действий, которая необходима в каждом конкретном случае, отличается. Так, в HTML и XML можно указать кодировку непосредственно в блоке заголовка. В таком случае сначала необходимо определить кодировку с помощью r.content, а потом установить правильную кодировку с помощью r.encoding. Это даст возможность пользоваться правильной кодировкой документа.
Если появляется необходимость, то есть возможность использовать пользовательские кодировки. Для этого необходимо ее зарегистрировать в модуле codecs, а потом просто использовать ее имя в качестве значения r.encoding.
Request Method
The request method indicates the method to be performed on the resource identified by the given Request-URI. The method is case-sensitive and should always be mentioned in uppercase. The following table lists all the supported methods in HTTP/1.1.
| S.N. | Method and Description |
|---|---|
| 1 |
GET
The GET method is used to retrieve information from the given server using a given URI. Requests using GET should only retrieve data and should have no other effect on the data. |
| 2 |
HEAD
Same as GET, but it transfers the status line and the header section only. |
| 3 |
POST
A POST request is used to send data to the server, for example, customer information, file upload, etc. using HTML forms. |
| 4 |
PUT
Replaces all the current representations of the target resource with the uploaded content. |
| 5 |
DELETE
Removes all the current representations of the target resource given by URI. |
| 6 |
CONNECT
Establishes a tunnel to the server identified by a given URI. |
| 7 |
OPTIONS
Describe the communication options for the target resource. |
| 8 |
TRACE
Performs a message loop back test along with the path to the target resource. |
Make a Request¶
Making a request with Requests is very simple.
Begin by importing the Requests module:
>>> import requests
Now, let’s try to get a webpage. For this example, let’s get GitHub’s public
timeline:
>>> r = requests.get('https://api.github.com/events')
Now, we have a object called . We can
get all the information we need from this object.
Requests’ simple API means that all forms of HTTP request are as obvious. For
example, this is how you make an HTTP POST request:
>>> r = requests.post('https://httpbin.org/post', data = {'key''value'})
Nice, right? What about the other HTTP request types: PUT, DELETE, HEAD and
OPTIONS? These are all just as simple:
>>> r = requests.put('https://httpbin.org/put', data = {'key''value'})
>>> r = requests.delete('https://httpbin.org/delete')
>>> r = requests.head('https://httpbin.org/get')
>>> r = requests.options('https://httpbin.org/get')
Main Classes¶
These classes are the main interface to :
- class (*, session: Union = None, url: str = ‘https://example.org/’, html: Union, default_encoding: str = ‘utf-8’, async_: bool = False)
-
An HTML document, ready for parsing.
Parameters: - url – The URL from which the HTML originated, used for .
- html – HTML from which to base the parsing upon (optional).
- default_encoding – Which encoding to default to.
-
All found links on page, in absolute form
(learn more).
- (retries: int = 8, script: str = None, wait: float = 0.2, scrolldown=False, sleep: int = 0, reload: bool = True, timeout: Union = 8.0, keep_page: bool = False, cookies: list = , send_cookies_session: bool = False)
-
Async version of render. Takes same parameters.
-
The base URL for the page. Supports the tag
(learn more).
-
The encoding string to be used, extracted from the HTML and
headers.
- (selector: str = ‘*’, *, containing: Union] = None, clean: bool = False, first: bool = False, _encoding: str = None) → Union, requests_html.Element]
-
Given a CSS Selector, returns a list of
objects or a single one.Parameters: - selector – CSS Selector to use.
- clean – Whether or not to sanitize the found HTML of and tags.
- containing – If specified, only return elements that contain the provided text.
- first – Whether or not to return just the first result.
- _encoding – The encoding format.
Example CSS Selectors:
See W3School’s CSS Selectors Reference
for more details.If is , only returns the first
found.
-
The full text content (including links) of the
or .
-
Unicode representation of the HTML content
(learn more).
-
All found links on page, in as–is form.
-
lxml representation of the
or .
- (fetch: bool = False, next_symbol: List = ) → Union]
-
Attempts to find the next page, if there is one. If
is (default), returns object of
next page. If is , simply returns the next URL.
-
PyQuery representation
of the or .
-
Bytes representation of the HTML content.
(learn more).
- (retries: int = 8, script: str = None, wait: float = 0.2, scrolldown=False, sleep: int = 0, reload: bool = True, timeout: Union = 8.0, keep_page: bool = False, cookies: list = , send_cookies_session: bool = False)
-
Reloads the response in Chromium, and replaces HTML content
with an updated version, with JavaScript executed.Parameters: - retries – The number of times to retry loading the page in Chromium.
- script – JavaScript to execute upon page load (optional).
- wait – The number of seconds to wait before loading the page, preventing timeouts (optional).
- scrolldown – Integer, if provided, of how many times to page down.
- sleep – Integer, if provided, of how many seconds to sleep after initial render.
- reload – If , content will not be loaded from the browser, but will be provided from memory.
- keep_page – If will allow you to interact with the browser page through .
- send_cookies_session – If send convert.
- cookies – If not send .
If is specified, the page will scrolldown the specified
number of times, after sleeping the specified amount of time
(e.g. ).If just is provided, the rendering will wait n seconds, before
returning.If is specified, it will execute the provided JavaScript at
runtime. Example:script = """ () => { return { width: document.documentElement.clientWidth, height: document.documentElement.clientHeight, deviceScaleFactor: window.devicePixelRatio, } } """Returns the return value of the executed , if any is provided:
>>> r.html.render(script=script) {'width': 800, 'height': 600, 'deviceScaleFactor': 1}Warning: the first time you run this method, it will download
Chromium into your home directory ().
- (template: str) → parse.Result
-
Search the for the given Parse template.
Parameters: template – The Parse template to use.
- (template: str) → Union, parse.Result]
-
Search the (multiple times) for the given parse
template.Parameters: template – The Parse template to use.
-
The text content of the
or .
- (selector: str, *, clean: bool = False, first: bool = False, _encoding: str = None) → Union, List, str, requests_html.Element]
-
Given an XPath selector, returns a list of
objects or a single one.Parameters: - selector – XPath Selector to use.
- clean – Whether or not to sanitize the found HTML of and tags.
- first – Whether or not to return just the first result.
- _encoding – The encoding format.
If a sub-selector is specified (e.g. ), a simple
list of results is returned.See W3School’s XPath Examples
for more details.If is , only returns the first
found.







