Практические решения закрытия сайта или его части от индексации
Содержание:
- Запрещаем индексацию сайта
- Пять причин для запрета индексации!
- Работа с файлом robots.txt
- Закрываем от индексации домен/поддомен:
- Рекомендации
- Страницы сайта
- Внутренние ссылки
- Инструкция по изменению файла robots.txt
- Методы, с которыми нужно работать осторожно:
- Польза метатега robots и X-Robots-Tag для SEO
- Действующие правила robots.txt
- Распространенная ошибка
- Ошибки использования robots и X-Robots-Tag
Запрещаем индексацию сайта
Для того, что бы полностью запретить индексацию сайта, необходимо, что бы при обращении к нему робот получал запрет в виде инструкции. Сделать это можно двумя способами.
При помощи robots.txt
Это наиболее распространенный и менее трудозатратный способ. Для того, что бы полностью закрыть сайт необходимо прописать в файле robots.txt простую инструкцию:
User-agent: * Disallow: /
Таким образом вы запрещаете индексацию для любой поисковой системы. Но есть возможность запрета и для конкретного поисковика, к примеру, Яндекса.
User-agent: Yandex Disallow: /
Подробнее о синтаксисе и работе с файлом robots.txt — https://dh-agency.ru/category/vnutrennyaya-optimizaciya/robots-txt/
При помощи тэгов
Так же, существует способ закрыть свой сайт при помощи специального тэга. Он будет «говорить» индексирующему роботу при обращении к странице, что ее загружать не надо.
<meta name=»robots» content=»noindex»>
Данный тэг необходимо разместить на каждой странице Вашего сайта.
Параметр поля «name» зависит от робота, к которому Вы обращаетесь. К примеру, если речь идет о роботе Google, то данный тэг будет выглядеть следующим образом:
<meta name=»googlebot» content=»noindex»>
О том, какие значения может принимать параметр «content», читайте .
Пять причин для запрета индексации!
- Полное индексирование создаёт лишнюю нагрузку на ваш сервер.
- Отнимает драгоценное время самого робота.
- Пожалуй это самое главное, некорректная информация может быть неправильно интерпретирована поисковыми системами. Это приведет к неправильному ранжированию статей и страниц, а в последствии и к некорректной выдаче в результатах поиска.
- Папки с шаблонами и плагинами содержат огромное количество ссылок на сайты создателей и рекламодателей. Это очень плохо для молодого сайта, когда на ваш сайт ссылок из вне еще нет или очень мало.
- Индексируя все копии ваших статей в архивах и комментариях, у поисковика складывается плохое мнение о вашем сайте. Много дублей. Много исходящих ссылок Поисковая машина будет понижать ваш сайт в результатах поиска в плоть до фильтра. А картинки, оформленные в виде отдельной статьи с названием и без текста, приводят робота просто в ужас. Если их очень много, то сайт может загреметь под фильтр АГС Яндекса. Мой сайт там был. Проверено!
Теперь после всего сказанного возникает резонный вопрос: «А можно ли как то запретить индексировать то что не надо?». Оказывается можно. Хотя бы не в приказном порядке, а в рекомендательном. Ситуация не полного запрета индексации некоторых объектов возникает из-за файла sitemap.xml, который обрабатывается после robots.txt. Получается так: robots.txt запрещает, а sitemap.xml разрешает. И всё же решить эту задачу мы можем. Как это сделать правильно сейчас и рассмотрим.
Файл robots.txt для wordpress по умолчанию динамический и реально в wordpress не существует. А генерируется только в тот момент, когда его кто-то запрашивает, будь это робот или просто посетитель. То есть если через FTP соединение вы зайдете на сайт, то в корневой папке файла robots.txt для wordpress вы там просто не найдете. А если в браузере укажите его конкретный адрес http://название_вашего_сайта/robots.txt, то на экране получите его содержимое, как будто файл существует. Содержимое этого сгенерированного файла robots.txt для wordpress будет такое:
User-agent: *
В правилах составления файла robots.txt по умолчанию разрешено индексировать всё. Директива User-agent: * указывает на то, что все последующие команды относятся ко всем поисковым агентам ( * ). Но далее ничего не ограничивается. И как вы понимаете этого не достаточно. Мы с вами уже обсудили папок и записей, имеющих ограниченный доступ, достаточно много.
Чтобы можно было внести изменения в файл robots.txt и они там сохранились, его нужно создать в статичном постоянном виде.
Работа с файлом robots.txt
Скрыть весь информационный портал или его часть можно, создав пустой документ в формате txt и дав ему название robots. Файл надо поместить в корневую папку сайта. Читать подробнее о robots.txt.
Чтобы закрыть сайт от всех поисковых систем, в документе надо прописать следующее:
Проверить изменения можно, набрав в адресной строке название домена.ru/robots.txt. Если браузер покажет ошибку 404, то документ находится не корневой папке ресурса.
Скрыть отдельную папку поможет следующая команда:
Закрыть определенный файл можно, указав в команде путь к нему:
Обращение к другим поисковым системам
Для запрета индексации веб-сайта другими поисковиками, в редактируемом файле в строке user-agent после двоеточия надо указывать имена их поисковых роботов:
- у Yahoo робот Slurp;
- у Спутника — SputnikBot;
- у Bing — MSNBot.
Закрытие поддомена
Заблокировать поддомен, можно, открыв robots.txt в корневой папке поддомена и указав в robots.txt следующее:
Если нужного файла нет, его следует создать самостоятельно.
Закрываем от индексации домен/поддомен:
Для того, чтобы закрыть от индексации домен, можно использовать:
1. Robots.txt
В котором прописываем такие строки.
User-agent: *
Disallow: /
При помощи данной манипуляции мы закрываем сайт от индексации всеми поисковыми системами.
При необходимости Закрыть от индексации конкретной поисковой системой, можно добавить аналогичный код, но с указанием Юзерагента.
User-agent: yandex
Disallow: /
Иногда, же бывает нужно наоборот открыть для индексации только какой-то конкретной ПС. В таком случае нужно составить файл Robots.txt в таком виде:
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
Таким образом мы позволяем индексировать сайт только однайо ПС. Однако минусом есть то, что при использовании такого метода, все-таки 100% гарантии не индексации нет. Однако, попадание закрытого таким образом сайта в индекс, носит скорее характер исключения.
Для того, чтобы проверить корректность вашего файла Robots.txt можно воспользоваться данным инструментом просто перейдите по этой ссылке http://webmaster.yandex.ru/robots.xml.
Статья в тему: Robots.txt — инструкция для SEO
2. Добавление Мета-тега Robots
Также можно закрыть домен от индексации при помощи Добавления к Код каждой страницы Тега:
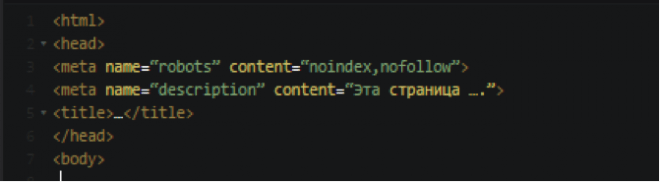
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Куда писать META-тег “Robots”
Как и любой META-тег он должен быть помещен в область HEAD HTML страницы:
Данный метод работает лучше чем Предыдущий, темболее его легче использовать точечно нежели Вариант с Роботсом. Хотя применение его ко всему сайту также не составит особого труда.
3. Закрытие сайта при помощи .htaccess
Для Того, чтобы открыть доступ к сайту только по паролю, нужно добавить в файл .htaccess, добавляем такой код:

После этого доступ к сайту будет возможен только после ввода пароля.
Защита от Индексации при таком методе является стопроцентной, однако есть нюанс, со сложностью просканить сайт на наличие ошибок. Не все парсеры могут проходить через процедуру Логина.
Рекомендации
Не рекомендуется исключать фиды:
Потому что наличие открытых фидов требуется, например, для Яндекс Дзен, когда нужно подключить сайт к каналу (спасибо комментатору «Цифровой»). Возможно открытые фиды нужны где-то еще.
Фиды имеют свой формат в заголовках ответа, благодаря которому поисковики понимают что это не HTML страница, а фид и, очевидно, обрабатывают его иначе.
-
Прописывание Sitemap после каждого User-agent
Это делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt. -
Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Однако подобные советы я находил даже в статье с пафосным названием «Самые правильный robots для WordPress 2018»! Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше (Версия 2). -
Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика -
Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей. -
Ляпы
Некоторые правила я могу отнести только к категории «блогер не подумал». Например: Disallow: /20 — по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше
-
Закрывать от индексации страницы пагинации
Это делать не нужно. Для таких страниц настраивается тег , таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса. -
Комментарии
Некоторые ребята советуют закрывать от индексирования комментарии и . -
Открыть папку uploads только для Googlebot-Image и YandexImages
User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/
Совет достаточно сомнительный, т.к. для ранжирования страницы необходима информация о том, какие изображения и файлы на ней размещены.
Страницы сайта
Для успешного продвижения важно не только избавиться от лишней информации на страницах, но и очистить поисковый индекс сайта от малополезных мусорных страниц.
Во-первых, это ускорит индексацию основных продвигаемых страниц сайта. Во-вторых, наличие в индексе большого числа мусорных страниц будет негативно влиять на оценку сайта и его продвижение
Сразу перечислим страницы, которые целесообразно прятать:
– страницы оформления заявок, корзины пользователей;
– результаты поиска по сайту;
– личная информация пользователей;
– страницы результатов сравнения товаров и подобных вспомогательных модулей;
– страницы, генерируемые фильтрами поиска и сортировкой;
– страницы административной части сайта;
– версии для печати.
Рассмотрим способы, которыми можно закрыть страницы от индексации.
Закрыть в robots.txt
Это не самый лучший метод.
Во-первых, файл robots не предназначен для борьбы с дублями и чистки сайтов от мусорных страниц. Для этих целей лучше использовать другие методы.
Во-вторых, запрет в файле robots не является гарантией того, что страница не попадёт в индекс.
Вот что Google пишет об этом в своей справке:

Работе с файлом robots.txt посвящена статья в блоге Siteclinic «Гайд по robots.txt: создаём, настраиваем, проверяем».
Метатег noindex
Чтобы гарантированно исключить страницы из индекса, лучше использовать этот метатег.
Рекомендации по синтаксису у Яндекса и Google отличаются.
Ниже приведём вариант метатега, который понимают оба поисковика:
<meta name="robots" content="noindex, nofollow">
Важный момент!
Чтобы Googlebot увидел метатег noindex, нужно открыть доступ к страницам, закрытым в файле robots.txt. Если этого не сделать, робот может просто не зайти на эти страницы.
Выдержка из рекомендаций Google:

Заголовки X-Robots-Tag
Существенное преимущество такого метода в том, что запрет можно размещать не только в коде страницы, но и через корневой файл .htaccess.
Этот метод не очень распространён в Рунете. Полагаем, основная причина такой ситуации в том, что Яндекс этот метод долгое время не поддерживал.
В этом году сотрудники Яндекса написали, что метод теперь поддерживается.

Ответ поддержки подробным не назовёшь))). Прежде чем переходить на запрет индексации, используя X-Robots-Tag, лучше убедиться в работе этого способа под Яндекс. Свои эксперименты на эту тему мы пока не ставили, но, возможно, сделаем в ближайшее время.
Подробные рекомендации по использованию заголовков X-Robots-Tag от Google.
Защита с помощью пароля
Этот способ Google рекомендует, как наиболее надёжный метод спрятать конфиденциальную информацию на сайте.

Если нужно скрыть весь сайт, например, тестовую версию, также рекомендуем использовать именно этот метод. Пожалуй, единственный недостаток – могут возникнуть сложности в случае необходимости просканировать домен, скрытый под паролем.
Исключить появление мусорных страниц c помощью AJAX
Речь о том, чтобы не просто запретить индексацию страниц, генерируемых фильтрами, сортировкой и т. д., а вообще не создавать подобные страницы на сайте.
Например, если пользователь выбрал в фильтре поиска набор параметров, под которые вы не создавали отдельную страницу, изменения в товарах, отображаемых на странице, происходит без изменения самого URL.
Сложность этого метода в том, что обычно его нельзя применить сразу для всех случаев. Часть формируемых страниц используется для продвижения.
Например, страницы фильтров. Для «холодильник + Samsung + белый» нам нужна страница, а для «холодильник + Samsung + белый + двухкамерный + no frost» – уже нет.
Поэтому нужно делать инструмент, предполагающий создание исключений. Это усложняет задачу программистов.
Использовать методы запрета индексации от поисковых алгоритмов
«Параметры URL» в Google Search Console
Этот инструмент позволяет указать, как идентифицировать появление в URL страниц новых параметров.

Директива Clean-param в robots.txt
В Яндексе аналогичный запрет для параметров URL можно прописать, используя директиву Clean-param.
Почитать об этом можно .
Канонические адреса, как профилактика появления мусорных страниц на сайте
Этот метатег был создан специально для борьбы с дублями и мусорными страницами на сайте. Мы рекомендуем прописывать его на всём сайте, как профилактику появления в индексе дубле и мусорных страниц.
Инструменты точечного удаления страниц из индекса Яндекса и Google
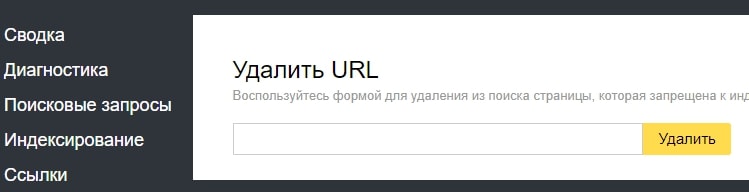
Если возникла ситуация, когда нужно срочно удалить информацию из индекса, не дожидаясь, пока ваш запрет увидят поисковые работы, можно использовать инструменты из панели Яндекс.Вебмастера и Google Search Console.
В Яндексе это «Удалить URL»:
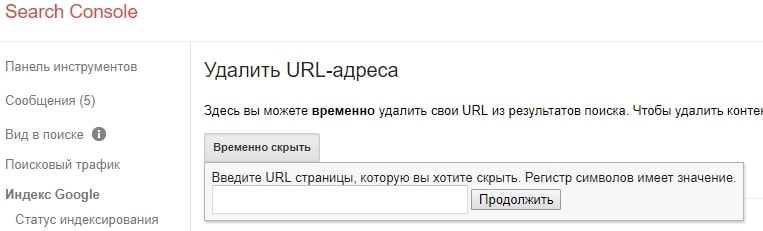
В Google Search Console «Удалить URL-адрес»:
Внутренние ссылки
Внутренние ссылки закрываются от индексации для перераспределения внутренних весов на основные продвигаемые страницы. Но дело в том, что:
– такое перераспределение может плохо отразиться на общих связях между страницами;
– ссылки из шаблонных сквозных блоков обычно имеют меньший вес или могут вообще не учитываться.
Рассмотрим варианты, которые используются для скрытия ссылок:
Для скрытия ссылок этот тег бесполезен. Он распространяется только на текст.

Атрибут rel=”nofollow”
Сейчас атрибут не позволяет сохранять вес на странице. При использовании rel=”nofollow” вес просто теряется. Само по себе использование тега для внутренних ссылок выглядит не особо логично.
Представители Google рекомендуют отказаться от такой практики.
Рекомендацию Рэнда Фишкина:

Скрытие ссылок с помощью скриптов
Это фактически единственный рабочий метод, с помощью которого можно спрятать ссылки от поисковых систем. Можно использовать Аjax и подгружать блоки ссылок уже после загрузки страницы или добавлять ссылки, подменяя скриптом тег на
При этом важно учитывать, что поисковые алгоритмы умеют распознавать скрипты
Как и в случае с контентом – это «костыль», который иногда может решить проблему. Если вы не уверены, что получите положительный эффект от спрятанного блока ссылок, лучше такие методы не использовать.
Инструкция по изменению файла robots.txt
Мы не ставим целью дать подробную инструкцию по всем
способам подключения к хостингу или серверу, укажем самый простой способ на наш
взгляд.
Файл robots.txt всегда находится в корне Вашего сайта.
Например, robots.txt сайта iqad.ru будет
находится по адресу:
Для подключения к сайту, мы должны в административной панели
нашего хостинг провайдера получить FTP (специальный протокол передачи файлов
по сети) доступ: <ЛОГИН> И <ПАРОЛЬ>.
Авторизуемся в панели управления вашим хостингом и\или сервером, находим раздел FTP и создаем ( получаем ) уникальную пару логин \ пароль.
В описании
раздела или в разделе помощь, необходимо
найти и сохранить необходимую информацию для подключения по FTP к серверу,
на котором размещены файлы Вашего сайта. Данные отражают информацию, которую
нужно указать в FTP-клиенте:
- Сервер (Hostname) – IP-адрес сервера, на котором размещен Ваш аккаунт
- Логин (Username) – логин от FTP-аккаунта
- Пароль (Password) – пароль от FTP-аккаунта
- Порт (Port) – числовое значение, обычно 21
Далее, нам потребуется любой FTP-клиент, можно
воспользоваться бесплатной программой filezilla (https://filezilla.ru/).
Вводим данные в соответствующие поля и нажимаем подключиться.
FTP-клиент filezilla интуитивно прост и понятен: вводим cервер (host) + логин (имя пользователя) + пароль + порт и кнопка {быстрое соединение}. В поле справа находим файл robots.txt и изменяем его. Не забудьте сохранить изменения.
После подключения прописываем необходимые директивы. См.
раздел:
Методы, с которыми нужно работать осторожно:
Также существует достаточно грубый метод Закрытия чего — либо от роботов, а именно запрет на уровне сервера на доступ робота к конкретному контенту.
1. Блокируем все запросы от нежелательных User Agents
Это правило позволяет заблокировать нежелательные User Agent, которые могут быть потенциально опасными или просто перегружать сервер ненужными запросами.
В данному случае плохим ботом можно указать Любую поисковую машину, парсер либо что либо еще.
Подобные техники используются например для скрытия от робота Ахрефса ссылки с сайта, который был создан/сломан, чтобы конкуренты сеошники не увидели истинных источников ссылочной массы сайта.
Однако это метод стоит использовать если вы точно знаете, что хотите сделать и здраво оцениваете последствия от этих действий.
Использование HTTP-заголовка X-Robots-Tag
Заголовок X-Robots-Tag, выступает в роли элемента HTTP-заголовка для определенного URL. Любая директива, которая может использоваться в метатеге robots, применима также и к X-Robots-Tag.
В X-Robots-Tag перед директивами можно указать название агента пользователя. Пример HTTP-заголовка X-Robots-Tag, который запрещает показ страницы в результатах поиска различных систем:
Польза метатега robots и X-Robots-Tag для SEO
Рассмотрим, когда стоит использовать данные теги и как это помогает оптимизировать сайт.
1. Управление индексацией страниц
Не все страницы сайта полезны для привлечения органического трафика. Индексация некоторых из них, например, дублей, может и вовсе навредить видимости ресурса. Поэтому с помощью команды noindex обычно скрывают:
- дубликаты страниц;
- страницы сортировки и фильтров;
- страницы поиска и пагинации;
- служебные и технические страницы;
- сервисные сообщения для клиентов (об успешной регистрации, заказе и т.д.);
- посадочные страницы для рекламных кампаний и тестирования гипотез;
- страницы в процессе наполнения и разработки (лучше закрывать паролем);
- информацию, которая пока не актуальна (будущая акция, запуск новинки, анонсы запланированных мероприятий);
- устаревшие и неэффективные страницы, которые не приносят трафик;
- страницы, которые нужно закрыть от некоторых видов ботов.
2. Управление индексацией файлов определенного формата
От робота можно скрывать не только html-страницы, но и документ с другим расширением, например, страницу изображения или pdf-файл.
3. Сохранение веса страницы
Запрещая роботам переходить по ссылкам с помощью команды nofollow, можно сохранить вес страницы — он не будет передаваться сторонним ресурсам или другим страницам сайта, которые не приоритетны для индексации.
4. Рациональный расход краулингового бюджета
Чем больше ресурс, тем важнее направлять робота только на самые важные страницы. Если поисковики будут сканировать все подряд, краулинговый бюджет исчерпается до того, как робот начнет сканировать ценный для пользователей и SEO-контент. Соответственно, эти страницы не попадут в индекс или окажутся там с опозданием.
Действующие правила robots.txt
User-Agent
У каждой поисковой системы есть свои «агенты пользователя». По сути, это имя краулера, которое помогает дать определённые указания конкретному ему.
Если брать шире, то User-Agent — клиентское приложение на стороне поисковой системы, в некотором смысле имитирующее браузер или, например, мобильное устройство.
Примеры:
-
— символ астериск используются для обозначения сразу же всех краулеров.
-
— основной краулер Яндекс-поиска.
-
— робот поиска Google по картинкам.
-
— краулер сервиса Ahrefs.
Важно: если в файле указаны правила для конкретных User-Agent, то роботы будут следовать только своим инструкциям, игнорируя общие правила. В примере ниже краулер DuckDukcGo сможет сканировать папки сайта и , несмотря на астериск («звёздочку»), отвечающий за инструкции всем роботам
В примере ниже краулер DuckDukcGo сможет сканировать папки сайта и , несмотря на астериск («звёздочку»), отвечающий за инструкции всем роботам.
User-agent: *
Disallow /tmp/
Disallow /api/
User-agent DuckDuckBot
Disallow /duckhunt/
Disallow
Директива, которая позволяет блокировать от индексации полностью весь сайт или определённые разделы.
Может быть полезно для закрытия от сканирования служебных, динамических или временных страниц (символ отвечает за комментарии в коде и игнорируется краулерами).
User-agent: *
# Закрываем раздел /cms и все файлы внутри
Disallowcms
# Закрываем папку /images/resized/ (сами изображения разрешены к сканированию)
Disallow /api/resized
Упростить инструкции помогают операторы:
-
— любая последовательность символов в URL. По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *.
-
— символ в конце URL-адреса, он используется чтобы отменить использование * на конце правила.
User-agent: *
# Закрываем URL, начинающиеся с /photo после домена. Например:
# /photos
# /photo/overview
Disallowphoto
# Закрываем все URL, начинающиеся с /blog/ после домена и заканчивающиеся /stats/
Disallow /blog/*/stats$
Важно: в robots.txt не нужно закрывать JS и CSS-файлы, они понадобятся поисковым роботом для правильного отображения (рендеринга) контента
Allow
С помощью этой директивы можно, напротив, разрешить каталог или конкретный адрес к индексации. В некоторых случаях проще запретить к сканированию весь сайт и с помощью Allow открыть нужные разделы.
User-agent: *
# Блокируем весь раздел /admin
Disallowadmin
# Кроме файла /admin/css/style.css
Allow /admin/cssstyle.css
# Открываем все файлы в папке /admin/js. Например:
# /admin/js/global.js
# /admin/js/ajax/update.js
Allow /admin/js
Также Allow можно использовать для отдельных User-Agent.
# Запрещаем доступ к сайту всем роботам
User-agent: *
Disallow
# Кроме краулера Яндекса
User-agent: Yandex
Allow
Crawl-delay
Директива, теряющая актуальность в случае Goolge, но полезная для работы с другими поисковиками.
Позволяет замедлить сканирование, если сервер бывает перегружен. Устанавливает интервал времени для обхода страниц в секундах (для Яндекса). Чем выше значение, тем медленнее краулер ходит по сайту.
User-agent: *
Crawl-delay 5
Несмотря на то, что Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Интересно, что китайский Baidu также не обращает внимание на Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт только один раз
Важно: если установлено высокое значение Crawl-delay, убедитесь, что ваш сайт своевременно индексируется. В сутках 86 400 секунд, при будет просканировано не более 2880 страниц в день, что мало для крупных сайтов
В сутках 86 400 секунд, при будет просканировано не более 2880 страниц в день, что мало для крупных сайтов
Важно: если установлено высокое значение Crawl-delay, убедитесь, что ваш сайт своевременно индексируется. В сутках 86 400 секунд, при будет просканировано не более 2880 страниц в день, что мало для крупных сайтов
Sitemap
Одно из ключевых применений robots.txt в SEO — указание на расположение карты сайты
Обратите внимание, используется полный URL-адрес (их может быть несколько)
Sitemap https//www.example.com/sitemap.xml
Sitemap https//www.example.com/blog-sitemap.xml
Нужно иметь в виду:
-
Директива Sitemap указывается с заглавной S.
-
Sitemap не зависит от инструкций User-Agent.
-
Нельзя использовать относительный адрес карты сайта, только полный URL.
-
Файл XML-карты сайта должен располагаться на том же домене.
Также убедитесь, что ссылка возвращает статус без редиректов. Проверить можно с помощью инструмента, определяющего ответ сервера или анализа XML-карты сайта.
Распространенная ошибка
Установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже выяснили, при указании директивы User-Agent, соответствующий краулер будет следовать только тем правилам, что установлены именно для него. Не забывайте дублировать общие директивы для всех User-Agent.
В примере ниже — слегка измененный robots.txt сайта IMDB. Общие правила Disallow не будут распространяться на бот ScoutJet. А вот Crawl-delay, напротив, установлена только для него.
# отредактированная версия robots.txt сайта IMDB
#
# Задержка интервала сканирования для ScouJet
#
User-agentScouJet
Crawl-delay 3
#
#
#
# Все остальные
#
User-agent: *
Disallowtvschedule
DisallowActorSearch
DisallowActressSearch
DisallowAddRecommendation
Disallow /ads/
DisallowAlternateVersions
DisallowAName
DisallowAwards
DisallowBAgent
Disallow /Ballot/
#
#
Sitemap https//www.imdb.com/sitemap_US_index.xml.gz
Противоречия директив
Общее правило — если две директивы противоречат друг другу, приоритетом пользуется та, в которой большее количество символов.
User-agent: *
# /admin/js/global.js разрешён к сканированию
# /admin/js/update.js по-прежнему запрещён
Disallowadmin
Allow /admin/jsglobal.js
Может показаться, что файл попадает под правило блокировки содержащего его раздела . Тем не менее, он будет доступен для сканирования, в отличие от всех остальных файлов в каталоге.
Ошибки использования robots и X-Robots-Tag
Несогласованность с файлом robots.txt
В официальных справках по X-Robots-Tag и метатегу robots в Google и Яндексе сказано, что у поискового робота должен быть доступ к сканированию контента, который нужно скрыть из индекса. В этом случае указание директивы disallow для определенной страницы в файле robots.txt делает невидимыми директивы страницы, в том числе запрещающие индексацию.
Еще одной ошибкой является попытка запретить индексацию страниц с помощью robots.txt. Основная функция robots.txt — в ограничении сканирования, а не запрете индексации. Следовательно, для управления отображением страниц в поиске нужно использовать метатег robots и тег x-robots.
Несвоевременное удаление атрибута noindex с актуальной страницы
Если вы используете директиву noindex, чтобы временно скрыть контент из индекса, важно вовремя удалить ее со страницы и открыть роботу доступ. Например, это может быть страница с запланированным акционным предложением, которое уже вступило в силу
Или же станица, которая была в процессе разработки и теперь полностью готова. Если директиву не убрать, страница не появится в выдаче, а значит не будет генерировать трафик.
Наличие обратных ссылок на страницу с атрибутом nofollow
Команда nofollow может не сработать, если сама страница — не единственный способ для поисковика узнать об URL-адресах, и на них ведут внешние ссылки с «открытых» источников.
Удаление URL-адреса из карты сайта до его деиндексации
Если страница содержит директиву noindex или отдает запрет индексации URL, стоит ли ее удалить из файла sitemap.xml? Такое решение будет неверным, поскольку карта сайта дает роботу возможность быстрее находить все страницы, в том числе те, которые нужно убрать из индекса.
Правильным решением будет создать отдельный файл sitemap.xml со списком страниц, содержащих директивы noindex, и удалять URL оттуда по мере их деиндексации. Чтобы ускорить процесс обхода дополнительной карты сайта роботом, можно загрузить ее в Google Search Console или Яндекс.Вебмастер.
Отсутствие проверки индексации после внесения изменений
При самостоятельной настройке индексации или в ходе работы программиста бывают ситуации, когда важный контент ошибочно оказался под запретом индексации. После внесения изменений страницы сайта нужно проверять.
Как избежать ошибочной деиндексации важных страниц?
Кроме проверки индексации URL указанными выше способами, можно отследить изменения кода на сайте с помощью инструмента «Отслеживание изменений» в SE Ranking.

Как быть, если актуальная страница перестала отображаться в поиске?
Необходимо удалить директивы, запрещающие индексацию страницы, а также проверить, нет ли запрета ее сканирования командой disallow в robots.txt и указан ли ее адрес в файле sitemap. Запросить индексацию URL, а также уведомить поисковики об обновленной карте сайта можно через Яндекс.Вебмастер и Google Search Console.
Больше информации можно найти в статье о принципах индексации сайта в поисковиках.







