Как думать на sql?
Содержание:
- Операции соединения SQL
- SQL Учебник
- Соединения (джойны)
- 5. Агрегирование
- 6. Подзапросы
- Использование SELECT и предикатов IN, OR, BETWEEN, LIKE
- Синтаксис
- English[edit]
- HTML Справочник
- HTML Теги
- Д. Использование связанных вложенных запросов
- Атрибуты
- Примеры:
- Создаём гибридный селектСкопировать ссылку
- Атрибуты¶
- Описание команды SELECT
Операции соединения SQL
Операция соединения используется для извлечения данных из нескольких таблиц. Например, если есть две таблицы order и и мы хотим получить данные, то это можно сделать с помощью предложения .
Различные типы предложения JOIN следующие:
- : внутреннее соединение возвращает только те записи, значения которых совпадают в обеих таблицах;
- : перекрестное соединение возвращает только те записи, которые имеют совпадающие значения в левой или правой таблице;
- : левое соединение возвращает все записи из левой таблицы и только совпадающие записи из правой таблицы;
- : правое соединение возвращает все записи из правой таблицы и только совпадающие записи из левой таблицы.
На следующем ниже рисунке показан краткий пример для рассмотрения:
INNER JOIN
Внутреннее соединение возвращает записи, совпадающие в обеих таблицах. Например, ниже приведена таблица заказов order, используемая в приложениях электронной коммерции:
|
order_id |
customer_id |
order_amount |
order_date |
ship_id |
|
1001 |
2 |
7 |
2017-07-18 |
3 |
|
1002 |
37 |
3 |
2017-07-19 |
1 |
|
1003 |
77 |
8 |
2017-07-20 |
2 |
Далее приведем пример таблицы клиентов customer, используемой в приложениях электронной коммерции, которая содержит данные о клиентах:
|
customer_id |
name |
country |
city |
postal_code |
|
1 |
Alfreds Futterkiste |
Germany |
Berlin |
12209 |
|
2 |
Ana Trujillo |
Mexico |
Mйxico D.F. |
05021 |
|
3 |
Antonio Moreno |
Mexico |
Mйxico D.F. |
05023 |
Следующий ниже запрос будет получать все записи заказа со сведениями о клиенте. Поскольку идентификаторы клиентов 37 и 77 отсутствуют в таблице customer, будут получены только совпадающие строки, за исключением идентификаторов клиентов 37 и 77:
Левое соединение извлекает все записи из левой таблицы и только совпадающие записи из правой таблицы. Если применить пример таблиц клиентов и заказов с левым соединением, то оно будет извлекать все записи из таблицы заказов order, даже если в правой таблице нет совпадений (customer). Чтобы получить все сведения о заказах для клиента, можно использовать следующий ниже запрос:
RIGHT JOIN
Правое соединение извлекает все записи из правой таблицы и общие записи из левой таблицы. Если применить пример таблиц клиентов и заказов с правым соединением, то оно будет извлекать все записи из таблицы клиентов customer, даже если в левой таблице (order) нет совпадений. Чтобы получить все сведения о клиентах с заказом, можно использовать следующий ниже запрос:
CROSS JOIN
Перекрестное соединение возвращает все записи, в которых есть совпадение в левой или правой записи таблицы. Если мы возьмем пример с таблицами заказов и клиентов, то оно вернет пять строк со сведениями о клиентах и заказах:
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции . Это означает, что мы запрашиваем данные из другой таблицы. Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице, которая создалась соединением этих двух таблиц.
— это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц «books» и «borrowings», в которых значения совпадают. Результатом такого слияния будет:
А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну. При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их ‘ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция обрабатывала все строки (так как мы считали количество строк). Другие функции вроде или обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция обрабатывает только колонку и считает сумму всех значений в каждой группе.
6. Подзапросы
Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
Использование SELECT и предикатов IN, OR, BETWEEN, LIKE
Предикаты — слова IN, OR, BETWEEN, LIKE в секции WHERE — также позволяют выбрать определённые диапазоны значений (IN, OR, BETWEEN) или
значения в строках (LIKE), которые требуется выбрать из таблицы. Запросы с предикатами IN, OR, BETWEEN имеют
следующий синтаксис:
SELECT ИМЯ_СТОЛБЦА FROM ИМЯ_ТАБЛИЦЫ
WHERE ЗНАЧЕНИЕ
ПРЕДИКАТ (IN, OR, BETWEEN) (ЗНАЧЕНИЯ, УКАЗЫВАЮЩИЕ ДИАПАЗОН)
Запросы с предикатом LIKE имеют следующий синтаксис:
SELECT ИМЯ_СТОЛБЦА FROM ИМЯ_ТАБЛИЦЫ
WHERE ИМЯ_СТОЛБЦА LIKE
ВЫРАЖЕНИЕ
Пример 7. Пусть требуется выбрать из таблицы Staff имена, должности
и число отработанных лет сотрудников, работающих в отделах с номерами 20 или 84.
Это можно сделать следующим запросом (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT Name, Job, Years
FROM Staff
WHERE Dept IN (20, 84)
Результат выполнения запроса:

На сайте есть подробный урок об использовании предиката IN.
Пример 8. Пусть теперь требуется выбрать из таблицы Staff те же данные,
что и в предыдущем примере. Запрос со словом OR аналогичен запросу со словом IN и перечислением интересующих
значений в скобках. Запрос будет следующим (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT Name, Job, Years
FROM Staff
WHERE Dept=20 OR Dept=84
Пример 9. Выберем из той же таблицы имена, должности
и число отработанных лет сотрудников, зарплата которых между 15000 и 17000 включительно (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT Name, Job, Years
FROM Staff
WHERE Salary BETWEEN 15000 AND 17000
Результат выполнения запроса:

На сайте есть подробный урок об использовании предиката BETWEEN.
Предикат LIKE используется для выборки тех строк, в значениях которых встречаются символы, указанные
после предиката между апострофами (‘).
Пример 10. Выберем из той же таблицы имена, должности
и число отработанных лет сотрудников, имена которых начинаются с буквы S и состоят из 7 символов
(на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT Name, Job, Years
FROM Staff
WHERE Name LIKE ‘S_ _ _ _ _ _’
Символ подчёркивания (_) означает любой символ. Результат выполнения запроса:

Пример 11. Выберем из той же таблицы имена, должности
и число отработанных лет сотрудников, имена которых начинаются с буквы S и содержат любые другие буквы
в любом количестве (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT Name, Job, Years
FROM Staff
WHERE Name LIKE ‘S%’
Символ процентов (%) означает любое количество символов. Результат выполнения запроса:
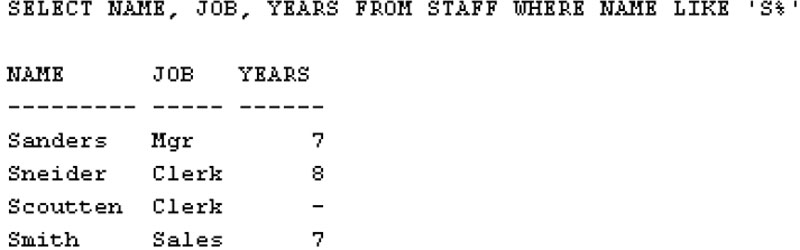
На сайте есть подробный урок об использовании предиката LIKE.
Значения, указанные с использованием предикатов IN, OR, BETWEEN, LIKE можно инвертировать при помощи
слова NOT. Тогда запрашиваемые данные будут иметь противоположный смысл. Если мы используем NOT IN (20, 84),
то будут выведены данные сотрудников, которые работают во всех отделах, кроме имеющих номера 20 и 84.
С использованием NOT BETWEEN 15000 AND 17000 можно получить данные сотрудников, зарплата которых не
входит в интервал от 15000 до 17000. Запрос с NOT LIKE выведет данные сотрудников, чьи имена не начинаются
или не содержат символов, указанных с NOT LIKE.
Синтаксис
Простой синтаксис для оператора SELECT в MySQL:
SELECT expressions
FROM tables
;
Полный синтаксис для оператора SELECT в MySQL:
SELECT
expressions
FROM tables
]
number_rows | LIMIT number_rows OFFSET offset_value]
;
Параметры или аргументы
ALL — необязательный. Возвращает все совпадающие строкиDISTINCT — необязательный. Удаляет дубликаты из набора результатов. Подробнее о DISTINCT.DISTINCTROW — необязательный. Синоним DISTINCT. Удаляет дубликаты из набора результатов.HIGH_PRIORITY — необязательный. Он сообщает MySQL, что он запускает SELECT перед любыми операторами UPDATE, ожидающими того же ресурса. Он может использоваться с таблицами MyISAM, MEMORY и MERGE, которые используют блокировку на уровне таблицы.STRAIGHT_JOIN — необязательный. Он сообщает MySQL о соединении таблиц в том порядке, в котором они перечислены в предложении FROM.SQL_SMALL_RESULT — необязательный. Использует быстрые временные таблицы для хранения результатов (используется с DISTINCT и GROUP BY).SQL_BIG_RESULT — необязательный. Предпочитает сортировку, а не временную таблицу для хранения результатов (используется с DISTINCT и GROUP BY).SQL_BUFFER_RESULT — необязательный. Использует временные таблицы для хранения результатов (не может использоваться с подзапросами).SQL_CACHE — необязательный. Сохраняет результаты в кеше запросов.SQL_NO_CACHE — необязательный. Не сохраняет результаты в кеше запросов.SQL_CALC_FOUND_ROWS — необязательный
Вычисляет, сколько записей находится в результирующем наборе (не принимая во внимание атрибут LIMIT), который затем можно получить с помощью функции FOUND_ROWS.expressions — столбцы или вычисления, которые вы хотите получить. Используйте *, если вы хотите выбрать все столбцы.tables — таблицы, из которых вы хотите получить записи
Должна быть хотя бы одна таблица, перечисленная в предложении FROM.WHERE conditions — необязательный. Условия, которые должны быть выполнены для выбранных записей.GROUP BY expressions — необязательный. Он собирает данные по нескольким записям и группирует результаты по одному или нескольким столбцам. Подробнее о GROUP BY.HAVING condition — необязательный. Он используется в сочетании с GROUP BY, чтобы ограничить группы возвращаемых строк только теми, чье условие TRUE. Подробнее о HAVING.ORDER BY expression — необязательный. Он используется для сортировки записей в вашем результирующем наборе. Подробнее о ORDER BY.LIMIT — необязательный. Если LIMIT указан, то он контролирует максимальное количество извлекаемых записей. Максимальное количество записей, заданных number_rows, будет возвращено в результирующем наборе. Первая строка, возвращаемая LIMIT, будет определяться значением offset_value.PROCEDURE — необязательный. Если указано, то — это имя процедуры, которая должна обрабатывать данные в результирующем наборе.INTO — необязательный. Если указан, это позволяет вам записать результирующий набор в файл или переменную.
| Значение | Пояснение |
|---|---|
| INTO OUTFILE ‘filename’ options |
«Записывает результирующий набор в файл с именем filename на хосте сервера. Для параметров вы можете указать: FIELDS ESCAPED BY ‘character’ FIELDS TERMINATED BY ‘character’ LINES TERMINATED BY ‘character’ где character — символ, отображаемый как символ ESCAPE, ENCLOSED или TERMINATED. Например: SELECT supplier_id, supplier_name FROM suppliers INTO OUTFILE ‘results.txt’ FIELDS TERMINATED BY ‘,’ OPTIONALLY ENCLOSED BY ‘»»‘ LINES TERMINATED BY ‘\n’;» |
| INTO DUMPFILE ‘filename’ |
Записывает одну строку набора результатов в файл с именем filename на хосте сервера. С помощью этого метода не происходит прерывания столбца, не прерывается линия или обработка перехода. |
| INTO @variable1, @variable2, … @variable_n |
Записывает набор результатов в одну или несколько переменных, как указано в параметрах @ variable1, @ variable2, … @variable_n |
FOR UPDATE — необязательный. Записи, затронутые запросом, блокируются, пока транзакция не завершится.LOCK IN SHARE MODE — необязательный. Записи, затронутые запросом, могут использоваться другими транзакциями, но не могут быть обновлены или удалены этими и другими транзакциями.
English[edit]
Pronunciationedit
-
IPA(key): /sɪˈlɛkt/
.mw-parser-output .k-player .k-attribution{visibility:hidden}Audio (UK)
(file)
- Rhymes: -ɛkt
- Hyphenation: se‧lect
Adjectiveedit
select ( , )
-
Privileged, specially selected.
- Only a select few were allowed into the premiere.
-
1849–1861, Thomas Babington Macaulay, chapter 20, in The History of England from the Accession of James the Second, volume (please specify |volume=I to V), London: Longman, Brown, Green, and Longmans, OCLC :
- A few select spirits had separated from the crowd, and formed a fit audience round a far greater teacher.
-
1892, Walter Besant, chapter III, in The Ivory Gate…, New York, N.Y.: Harper & Brothers,…, OCLC :
- At half-past nine on this Saturday evening, the parlour of the Salutation Inn, High Holborn, contained most of its customary visitors.…In former days every tavern of repute kept such a room for its own select circle, a club, or society, of habitués, who met every evening, for a pipe and a cheerful glass.
- Of high quality; top-notch.
- This is a select cut of beef.
Translationsedit
privileged, specially selected
|
|
of high quality; top-notch
|
|
Verbedit
select (third-person singular simple present , present participle , simple past and past participle )
- To choose one or more elements of a set, especially a set of options.
- He looked over the menu, and selected the roast beef.
- The program computes all the students’ grades, then selects a random sample for human verification.
- (databases) To obtain a set of data from a database using a query.
Translationsedit
to choose one or more elements from a set
|
|
to obtain a set of data
|
celest, elects, scelet
HTML Справочник
HTML Теги по алфавитуHTML Теги по категорииHTML ПоддержкаHTML АтрибутыHTML ГлобальныеHTML СобытияHTML Названия цветаHTML ХолстHTML Аудио/ВидеоHTML ДекларацииHTML Набор кодировокHTML URL кодHTML Коды языкаHTML Коды странHTTP СообщенияHTTP методыКовертер PX в EMКлавишные комбинации
HTML Теги
<!—…—>
<!DOCTYPE>
<a>
<abbr>
<acronym>
<address>
<applet>
<area>
<article>
<aside>
<audio>
<b>
<base>
<basefont>
<bdi>
<bdo>
<big>
<blockquote>
<body>
<br>
<button>
<canvas>
<caption>
<center>
<cite>
<code>
<col>
<colgroup>
<data>
<datalist>
<dd>
<del>
<details>
<dfn>
<dialog>
<dir>
<div>
<dl>
<dt>
<em>
<embed>
<fieldset>
<figcaption>
<figure>
<font>
<footer>
<form>
<frame>
<frameset>
<h1> — <h6>
<head>
<header>
<hr>
<html>
<i>
<iframe>
<img>
<input>
<ins>
<kbd>
<label>
<legend>
<li>
<link>
<main>
<map>
<mark>
<meta>
<meter>
<nav>
<noframes>
<noscript>
<object>
<ol>
<optgroup>
<option>
<output>
<p>
<param>
<picture>
<pre>
<progress>
<q>
<rp>
<rt>
<ruby>
<s>
<samp>
<script>
<section>
<select>
<small>
<source>
<span>
<strike>
<strong>
<style>
<sub>
<summary>
<sup>
<svg>
<table>
<tbody>
<td>
<template>
<textarea>
<tfoot>
<th>
<thead>
<time>
<title>
<tr>
<track>
<tt>
<u>
<ul>
<var>
<video>
<wbr>
Д. Использование связанных вложенных запросов
Коррелированный запрос — это запрос, зависящий от результатов выполнения другого запроса. Он может повторно выполняться для каждой строки, выбранной с помощью другого запроса.
В первом примере представлены семантически эквивалентные запросы для демонстрации различий в использовании ключевых слов и . В обоих примерах приведены допустимые вложенные запросы, извлекающие по одному экземпляру продукции каждого наименования, для которых модель продукта — «long sleeve logo jersey» (кофта с длинными рукавами, с эмблемой), а значения столбцов таблиц и совпадают.
Следующий пример использует и получает имена и фамилии сотрудников, для которых значение премии в таблице составляет , а соответствующие им идентификационные номера в таблицах и совпадают.
Предыдущий вложенный запрос данной инструкции не может быть выполнен независимо от внешнего запроса. Требуется значение параметра , однако в процессе обработки строк компонентом Компонент SQL Server Database Engine указанное значение меняется.
Коррелированный вложенный запрос также может использоваться в предложении внешнего запроса. В данном примере осуществляется поиск моделей продуктов, для которых максимальная цена в каталоге в два раза превышает среднюю цену по нему.
В данном примере с помощью двух коррелированных запросов осуществляется поиск сотрудников, продавших определенную продукцию.
Атрибуты
| Атрибут | Значение | Описание |
|---|---|---|
| autofocus | autofocus | Указывает, что выпадающий список должен автоматически получать фокус при загрузке страницы. |
| disabled | disabled | Логический атрибут, который указывает, что выпадающий список должен быть отключен. |
| form | form_id | Задает одну, или несколько форм к которым элемент принадлежит. |
| multiple | multiple | Логический атрибут, который указывает, что может быть выбрано несколько вариантов сразу (через Ctrl в Windows и через Command в Mac). |
| name | name | Определяет имя для выпадающего списка. |
| required | required | Указывает, что пользователь должен выбрать значение перед отправкой формы. |
| size | number | Определяет число видимых опций в выпадающем списке. |
Примеры:
В следующих примерах используется база данных AdventureWorksPDW2012.
A. Использование SELECT для получения строк и столбцов
В этом разделе приведены три примера кода. В ходе выполнения первого примера кода возвращаются все строки (предложение WHERE не указано), а также все столбцы (используется ) таблицы .
В этом примере для достижения такого же результата используется присвоение псевдонима таблице.
В ходе выполнения данного примера кода возвращаются все строки (предложение WHERE не задано) и подмножества столбцов (, , ) таблицы базы данных . Заголовок третьего столбца переименовывается в .
Этот пример возвращает только строки для , имеющие , не равное NULL, и , равное «M» (состоит в браке).
Б. Использование SELECT с заголовками столбцов и вычислениями
В следующем примере возвращаются все строки из таблицы и вычисляется заработная плата до вычетов для каждого сотрудника на основе их и с учетом 40-часовой рабочей недели.
Г. Использование GROUP BY
В следующем примере вычисляется общий объем всех продаж за каждый день.
Так как в запросе используется предложение , то выводится только одна строка, содержащая общий объем продаж по каждому дню.
Д. Использование GROUP BY с несколькими группами
В следующем примере вычисляются значения средней цены и суммы продаж через Интернет за каждый день, сгруппированные по дате заказа и ключу продвижения.
Е. Использование GROUP BY и WHERE
В следующем примере после извлечения строк, содержащих даты заказов позднее 1 августа 2002 г., происходит их разделение на группы.
Ж. Использование GROUP BY с выражением
В следующем примере производится группировка с помощью выражения. Группировку можно производить только с помощью выражения, не содержащего агрегатных функций.
Создаём гибридный селектСкопировать ссылку
При создании простого кастомного селекта мы, того не замечая, идём на компромисс. В частности, мы жертвуем функциональностью ради эстетики. Всё должно быть наоборот.
Что если вместо этого мы зададим нативный селект по умолчанию и заменим его более эстетичным, если это возможно? Вот тут и вступает в игру идея о гибридном селекте. Он гибридный, потому что состоит из двух селектов, каждый из которых показывается в нужный для него момент:
- Нативный селект, видимый и доступный по умолчанию.
- Кастомный селект, скрытый до тех пор, пока не произойдёт взаимодействие посредством мыши.
Начнём с разметки. Вначале, добавим нативный с несколькими до кастомного. Чуть позже я объясню почему.
Любой контрол формы должен содержать лейбл. Мы можем прибегнуть к , но фокус будет попадать на нативный селект, когда мы будем кликать на подпись. В целях предотвращения такого поведения используем и свяжем его с селектом с помощью .
Наконец, с помощью нужно сообщить вспомогательным технологиям, чтобы те игнорировали кастомный селект. Таким образом, они видят только нативный селект, несмотря ни на что.
Это приводит нас к стилизации, в ходе которой мы не только заставляем всё выглядеть красивее, но также и управляем переключением между селектами. Нам не хватает лишь пары строк, чтобы начать магию.
Для начала, оба селекта должны обладать одинаковой шириной и высотой. Это позволит пользователям не увидеть серьезного расхождения с макетом при переключении.
Вот два селекта. Но лишь один может устанавливать пространство, которое они занимают. Второй должен быть спозиционирован абсолютно, чтобы быть вне потока документа. Давайте провернём это с кастомным селектом, так как замена производится только тогда, когда она возможна. Мы спрячем его по умолчанию, чтобы никто пока до него не добрался.
Вот здесь-то и начинается веселье. Нам нужно определить, использует ли пользователь устройство, в котором наведение — часть основного ввода информации. Например, компьютер с мышью. Хотя мы и думаем о медиавыражениях только как о способе проверки определённых функций или же инструменте адаптивности на брейкпоинтах, их также можно использовать для обнаружения поддержки ховера с помощью , который поддерживается всеми основными браузерами. Итак, давайте используем это для отображения кастомного селекта на устройствах, где можно навести курсор.
Отлично. Но что насчёт людей, которые используют клавиатуру для навигации даже на устройствах, поддерживающих ховер? Что делать? Мы будем прятать кастомный селект, когда нативный находится в состоянии фокуса. Мы можем поймать соседний элемент с помощью комбинирующего селектора . Как только нативный селект в фокусе, прячем кастомный, который следует сразу за ним в DOM. Вот почему кастомный селект должен следовать за нативным.
Вот и всё! Трюк переключения между двумя селектами готов. Есть другие способы сделать это через CSS, но и этот прекрасно работает.
Наконец, нам нужно немного JavaScript. Добавим несколько обработчиков событий:
- Один для события клика, по которому в игру вступает кастомный селект, раскрываясь и показывая варианты выбора.
- Один, чтобы синхронизировать выбранные варианты. При изменении одного варианта выбора, меняется и второй.
- И ещё один для установки навигации через клавиатуру с помощью клавиш Up и Down, выбора варианта с помощью клавиш Enter или Space, и закрытия списка через Esc.
Атрибуты¶
- Устанавливает, что список получает фокус после загрузки страницы.
- Блокирует доступ и изменение элемента.
- Связывает список с формой.
- Позволяет одновременно выбирать сразу несколько элементов списка.
- Имя элемента для отправки на сервер или обращения через скрипты.
- Список обязателен для выбора перед отправкой формы.
- Количество отображаемых строк списка.
Также для этого элемента доступны универсальные атрибуты.
autofocus
Атрибут устанавливает, что список получает фокус после загрузки страницы, при этом список становится доступным для выбора пунктов, например, с помощью клавиатуры.
Синтаксис
Значения
Нет.
Значение по умолчанию
По умолчанию этот атрибут выключен.
disabled
Блокирует доступ и изменение элементов списка. Блокированный список не может получить фокус через курсор или клавиатуру, быть изменён, значение такого списка не передаётся на сервер.
Синтаксис
Значения
Нет.
Значение по умолчанию
По умолчанию этот атрибут выключен.
form
Связывает список с формой по её идентификатору. Такая связь необходима в случае, когда список располагается за пределами .
Синтаксис
Значения
Идентификатор формы (значение атрибута элемента ).
Значение по умолчанию
Нет.
multiple
Наличие атрибута сообщает браузеру отображать содержимое элемента как список множественного выбора. Конечный вид списка зависит от используемого атрибута и браузера.
Для выбора нескольких значений списка применяются клавиши Ctrl и Shift совместно с курсором мыши.
Чтобы на сервер отправлялся массив данных, значение атрибута следует писать с квадратными скобками — , к примеру.
Синтаксис
Значения
Нет.
Значение по умолчанию
По умолчанию этот атрибут выключен.
name
Определяет уникальное имя элемента . Как правило, это имя используется для доступа к данным через скрипты или для получения выбранного значения списка на сервере.
Синтаксис
Значения
В качестве имени используется набор символов, включая числа и буквы. JavaScript чувствителен к регистру, поэтому при обращении к элементу по имени соблюдайте ту же форму написания, что и в атрибуте .
Значение по умолчанию
Нет.
required
Устанавливает список обязательным для выбора перед отправкой формы на сервер. Если пункт списка не выбран, браузер выведет сообщение, а форма отправлена не будет. Вид и содержание сообщения зависит от браузера и меняться пользователем не может.
Синтаксис
Значения
Нет.
Значение по умолчанию
По умолчанию атрибут выключен.
size
Устанавливает высоту списка. Если значение атрибута равно 1, то список превращается в раскрывающийся. При добавлении атрибута к элементу при список отображается как «крутилка». Во всех остальных случаях получается список с одним или множественным выбором.
Синтаксис
Значения
Любое целое положительное число.
Значение по умолчанию
Зависит от атрибута . Если он присутствует, то размер списка равен количеству элементов. Когда атрибута нет, то по умолчанию значение атрибута равно 1.
Описание команды SELECT
Основой всех синтаксических конструкций, начинающихся с ключевого слова SELECT, является синтаксическая конструкция “табличное выражение”.
Семантика табличного выражения состоит в том, что на основе последовательного применения разделов FROM, WHERE, GROUP BY и HAVING из заданных в разделе FROM таблиц строится некоторая новая результирующая таблица, порядок следования строк которой не определен и среди строк которой могут находиться дубликаты (т.е. в общем случае таблица-результат табличного выражения является мультимножеством строк).
Наиболее общей является конструкция “спецификация курсора”. Курсор — это понятие языка SQL, позволяющее с помощью набора специальных операторов получить построчный доступ к результату запроса к БД. К табличным выражениям, участвующим в спецификации курсора, не предъявляются какие- либо ограничения. При определении спецификации курсора используются три дополнительных конструкции: спецификация запроса, выражение запросов и раздел ORDER BY.
В спецификации запроса задается список выборки (список арифметических выражений над значениями столбцов результата табличного выражения и констант). В результате применения списка выборки к результату табличного выражения производится построение новой таблицы, содержащей то же число строк, но вообще говоря другое число столбцов, содержащих результаты вычисления соответствующих арифметических выражений из списка выборки.
Выражение запросов — это выражение, строящееся по указанным синтаксическим правилам на основе спецификаций запросов. Единственной операцией, которую разрешается использовать в выражениях запросов, является операция UNION (объединение таблиц) с возможной разновидностью UNION ALL.
Оператор выборки — это отдельный оператор языка SQL, позволяющий получить результат запроса в прикладной программе без привлечения курсора. Поэтому оператор выборки имеет синтаксис, отличающийся от синтаксиса спецификации курсора, и при его выполнении возникают ограничения на результат табличного выражения. Фактически, и то, и другое диктуется спецификой оператора выборки как одиночного оператора SQL: при его выполнении результат должен быть помещен в переменные прикладной программы. Поэтому в операторе появляется раздел INTO, содержащий список переменных прикладной программы, и возникает то ограничение, что результирующая таблица должна содержать не более одной строки.
В диалекте SQL СУБД Oracle поддерживается расширенный вариант оператора выборки, результатом которого не обязательно является таблица из одной строки. Такое расширение не поддерживается ни в SQL/89, ни в SQL/92.
Подзапрос — запрос, который может входить в предикат условия выборки оператора SQL.
Кстати, данную статью Вы можете найти в интернете по запросам:
Команда SELECT, Синтаксис команды SELECT, Описание команды SELECT.
- SELECT
- Команда SELECT
- SQL SELECT
- Синтаксис команды SELECT
- Описание команды SELECT







