Семантическое ядро: сервисы для автоматического сбора запросов
Содержание:
- Виды поисковых запросов
- Запросы общего характера:
- Вызовы
- Анализ конкуренции запросов для информационных сайтов
- Стоит ли заказывать СЯ у специалистов?
- Шаг 2. Собрать информационные запросы
- Сервисы для парсинга и кластеризации семантического ядра
- Сбор семантики для поиска и проработка минус-слов
- Программы для сбора СЯ
- Пример
- Как составить семантическое ядро?
Виды поисковых запросов
Все поисковые запросы можно разделить на виды, в том числе по объему их показов в поиске.
Информационные
По этим запросам люди ищут информацию о вещах и явлениях, отзывы о товарах, обзоры и прочее.
Примеры информационных запросов: «первые признаки беременности», «рецепт борща», «чем отстирать пятно» и т. д.
Такие запросы в первую очередь подходят для информационных (контентных) сайтов, которые как раз и отвечают на вопросы пользователей.
Информационные запросы можно использовать и для продвижения коммерческих проектов:
- они привлекают дополнительный трафик в корпоративные блоги;
- приводят пользователя в каталоги, по ссылкам из которых он будет переходить на разделы с товарами;
- помогают расширить объем релевантного контента;
- используются для рекламы продаваемых товаров или услуг в блоге.
Как правило, частотность (количество показов) информационных запросов может быть существенно выше, чем коммерческих. Это позволяет получать большой объем трафика на сайт. Однако такой трафик будет низко конвертируемым для коммерческих проектов.
Коммерческие запросы (транзакционные)
Эти запросы пользователи используют, когда хотят купить товар или получить услугу.
Например: «купить пылесос», «гастроэнтеролог запись на прием», «доставка пиццы».
Обычно в коммерческих запросах есть слова, которые так или иначе связаны с процессом покупки:
Витальные (навигационные, брендовые)
Витальные запросы пользователь вводит, когда его интересует сайт конкретной компании, бренда или проекта: «тинькофф», «авиасейлс», «сайт госуслуг».
Страницы этого сайта будут занимать первые строки выдачи.
Однако специально использовать навигационные запросы в продвижении не стоит, они и так окажутся в топе по соответствующим запросам.
Общие запросы
Общие, или неточные запросы, как правило, самые высокочастотные, но использовать их для поискового продвижения бессмысленно.
Мультимедийные (фото, видео, музыка)
Как и следует из названия, такие запросы пользователи вводят, когда ищут медийный контент. Причем он может быть из самых разных областей, например, человек хочет скоротать вечер («смотреть онлайн дом 2») или готовится к ремонту («ручная дрель фото»).
В таких фразах часто есть слова «фото», «аудио», «видео», «смотреть», «слушать», «скачать».
Геозависимые (ГЗ) и геонезависимые (ГНЗ) + город
Выдача по ГЗ запросам в разных регионах будет отличаться. При этом в них не содержится указание на географическую точку. Например, если вы, будучи в Новосибирске, наберете в поисковике фразу «заказать такси» или «записаться к зубному», то увидите местные сайты. А человек в Москве по такому же запросу – столичные.
ГЗ по большей части относятся к коммерческим запросам.
Геонезависимые запросы, напротив, не привязаны к географии и покажут одну и ту же выдачу, где бы не находился пользователь. Это может быть фраза «выращивание кактусов» или «космические полеты».
Любопытно, что ГНЗ включает и запросы, в которых есть прямое указание на регион. Например, по запросу «доставка цветов рязань» пользователь увидит практически идентичную выдачу, где бы он ни находился (и в Рязани, и нет).
Запросы по частоте показов
Частота, или частотность запросов – это один из важнейших показателей для SEO-продвижения. Он выражается числовым значением и показывает, сколько раз фраза была показана в поисковой системе за месяц (реже за другой промежуток времени).
По этому параметру запросы делятся на следующие виды:
- Высокочастотные, ВЧ – самые «популярные» запросы у пользователей, их вводят чаще всего. Работать с ними непросто, так как именно по ВЧ самая большая конкуренция. Также нужно учитывать, что в точном виде пользователи используют их гораздо реже, чем с уточнениями.
- Среднечастотные, СЧ – промежуточные по частоте фразы между ВЧ и НЧ.
- Низкочастотные, НЧ – узконаправленные фразы, которые точнее и подробнее всего показывают потребность пользователя. Конкуренция по ним низкая, поэтому есть неплохие шансы попасть по НЧ в топ выдачи. Кроме того, продвижение по низкочастотным запросам занимает меньше времени, чем по СЧ и ВЧ.
Пример:
| Запрос | Вид | Частота | “Частота” | “!Частота” |
|---|---|---|---|---|
| беременность | ВЧ | 9782207 | 17683 | 15612 |
| признаки беременности | СЧ | 316203 | 24925 | 24032 |
| беременность первые дни после зачатия признаки ощущения | НЧ | 88 | 9 | 9 |
Видим, что СЧ запрос в точном виде спрашивают больше, чем ВЧ.
Запросы общего характера:
Трудно определить к какому виду относятся данные запросы — они могут быть как транзакционными, так и информационными. Например:
- «Микроскоп»,
- «Покраска забора»,
- «Летние шорты».
Если взглянуть на эти запросы, то не совсем понятными становятся мотивы людей, вводящих эти запросы. В примере с микроскопом не понятно ищут ли информацию о том, как он устроен, какие модели есть, либо же хотят его купить. С покраской забора тоже не ясно, либо человек ищет информацию о том, как покрасить потолок, либо ищет фирму занимающуюся покраской. То же самое и с летними шортами — либо их хотят купить, либо хотят посмотреть на модные тенденции.
При составлении семантического ядра для своего сайта, всегда учитывайте специфику вашей будущей аудитории.
Вызовы
Некоторые из проблем Семантической паутины включают обширность, расплывчатость, неопределенность, непоследовательность и обман. Автоматизированным системам рассуждений придется иметь дело со всеми этими проблемами, чтобы выполнить обещания Семантической паутины.
- Обширность: Всемирная паутина содержит много миллиардов страниц. SNOMED CT медицинская терминология онтология одна содержит 370.000 класса имен, и существующая технология до сих пор не в состоянии устранить все семантически дублирующих терминов. Любая автоматизированная система рассуждений должна будет иметь дело с действительно огромными входными данными.
- Расплывчатость: это неточные понятия, такие как «молодой» или «высокий». Это происходит из-за нечеткости пользовательских запросов, концепций, представленных поставщиками контента, сопоставления условий запроса с условиями поставщика и попытки комбинировать различные базы знаний с частично совпадающими, но слегка разными концепциями. Нечеткая логика — самый распространенный метод борьбы с неопределенностью.
- Неопределенность: это точные концепции с неопределенными значениями. Например, у пациента может быть набор симптомов, соответствующих ряду различных диагнозов, каждый с разной вероятностью. Вероятностные методы рассуждения обычно используются для устранения неопределенности.
- Несогласованность: это логические противоречия, которые неизбежно возникнут при разработке больших онтологий и при объединении онтологий из разных источников. Дедуктивное рассуждение катастрофически терпит неудачу, когда сталкивается с непоследовательностью, потому что «все следует из противоречия» . Разрешаемое рассуждение и непоследовательное рассуждение — это два метода, которые можно использовать для устранения непоследовательности.
- Обман: это когда производитель информации намеренно вводит в заблуждение потребителя информации. В настоящее время для устранения этой угрозы используются методы криптографии . Предоставляя средства для определения целостности информации, в том числе той, которая связана с идентификацией лица, которое произвело или опубликовало информацию, однако вопросы достоверности все еще необходимо решать в случаях потенциального обмана.
Этот список проблем является скорее иллюстративным, чем исчерпывающим, и он фокусируется на вызовах уровням «объединяющей логики» и «доказательства» Семантической паутины. Итоговый отчет Группы инкубаторов Консорциума World Wide Web (W3C) по обоснованию неопределенности для World Wide Web (URW3-XG) объединяет эти проблемы под одним заголовком «неопределенность». Многие из упомянутых здесь методов потребуют расширения языка веб-онтологий (OWL), например, для аннотирования условных вероятностей. Это область активных исследований.
Анализ конкуренции запросов для информационных сайтов
Собрав запросы и почистив их теперь нам надо проверить их конкуренцию, чтобы понимать в дальнейшем — какими запросами надо заниматься в первую очередь.
Конкуренция по количеству документов, title, главных страниц
Это все легко снимается через KEI в KeyCollector.Получаем данные по каждому запросу, сколько документов найдено в поисковой системе, в нашем пример в Яндексе. Сколько главных страниц в выдаче по этому запросу и вхождений запроса в заголовок.
В интернете можно встретить различные формулы расчета этих показателей, даже вроде в свежем установленном KeyCollector по стандарту встроена какая-то формула расчета KEI. Но я им не следую, потому что надо понимать что каждый из этих факторов имеет разный вес. Например, самый главный, это наличие главных страниц в выдаче, потом уже заголовки и количество документов
Навряд ли эту важность факторов, как то можно учесть в формуле и если все-таки можно то без математика не обойтись, но тогда уже эта формула не сможет вписаться в возможности KeyCollector
Конкуренция по биржам ссылок
Здесь уже интереснее. У каждой биржи свои алгоритмы расчета конкуренции и можно предположить, что они учитывают не только наличие главных страниц в выдаче, но и возраст страниц, ссылочную массу и другие параметры. В основном эти биржи конечно же рассчитаны на коммерческие запросы, но все равно более менее какие то выводы можно сделать и по информационным запросам.
Собираем данные по биржам и выводим средние показатели и уже ориентируемся по ним.Я обычно собираю по 2-3 биржам. Главное чтобы все запросы были собраны по одним и тем же биржам и выведено среднее число только по ним. А не так, что какие то запросы собрали одними биржами, а другие другими и вывели среднее.
Для более наглядного вида можно применить формулу KEI, которая покажет стоимость одного посетителя исходя из параметров бирж:
KEI = AverageBudget / ( AverageTraffic +0.01)
Средний бюджет по биржам делить на средний прогноз трафика по биржам, получаем стоимость одного посетителя исходя из данных бирж.
Конкуренция по мутаген
Сервис мутаген создан специально для анализа конкуренции информационных запросов. Работает с 2011 года, принцип алгоритма не разглашается, но вполне себе годно рассчитывает. Конкуренция рассчитывается по 25 баллам. Чем больше балл, тем больше конкуренция: 1-7 низкая конкуренция, 8-15 средняя, 16 и выше, высокая. Сервис платный, но в день можно чекать 10 запросов бесплатно. Тут сразу показываются просмотры по вордстату, ключи хвосты, клики в яндекс директ.В KeyCollector есть возможность массового сбора по мутаген.
Выводы: Если у вас бюджет ограничен то вы можете использовать первые два способа проверки конкуренции в совокупности, если готовы тратиться на анализ, то можно использовать только Мутаген или Оверлид.
Стоит ли заказывать СЯ у специалистов?
По большому счету специалисты по составлению семантического ядра сделают вам только шаги 1 – 3 из нашей схемы. Иногда, за большую дополнительную плату, сделают и шаги 4-5 – (сбор хвостов и проверку конкурентности запросов).
После этого они выдадут вам несколько тысяч ключевых запросов, с которыми вам дальше надо будет работать.
И вопрос тут в том, собираетесь ли вы писать статьи самостоятельно, или наймете для этого копирайтеров. Если вы хотите делать упор на качество, а не на количество – то надо писать самим. Но тогда вам будет недостаточно просто получить список ключей. Вам надо будет выбрать те темы, в которых вы разбираетесь достаточно хорошо, чтобы написать качественную статью.
И вот тут встает вопрос – а зачем тогда собственно нужны специалисты по СЯ? Согласитесь, распарсить базовый ключ и собрать точные частотности (шаги #1-3) – это совсем не сложно. У вас уйдет на это буквально полчаса времени.
Самое сложное – это именно выбрать ВЧ запросы, у которых низкая конкуренция. А теперь еще, как выясняется, надо ВЧ-НК, на которые вы можете написать хорошую статью. Вот именно это займет у вас 99% времени работы над семантическим ядром. И этого вам не сделает ни один специалист. Ну и стОит ли тратиться на заказ таких услуг?
Когда услуги специалистов по СЯ полезны
Другое дело, если вы изначально планируете привлекать копирайтеров. Тогда вам необязательно разбираться в теме запроса. Копирайтеры ваши тоже не будут в ней разбираться. Они просто возьмут несколько статей по этой теме, и скомпилируют из них “свой” текст.
Такие статьи будут пустыми, убогими, почти бесполезными. Но их будет много. Самостоятельно вы сможете писать максимум 2-3 качественные статьи в неделю. А армия копирайтеров обеспечит вам 2-3 говнотекста в день. При этом они будут оптимизированы под запросы, а значит будут привлекать какой-то трафик.
В этом случае – да, спокойно нанимайте специалистов по СЯ. Пусть они вам еще и ТЗ для копирайтеров составят заодно. Но сами понимаете, это тоже будет стоить отдельных денег.
Шаг 2. Собрать информационные запросы
Начинаем со сбора информационных запросов.
Берем запросы со словами:
- как;
- какой;
- как выбрать;
- почему;
- зачем;
- и просто информационные — «Какой велосипед выбрать ребенку».
Не берем запросы с коммерческими словами:
Купить велосипед ребенку
С какими сервисами работать
Вручную через Wordstat с помощью плагина Wordstat Assistant. Регион не выбираем, потому что нам нужны только геонезависимые запросы.

Получилась семантика для статьи, например:

Так выглядит неполное и неправильное СЯ (смешали информационные и коммерческие запросы — разный интент):
Чем еще можно собирать семантику:
Keys.so — смотрим топ в выдаче по нужной теме, отправляем в сервис 2-3 адреса из топа. После парсинга получим большой список ключей, который нужно очистить от лишних запросов.
Key Collector — собирает обширное СЯ
- полное СЯ;
- собирает автоматически;
Но получится много мусора: нужно чистить, зато собирает максимально много ключей, точно ничего не пропустите.
Дорабатываем семантику в Key Collector
Когда собрали все ключи, используя key-collector:
- снимаем частотность БЕЗ указания региональности;
- убираем всё лишнее и запросы с низкой частотностью (0).

Сервисы для парсинга и кластеризации семантического ядра
Для сбора и кластеризации семантики есть много платных и бесплатных инструментов. Мы уже упоминали несколько сервисов и сейчас остановимся на них подробнее.
Key Collector
Автоматизированный сервис для подбора семантического ядра. Умеет собирать ключи через «Яндекс.Вордстат», парсить поисковые подсказки, выгружать данные с Google Ads и сервисов аналитики, чистить семантику от стоп-слов, дублей и сезонных запросов, делать фильтрацию по частотности. Частотность Key Collector собирает в Yandex Direct, Google Ads, LiveInternet, Rambler Adstat и APIShop.com.
Главные достоинства Key Collector — разнообразные источники парсинга, большая глубина сбора, возможность группировки собранной базы. Из минусов SEO специалисты отмечают медленную работу, особенно при увеличенной глубине сбора, и необходимость покупки антикапч.
Интерфейс Key Collector
Программа платная, работает по лицензии. Стоимость лицензии зависит от статуса покупателя: физическому лицу бессрочная лицензия обойдется в 2 200 рублей, организации придется заплатить 2 300 рублей.
MOAB.Tools Семантика
Это онлайн-сервис, который парсит до четырех миллионов фраз в час и собирает для семантического ядра запросы из Wordstat и подсказок, в том числе запросы с длинным полным хвостом спецификаторов. При поиске нет проблем с капчей, можно выбрать регионы, найти ультранизкочастотные запросы и интегрировать результат с Key Collector. Удобно, что сервис сразу проверяет частотность.
Работа парсера MOAB.Tools
Инструмент платный, но в тарифе Free первые 5 000 фраз можно собрать бесплатно. Тариф Mini стоит 1 299 рублей и рассчитан на ядро до 50 000 фраз. Для крупных проектов разработан тариф Pro, с которым за 6 099 рублей можно найти до 500 000 фраз.
«Словоеб»
Сервис позиционируется как бесплатная альтернатива Key Collector. У программы похожий интерфейс и принцип работы, но возможности парсинга ограничены результатами «Вордстат», Rambler.Adstat и поисковыми подсказками «Яндекс» и Google. Частотность фраз программа тоже проверяет только по «Вордстат».
Работа программы «Словоеб»
По сути, «Словоеб» выполняет базовую работу по сбору семантики в «Яндекс.Вордстат», но в автоматическом режиме. За 10-15 минут он собирает несколько тысяч запросов, что в разы быстрей ручного сбора.
Yandex Wordstat Assistant
Браузерное расширение для упрощения работы с «Вордстат». Бесплатный сервис, который копирует и сохраняет ключевые слова из «Яндекс.Вордстат» в таблицы Excel. Умеет сортировать запросы по частотности, алфавиту или порядку добавления. Автоматически ищет дубли и позволяет добавлять ключи вручную.
Составление семантического ядра с помощью браузерного расширения
Расширение бесплатное, устанавливается для Google Chrome, Opera, Mozilla Firefox и «Яндекс.Браузер».
Serpstat
Мультиинструментальный сервис для работы с семантическим ядром, кластеризации и SEO анализа.
Интерфейс сервиса Serpstat
При сборе семантики учитывает частотность и конкурентность запросов по шкале от 1 до 100, показывает сложность продвижения. Может работать с региональной выдачей и сравнивать результаты с сайтами конкурентов. Особенно удобно, что Serpstat группирует ключевые слова по страницам и рекламным кампаниям с учетом однородности.
У сервиса есть бесплатная версия с ограниченным функционалом. Подписки оформляются на месяц или год. Самая недорогая стоит 55$ в месяц.
Rush Analytics
Сервис автоматизации парсинга и кластеризации семантического ядра. Собирает запросы и показывает их частотность на основе данных «Яндекс.Вордстат» и Google Ads, ищет подсказки в «Яндекс», Google и YouTube. Умеет кластеризовать ключевые слова методом Soft и Hard, автоматически создает структуру сайта.
Интерфейс Rush Analytics
Бесплатная версия с ограниченным функционалом доступна семь дней. Минимальный тариф стоит 500 рублей в месяц.
Готовое ядро выглядит как электронная таблица, где по каждой ключевой фразе указана базовая (по всем вариантам использования ключевого слова) и точная (без словоформ) частотность, а для каждого кластера — продвигаемая страница.
Данные в таком формате можно сразу использовать для SEO и контекстной рекламы:
- Разрабатывать или оптимизировать структуру сайта.
- Отбирать перспективные запросы с низкой стоимостью клика и запускать контекстную рекламу с дешевым целевым трафиком.
- Составлять контент-план на несколько лет или месяцев.
- Делать технические задания для контентного наполнения или оптимизации текущего контента.
Сбор семантики для поиска и проработка минус-слов
Чтобы такой крупный объем работы был выполнен четко, необходимо планировать сбор. Правила, по которым он будет осуществляться, нужно разработать перед началом работ и следовать им на всех этапах реализации. Зафиксируйте их в документации по проекту — таким образом вы сможете избежать неточностей на этапе исполнения.
Правила для сбора семантики
Перед началом сбора определите структуру рекламных кампаний в вашем аккаунте, то есть принципы, по которым вы будете группировать слова. Эффективнее и удобнее подбирать слова, отдельно собирая ключи по выделенным сегментам. То есть единовременно подбирать фразы только для одной рекламной кампании. Это избавляет от лишней сортировки ключевых слов. Чтобы следовать этому совету, используйте при подборе маски, которые очерчивают границы сегментов.
Если даже 41 страницы выдачи Вордстата не хватает для сбора семантики до нужной частоты, то собирайте ключи не по общей маске, а дробите ее по направлениям внутри рекламной кампании.
Например, маска для подбора транзакционных запросов:
(купить|покупка|покупать|заказ|заказать|цена|стоимость|дешево|недорого|бюджетный|дорогой|дорого|выгодно|интернет|спецпредложения|специальные предложения|акции|скидки|распродажа|спец предложения|недорогой|сколько стоит|продажа|кредит)
Рекомендуем заранее определить, будете ли вы собирать фразы с такими словами, как «отзывы», «обзор», «сравнение», «характеристики», «фотографии», «самостоятельно» и т. п. Запросы с этими словами в большинстве тематик являются информационными. Нужны ли они в вашем случае, зависит от маркетинговых и бизнес-задач клиента, возможного охвата рекламной кампании. Внесите правило относительно таких запросов в проектную документацию.
Заранее определите, до какой частотности будете собирать семантику. Понимая особенности рекламного размещения и бюджета, ограничьте глубину проработки семантического ядра. При этом не забывайте о статусе «Мало показов» в рекламных системах. Не имеет смысла тратить время на сбор запросов, которые вводятся 1-3 раза в месяц.
Автоматизируйте сбор статистики. Самый простой инструмент — расширение для браузера Yandex Wordstat Assistant. Оно позволяет быстро добавлять в список нужные ключевые слова от руки и из выдачи Вордстата, копировать их с частотностью или без. Расширение подходит для сбора небольших или средних списков ключей.
Еще один популярный инструмент — Key Collector. Он помогает значительно сэкономить время специалистов, автоматически собирая ключевые слова по настроенным маскам, исключая фразы с указанными минус-слова. При этом система также собирает слова только до 42 страницы Вордстата, поэтому при слишком общем начальном запросе и широком гео можно не достичь нужной частоты.
Мини-лайфхак для Вордстата. Иногда, когда нужно добавить в строку запроса часто встречающееся минус-слово, сервис возвращает вас на первую страницу выдачи. Очень неудобно в этом случае возвращаться туда, где вы остановились при подборе слов. Решение простое: поставьте номер нужной страницы в ссылке сверху, и вы сразу перенесетесь на нее.

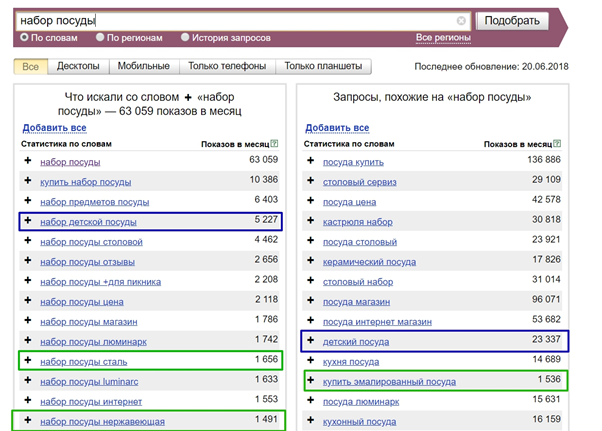
Просмотрите первые несколько страниц выдачи Вордстата и все нерелевантные слова добавьте в качестве минус-слов в список и в поисковую строку. Так вы исключите из семантики самые частотные минус-слова.
Когда семантика уже собрана, ее необходимо очистить от оставшихся нецелевых запросов. Это можно сделать несколькими способами:
в Excel — с помощью фильтров находить ключевые фразы, содержащие нецелевое слово, и удалять их разом;
с помощью надстройки SEO-Excel. Функция «Словарь» разбивает список ключевых фраз на отдельные слова, указывая их словоформы и частоту. Можно пробежаться глазами по списку слов и выделить нецелевые
Важно помнить, что слова вырваны из контекста и минусовать нужно только те, что в любом случае сгенерируют нецелевые запросы;
Key Collector также позволяет из семантики удалять все фразы с нерелевантным словом в один клик.
После того как кампании будут запущены, семантику нужно пополнять реальными запросами из товарных рекламных кампаний Яндекса и Google, их можно найти в отчетах по поисковым запросам.
Программы для сбора СЯ
Есть много инструментов, платных и бесплатных, которые помогают как собрать, так и кластеризовать. Рассмотрим, как создать семантическое ядро с помощью них.
Key Collector
Он подойдет профессионалам, потому что платный. Сервис собирает СЯ, парсит подсказки, удаляет ненужные с помощью стоп-слов, фильтрует и ищет неявные дубли. Это многофункциональный инструмент, который экономит время.
SlovoEB
Бесплатная программа, которая является аналогией предыдущей. Часть задач она может выполнять самостоятельно, часть — нет. Для использования нужно вводить почту Яндекса, однако сам поисковик может заблокировать за большое число обращений.
Yandex Wordstat
Бесплатный сервис, который показывает статистику словосочетаний за месяц, данные в регионе, динамику и сезонность. С помощью него можно подобрать основные ключи для построения СЯ.
Google Keyword Planner
Он подходит для поиска с учетом пользователей Гугла. Он ищет новые запросы, создает статистику, прогнозирует трафик и предлагает новые комбинации.
Serpstat
Небесплатный сервис, которые анализирует ваши ключевые фразы и подбирает СЧ, НЧ. В нем можно задать географию, получая информацию с Яндекса и Гугла.
Mutagen
Хороший инструмент, который определяет конкуренцию запроса. Однако как именно он это делает — неизвестно, потому что разработчики не раскрывают эту информацию, и проверить это нельзя.
Keyword Tool
Альтернативный инструмент Планировщику от Гугла, разработчики презентуют его лучшую альтернативу. Часть версий бесплатны, а за профессиональный функционал придется доплатить.
Он ищет ключи в Гугле, Амазоне, Ютубе и других англоязычных сервисах, поэтому его часто используют для сбора иностранной семантики.
Just Magic
Недорогое дополнение, которое помогает работать с СЯ. В нем есть расширения для парсинга, а также Акварель Генератор — уникальная разработка, которая собирает LSI-ключевики. Это помогает увеличить релевантность текста.
Pixel Tools
Крупный дорогой инструмент. В нем множество дополнений, которые помогают SEO-специалисту, однако часть из них доступны безвозмездно. Показывает данные по геозависимости, коммерциализации и локализации.
Ahrefs
Платное дополнение, которое помогает с анализом обратных ссылок. Можно посмотреть примерное СЯ конкурентов, трафик и относительные запросы пользователей.
С помощью всех рекомендаций и программ вы только на практике поймете, как собрать семантику и ключевые слова для сайта.
Пример
В следующем примере текст «Пауль Шустер родился в Дрездене» на веб-сайте будет снабжен аннотацией, связывающей человека с местом его рождения. Следующий фрагмент HTML показывает, как описывается небольшой граф в RDFa -синтаксисе с использованием словаря schema.org и идентификатора Викиданных :
<div vocab="https://schema.org/" typeof="Person">
<span property="name">Paul Schuster</span> was born in
<span property="birthPlace" typeof="Place" href="https://www.wikidata.org/entity/Q1731">
<span property="name">Dresden</span>.
</span>
</div>

График, полученный из примера RDFa
В примере определены следующие пять троек (показаны в синтаксисе Turtle ). Каждая тройка представляет одно ребро в результирующем графе: первый элемент тройки ( субъект ) — это имя узла, с которого начинается ребро, второй элемент ( предикат ) — тип ребра, а последний и третий элемент ( объект ) либо имя узла, на котором заканчивается край, либо буквальное значение (например, текст, число и т. д.).
Результатом троек является график, показанный .
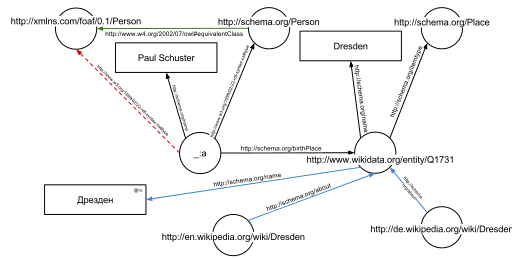 График, полученный из примера RDFa, обогащенный дополнительными данными из Интернета
График, полученный из примера RDFa, обогащенный дополнительными данными из Интернета
Одним из преимуществ использования универсальных идентификаторов ресурсов (URI) является то, что их можно разыменовать с помощью протокола HTTP . Согласно так называемым принципам связанных открытых данных , такой разыменованный URI должен приводить к документу, который предлагает дополнительные данные о данном URI. В этом примере всех идентификаторы URI, как для ребер и узлы (например , , ) может быть разыменовываются и приведет к дальнейшим графам RDF, описывающий URI, например , что Дрезден это город в Германии, или что человек, в том смысле , этот URI может быть вымышленным.
На втором графике показан предыдущий пример, но теперь он дополнен несколькими тройками из документов, которые являются результатом разыменования (зеленый край) и (синие края).
В дополнение к краям, явно указанным в задействованных документах, можно автоматически вывести края: тройной
из исходного фрагмента RDFa и тройной
из документа в (зеленый край на рисунке) позволяют вывести следующую тройку с учетом семантики OWL (красная пунктирная линия на втором рисунке):
Как составить семантическое ядро?
Выполните следующие шаги, чтобы создать семантическое ядро.
Детально изучите бизнес-модель компании
Это поможет найти основные смыслы и ключевые фразы, которые будут отражать деятельность и философию вашего бренда. Хорошо, если у вас уже сформирован бизнес-портфель и проведены маркетинговые исследования, ведь из них можно почерпнуть готовую информацию.
Добавьте в документ основные понятия, которые характеризуют вашу компанию. Это может быть, к примеру, ниша, в которой вы работаете, товары, которые производите или продаете, тип торговли — опт, розница и т.д. Можно подключить коллег для брейншторма и проработать этот шаг вместе.
На раннем этапе ваш список ключевиков может выглядеть так:
- шиномонтаж;
- СТО;
- шины;
- поменять шины;
- автосервис.
Расширьте семантическое ядро
Добавьте слова из своего списка в сервис «Яндекс. Вордстат» или Google Keyword Planner. Программа подберет дополнительные ключевики на основе тех, что вы подобрали ранее
Для локальных бизнесов очень важно указывать актуальную локацию, так как множество ключевиков привязаны к месту
Вот как может выглядеть расширенный список на этом этапе (он должен быть намного длиннее):
- шиномонтаж Одесса;
- шиномонтаж стоимость;
- шиномонтаж зима;
- автосервис стоимость;
- автосервис Ланос;
- поменять шины Одесса;
- СТО возле меня и т.д.
Еще один способ дополнить семантическое ядро — проанализировать ключевики на сайтах конкурентов. В тех же сервисах введите интересующие вас сайты и добавьте себе те релевантные ключевые слова и фразы, которых пока нет в вашей таблице.
Удалите лишние ключевики
Поскольку сбор ключевиков является во многом автоматизированным процессом и количество ключевых слов и фраз может быть большим, некоторые из них могут оказаться нерелевантными. Поэтому необходимо внимательно просмотреть список, убедиться в релевантности ключевиков и избавиться от тех, которые не соответствуют вашему бизнесу.
Чем аккуратнее и старательнее вы работаете на предыдущих этапах создания семантического ядра, тем меньше вероятность попадания нерелевантных ключевиков в ваш список.
Сгруппируйте запросы
Собранные ключевики необходимо разделить на группы — кластеры. Кластеризация ключевиков может иметь несколько уровней в зависимости от их частотности. Сгруппируйте высоко-, средне- и низкочастотные ключевые слова и фразы.
Приоритетом в кластеризации ключевиков должен быть баланс между высокочастотностью ключевиков (чем она выше, тем больше людей используют его в поиске) и конкурентностью (то, как много других сайтов используют ключевики). Высокочастотные ключевые слова и фразы зачастую имеют самую большую конкуренцию.
Хорошей идеей будет использовать самые высокочастотные и релевантные ключевики для лендингов и прочих продающих страниц, в продвижение которых вы будете вкладывать часть маркетингового бюджета. Менее популярные ключевики можно оставить для контентных страниц.
Теперь, когда ваше семантическое ядро готово и представляет из себя обширный список релевантных и сгруппированных тем и ключевиков, вам нужно отмечать в документе, как часто вы используете те или иные слова и фразы (с помощью упомянутых выше инструментов аналитики), а также время от времени расширять ядро за счет мониторинга деятельности конкурентов, анализа трендов и коллективных брейнштормов. Новые направления деятельности предприятия, товары и подходы также надо учитывать в семантическом ядре.
Давайте ознакомимся с факторами, которые формируют семантическое ядро.







