Как составить семантическое ядро без помощи специалиста
Содержание:
- Программы для сбора СЯ
- Виды и типы поисковых запросов: классификация
- Оценка стоимости продвижения запроса
- Проработка вглубь
- Правильное семантическое ядро
- Анализ конкуренции запросов для информационных сайтов
- Подключаем инструменты подбора семантики
- Сервисы для составления семантического ядра
- Как подобрать ключевые слова для SEO
- Сервисы для парсинга и кластеризации семантического ядра
- СЯ и поисковые алгоритмы: как это работает в 2021 году
Программы для сбора СЯ
Есть много инструментов, платных и бесплатных, которые помогают как собрать, так и кластеризовать. Рассмотрим, как создать семантическое ядро с помощью них.
Key Collector
Он подойдет профессионалам, потому что платный. Сервис собирает СЯ, парсит подсказки, удаляет ненужные с помощью стоп-слов, фильтрует и ищет неявные дубли. Это многофункциональный инструмент, который экономит время.
SlovoEB
Бесплатная программа, которая является аналогией предыдущей. Часть задач она может выполнять самостоятельно, часть — нет. Для использования нужно вводить почту Яндекса, однако сам поисковик может заблокировать за большое число обращений.
Yandex Wordstat
Бесплатный сервис, который показывает статистику словосочетаний за месяц, данные в регионе, динамику и сезонность. С помощью него можно подобрать основные ключи для построения СЯ.
Google Keyword Planner
Он подходит для поиска с учетом пользователей Гугла. Он ищет новые запросы, создает статистику, прогнозирует трафик и предлагает новые комбинации.
Serpstat
Небесплатный сервис, которые анализирует ваши ключевые фразы и подбирает СЧ, НЧ. В нем можно задать географию, получая информацию с Яндекса и Гугла.
Mutagen
Хороший инструмент, который определяет конкуренцию запроса. Однако как именно он это делает — неизвестно, потому что разработчики не раскрывают эту информацию, и проверить это нельзя.
Keyword Tool
Альтернативный инструмент Планировщику от Гугла, разработчики презентуют его лучшую альтернативу. Часть версий бесплатны, а за профессиональный функционал придется доплатить.
Он ищет ключи в Гугле, Амазоне, Ютубе и других англоязычных сервисах, поэтому его часто используют для сбора иностранной семантики.
Just Magic
Недорогое дополнение, которое помогает работать с СЯ. В нем есть расширения для парсинга, а также Акварель Генератор — уникальная разработка, которая собирает LSI-ключевики. Это помогает увеличить релевантность текста.
Pixel Tools
Крупный дорогой инструмент. В нем множество дополнений, которые помогают SEO-специалисту, однако часть из них доступны безвозмездно. Показывает данные по геозависимости, коммерциализации и локализации.
Ahrefs
Платное дополнение, которое помогает с анализом обратных ссылок. Можно посмотреть примерное СЯ конкурентов, трафик и относительные запросы пользователей.
С помощью всех рекомендаций и программ вы только на практике поймете, как собрать семантику и ключевые слова для сайта.
Виды и типы поисковых запросов: классификация
Очень важно разобраться в классификации поисковых запросов. И это не пустая теоретическая вода — это то, что поможет понять, какие именно нам нужны запросы и почему, чтобы не хвататься за нецелевые и неэффективные
-
Традиционная классификация поисковых запросов:
- Навигационные — поиск конкретного сайта или сервиса, например, «риа новости».
- Информационные — поиск информации как таковой, например, «как готовить борщ».
- Транзакционные — поиск чего-либо с целью осуществить какое-либо действие «купить утюг».
- Общие — запросы, которые могут быть как информационными, так и транзакционными, например, «машины».
-
Виды поисковых запросов:
- Конкуренция: высосоконкурентные (ВК), среднеконкурентные (СК) и низкоконкурентные (НК) — насколько сложно продвинуться по этому запросу.
- Частотность: высокочастотные (ВЧ), среднечастотные (СК) и, не поверите, низкочастотные (НЧ) — сколько трафика можно получить с этого запроса.
- Коммерческие и информационные — является ли целью посетителя сделать ваш кошелек более тугим или нет.
- Геозависимые и геонезависимые — относится ли запрос к какому-то конкретному региону или нет.
- Сезонные и внесезонные — имеются ли у частотности запроса циклические колебания, повторяющиеся из года в год.
Что же нам нужно? Если отложить в сторону показатель конкурентности, с которым и так всё понятно, то легче всего продвигать геозависимые информационные запросы (если, конечно, вы продвигаете в регионе, к которому они относятся), а сложнее всего — геонезависимые коммерческие. Геопривязку можно определить через программу Key Collector, сервис SeoPult или же ручками, схема к чем я в одном из следующих материалов.
Определение геопривязки через SeoPult
Примеры геозапросов:
«Куда сходить» — геозависимый информационный запрос.
«Натяжные потолки калькулятор онлайн» — геонезависимый коммерческий запрос.
Высокочастотные запросы нам пока особо не требуются — они по умолчанию высококонкурентны, но если вы нашли высокочастотный низкоконкурентный ключ, то напишите мне — с меня чай с печеньками 🙂
Но мы поступимся высокочастотными запросами не потому, что сложно продвинуть, а потому что те средства и силы, которые мы затратим на продвижение ВЧ будут несоизмеримо больше, чем в случае с сотней НЧ или нескольких десятков СЧ, а трафика будет больше (эффект длинного хвоста). Неэффективно, одним словом. График распределения частот между типами запросов:
Нет-нет, это не значит, что в СЯ не должно быть ВЧ, просто не нужно биться лбом об стенку и бросать на них все силы. По мере подтягивания к топу НЧ и СЧ и прокачке тематических характеристик хоста в целом, ВЧ тоже будут ползти к заветной десятке.
В общем и целом, в своё семантическое ядро мы в первую очередь подбираем геозависимые НЧ и СЧ c как можно меньшей конкурентностью. И лишь затем, на будущее, приправляем его геонезависимыми и высокочастотными.
Для информационного сайта, соответственно, нужные информационные геозависимые запросы, а для коммерческого — коммерческие геозависимые и частично информационные, которые, по логике, могут привести не только зевак, но и клиентов — «как выбрать то-то», «характеристики того-то» и т.д.
Подробнее о типах поисковых запросов: https://pingoblog.ru/21-tipy-poiskovyh-zaprosov.html
Оценка стоимости продвижения запроса
После того, как Вы откорректировали список, убрав слова с малой частотой, необходимо проверить, какие ресурсы (в основном денежные) необходимо затратить, чтобы продвинуть целевые страницы в поисковых системах. Оценить стоимость продвижения можно исходя из ссылочной стоимости каждого ключевого слова по seo-агрегаторам (например, Rookee, SeoPult). Воспользуемся инструментами сервис SeoPult и посмотрим, какие ключевые слова следует исключить в связи с большими затратами на продвижение.
Работать в этом seo-агрегаторе можно только зарегистрированным пользователям. Поэтому проходим регистрацию и добавляем новый проект (рисунок 12).
Рисунок 12. Начинаем новый проект в сервисе SeoPult
Если Вы работаете над созданием семантического ядра веб-ресурса, которого еще нет в индексе поисковых систем, в поле url сайта введите адрес любого проиндексированного сайта. Главное в таком случае, чтобы выбранный вами сайт относился к тому же региону, для которого мы проверяли частотность ключевых слов.
На следующей странице нашего проекта необходимо правильно добавить ключи, выбрать количество позиций в топе и нажать кнопку для подсчета прогнозируемой стоимости одного перехода с поисковых систем (рисунок 13).
Рисунок 13. Действия для подсчета бюджета по ключевым словам ядра
На рисунке видно, что ряд ключевых запросов имеют большую стоимость перехода, по сравнению с другими словами. Это говорит о том, что эти запросы являются высококонкурентными в своей тематике. Поэтому и требуют таких вложений для успешного продвижения внешними ссылками. Для целевых страниц с низкочастотными ключевиками подойдут слова со стоимостью не больше 5-10 рублей за клик. Обычно хватает грамотной внутренней перелинковки и пару внешних ссылок, чтобы эти страницы попали в топ-10.
Просмотрев таким образов все ключевые слова из списка масок, следует сгруппировать высоко- средне- и низкоконкурентные запросы исходя из цифр ссылочной стоимости фразы. Теперь у Вас есть готовое семантическое ядро сайта. Осталось выбрать целевые страницы для продвижения, наполнить страницы уникальным контентом, провести их оптимизацию и проиндексировать в поисковых системах.
Выводы
Давайте подытожим вышесказанное — у нас получится краткий мануал по составлению семантического ядра:
- Анализируем тематику сайта. Такой анализ позволяет создать первоначальный список слов, которые описывают тематику и направление деятельности Вашего сайта.
- Дополняем первоначальный список различными дополнительными словами (синонимы, термины, морфологические изменения слов и т.д.)
- Составляем правильный список запросов.
- Производим зачистку семантического ядра, исключая слова-пустышки и ключевые слова, у которых число показов в месяц меньше заданной величины.
- Оцениваем стоимость продвижения каждого ключевого слова, формируя списки ключей с разной конурентностью.
На этом наша небольшая практика в подборе ключевых слов для ядра завершена. Как видите, составление семантического ядра является хоть и трудоемким, но не сложным делом. Главное — это выработать свой четкий план, сделать свой мануал и придерживаться его.
Где можно заказать отличное семантическое ядро?
Если же у Вас нет времени на сбор полноценного ядра, я с удовольствием помогу это сделать.
Проработка вглубь
Вот мы и собрали весь список возможных дополнений к нашим базовым ключам, что же делать дальше? А дальше нужно подготовить список ключевых фраз для еще большей проработки вглубь — поиска запросов со всеми возможными уточнениями.
Необходимо по очереди скомпоновать между собой ключи из разных столбцов, «перемножить» их друг с другом, получив все возможные комбинации. В решении этого вопроса помогут специальные программы, например, генератор фраз PPC-help. Вставляем наши ключи из столбцов таблицы Excel и получаем готовый список ключевых фраз, которые позже мы используем для парсинга в KeyCollector:
 Генерация фраз в программе PPC-help
Генерация фраз в программе PPC-help
Таким образом, мы собрали семантическое ядро для дальнейшего парсинга. Потратьте еще немного времени и проверьте весь список ключевых фраз. Все ли они соответствуют вашей тематике? Все ли они описывают ваши услуги или продукты? Если есть лишние, удалите их, это сэкономит много времени в будущем.
Список готов? Приступайте к парсингу в Key Collector. Это незаменимый инструмент в работе специалиста по контекстной рекламе. Он значительно упрощает процесс создания семантического ядра, собирая запросы на основе загруженных масок ключевых фраз.
Запускайте программу, загружайте ключи, не забудьте выбрать целевой регион и ждите результатов. Помните, что после получения списка из Key Collector необходимо избавиться от дублей типа «доставка цветы москва» и «москва цветы доставка», чтобы в дальнейшем исключить конкуренцию внутри кампании. Также нужно удалить нецелевые запросы, по которым мы не хотим рекламироваться, сохранив при этом список минус-слов в отдельный файл
В финале важно провести кластеризацию, разбив фразы на тематические группы. Все это удобно делать прямо в Key Collector
Как видим, сбор семантического ядра является трудоемким и затратным по времени процессом, но важным этапом создания кампании, поскольку от качества семантики напрямую зависит успешность рекламы, а значит, и финансовая отдача.
Удачных вам рекламных кампаний!
Правильное семантическое ядро
Прежде всего, необходимо определиться с понятиями «ключевые слова», «ключи», «ключевые или поисковые запросы» – это слова или фразы, при помощи которых потенциальные клиенты вашего сайта ищут необходимую информацию.
При работе со списками ориентируйтесь на КЗ из договора по продвижению, структуру веб-ресурса, информацию, прайс-листы, сайты-конкуренты, опыт предшествующего SEO.
Приступайте к подбору семантики путем смешения выбранных на предыдущем шаге словосочетаний, используя ручной метод или при помощи сервисов.
Сформируйте список стоп-слов и удалите неподходящие КЗ.
Сгруппируйте КЗ по релевантным страницам. Под каждый ключ подбирается наиболее релевантная страница или создается новый документ. Желательно данную работу проводить вручную. Для крупных проектов предусмотрены платные сервисы типа Rush Analytics.
Идите от большего к меньшему. Сначала распределите ВЧ по страницам. Затем то же самое проделайте с СЧ. НЧ можно добавить к страницам с распределенными по ним ВЧ и НЧ, а также подобрать для них индивидуальные страницы.
После анализа первых результатов работ мы можем увидеть, что:
- продвигаемый сайт не виден по всем заявленным ключевым словам;
- по КЗ выдаются не те документы, которые вы предполагали релевантными;
- мешает неправильная структура веб-ресурса;
- для некоторых КЗ релевантны несколько веб-страниц;
- не хватает релевантных страниц.
При группировке КЗ работайте со всеми возможными разделами на веб-ресурсе, наполняйте каждую страницу полезной информацией, не создавайте дублированный текст.
Анализ конкуренции запросов для информационных сайтов
Собрав запросы и почистив их теперь нам надо проверить их конкуренцию, чтобы понимать в дальнейшем — какими запросами надо заниматься в первую очередь.
Конкуренция по количеству документов, title, главных страниц
Это все легко снимается через KEI в KeyCollector.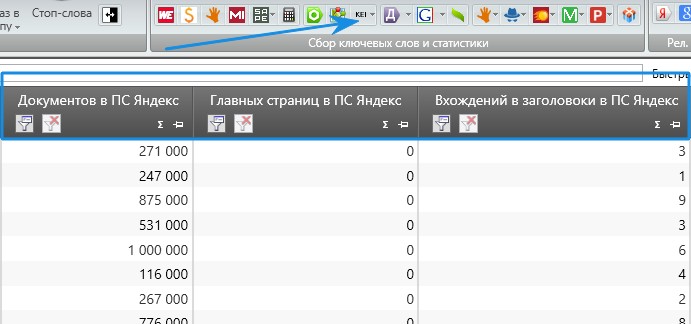 Получаем данные по каждому запросу, сколько документов найдено в поисковой системе, в нашем пример в Яндексе. Сколько главных страниц в выдаче по этому запросу и вхождений запроса в заголовок.
Получаем данные по каждому запросу, сколько документов найдено в поисковой системе, в нашем пример в Яндексе. Сколько главных страниц в выдаче по этому запросу и вхождений запроса в заголовок.
В интернете можно встретить различные формулы расчета этих показателей, даже вроде в свежем установленном KeyCollector по стандарту встроена какая-то формула расчета KEI. Но я им не следую, потому что надо понимать что каждый из этих факторов имеет разный вес. Например, самый главный, это наличие главных страниц в выдаче, потом уже заголовки и количество документов
Навряд ли эту важность факторов, как то можно учесть в формуле и если все-таки можно то без математика не обойтись, но тогда уже эта формула не сможет вписаться в возможности KeyCollector
Конкуренция по биржам ссылок
Здесь уже интереснее. У каждой биржи свои алгоритмы расчета конкуренции и можно предположить, что они учитывают не только наличие главных страниц в выдаче, но и возраст страниц, ссылочную массу и другие параметры. В основном эти биржи конечно же рассчитаны на коммерческие запросы, но все равно более менее какие то выводы можно сделать и по информационным запросам.
Собираем данные по биржам и выводим средние показатели и уже ориентируемся по ним.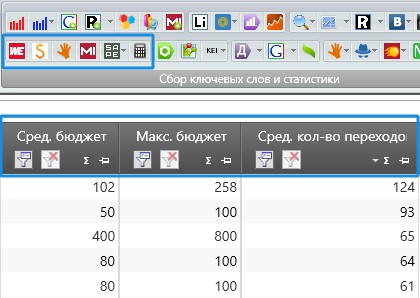 Я обычно собираю по 2-3 биржам. Главное чтобы все запросы были собраны по одним и тем же биржам и выведено среднее число только по ним. А не так, что какие то запросы собрали одними биржами, а другие другими и вывели среднее.
Я обычно собираю по 2-3 биржам. Главное чтобы все запросы были собраны по одним и тем же биржам и выведено среднее число только по ним. А не так, что какие то запросы собрали одними биржами, а другие другими и вывели среднее.
Для более наглядного вида можно применить формулу KEI, которая покажет стоимость одного посетителя исходя из параметров бирж:
KEI = AverageBudget / ( AverageTraffic +0.01)
Средний бюджет по биржам делить на средний прогноз трафика по биржам, получаем стоимость одного посетителя исходя из данных бирж.
Конкуренция по мутаген
Сервис мутаген создан специально для анализа конкуренции информационных запросов. Работает с 2011 года, принцип алгоритма не разглашается, но вполне себе годно рассчитывает. Конкуренция рассчитывается по 25 баллам. Чем больше балл, тем больше конкуренция: 1-7 низкая конкуренция, 8-15 средняя, 16 и выше, высокая. Сервис платный, но в день можно чекать 10 запросов бесплатно. Тут сразу показываются просмотры по вордстату, ключи хвосты, клики в яндекс директ. В KeyCollector есть возможность массового сбора по мутаген.
В KeyCollector есть возможность массового сбора по мутаген.
Выводы: Если у вас бюджет ограничен то вы можете использовать первые два способа проверки конкуренции в совокупности, если готовы тратиться на анализ, то можно использовать только Мутаген или Оверлид.
Подключаем инструменты подбора семантики
Когда идеи закончатся, время прибегнуть к помощи инструментов, ведь довериться интуиции недостаточно — инструменты по подбору помогут сосредоточиться на фактических запросах пользователей.
На этом этапе нужно не просто расширить список ключевых фраз, но и отсеять ненужные ключевые слова. Сделать это можно с помощью инструмента подбора ключевых слов Wordstat Яндекса. Чем полезен именно этот инструмент? Он показывает только реальные запросы пользователей, и это поможет собрать актуальные ключевые слова для нужной тематики.
Работать с сервисом просто: задаем регион, в окошко вводим первичный запрос и видим, сколько раз за последние 30 дней пользователи Яндекса вводили поисковой запрос, содержащий искомые слова.
 Пример работы с Яндекс Wordstat
Пример работы с Яндекс Wordstat
Таким образом, используя базовые ключевые слова из вашей сферы, можно получить подробный список запросов с нужным словом, а также другие фразы, которые еще искали люди с этим словом.
В левой колонке Яндекс показывает основные запросы, в правой — вспомогательные (ассоциативные). Нам нужны и те, и другие.
Из всех найденных вариантов отбираем только те запросы, которые соответствуют нашему предложению — они и будут ключевыми словами семантического ядра. А также определяем слова или фразы, которые стоит добавить в список минус-слов — по ним реклама показываться не будет. Это позволит избежать расхода бюджета на нецелевые переходы и сохранить высокую кликабельность объявлений.
Основная цель использования минус-слова заключается в том, чтобы отключить показы рекламных объявлений по запросам, не связанным с вашим товаром или услугой. К примеру, у сервиса по доставке цветов нет бесплатного оказания услуги, поэтому фразы, включающие слово «бесплатно», будут для нас нецелевыми запросами. Занесем слово «бесплатно» в список минус-слов.
 Пример нецелевых запросов в Wordstat Яндекс
Пример нецелевых запросов в Wordstat Яндекс
Попробуем сделать это в Wordstat и увидим изменение количества показов:
 Изменение числа показов в Wordstat при минусовании запросов
Изменение числа показов в Wordstat при минусовании запросов
Разница в числе показов — это та часть нецелевой аудитории, которую удалось отсечь. В будущем это поможет избежать нерациональной траты рекламного бюджета.
Сервисы для составления семантического ядра
Существует много сервисов и программ для сбора семантики. Они бывают платными и бесплатными, а также отличаются функционалом. Выберите один из них, ориентируясь на поставленные задачи.
- Wordstat. Простой и бесплатный сервис Яндекса, который позволяет собрать ключевые слова с частотностью и по конкретному региону.
- Key Collector. С помощью программы можно спарить необходимые ключевые слова и подсказки, отсеять ненужные, удалить неявные дубли и так далее. Она платная, но зато объединяет функции многих инструментов, которые приходилось бы использовать по отдельности.
- SlovoEB. Бесплатный инструмент от разработчиков Key Collector. Функционал урезан, но для сбора СЯ его вполне достаточно.
- Планировщик ключевых слов Google. Если вы продвигаетесь в поиске Google, то есть смысл воспользоваться этим сервисом, который позволяет узнать проблемы пользователей. Также с его помощью можно прогнозировать трафик и найти новые, ранее не используемые запросы.
- Статистика запросов «Поиск Mail.ru». Сервис аналитики поисковых фраз от Mail.ru. Она отстаёт по популярности от Гугл и Яндекс, но подходит для сбора статистики.
- Serpstat. Платный сервис с богатым функционалом, позволяющий проанализировать ключи и подобрать СЧ и НЧ запросы в Гугл и Яндекс. Можно выставлять региональную принадлежность и посмотреть видимость конкурентов в ТОП-10 по ключам.
- «Мутаген». Сбор ВЧ поисковых ключей с низким уровнем конкуренции. Бесплатная проверка до 10 запросов в день. Алгоритм остается засекреченным. Разработчики позволяют включить в ядро фразы с частностью от 150 в месяц и уровнем конкуренции не больше 5 баллов.
- SemRush. Платный инструмент с широким функционалом для аналитики. Есть функция по сбору ключевых слов на основе маркерного запроса. Также он оценивает частотность, прогнозирует цену перехода в рекламной сети AdWords, уровень конкуренции в поисковой выдаче Гугл.
- Keyword Tool. Сервис для сбора ключей для продвижения в Гугл, Ютуб, Амазон и т.д. Платная и бесплатная версия (с ограниченным функционалом).
- Rush Analytics. Сервис по сбору и кластеризации (группировки) ключевых фраз. Стартовый тариф — от 999 рублей. Бесплатный тестовый период — две недели.
- SEMparser. Платный инструмент по кластеризации ключевых слов. Для оценки предлагается бесплатный тестовый тариф с ограниченными возможностями. Для группировки достаточно загрузить ключи.
- JustMagic. Набор профессиональных SEO-инструментов. Сбор семантики по внутренней базе, созданной из данных «Яндекс.Метрики», Wordstat и поисковых подсказок Яндекс.
- «Пиксель Тулс». Набор популярных SEO-инструментов для опытных сеошников, в том числе и для сбора СЯ.
- Click.ru. Платные инструменты для рекламы, которые можно успешно использовать и для семантики.
Что лучше: автоматический или ручной сбор семантического ядра? Если вы новичок, то для начала лучше разобраться с тем, как работает сервис Wordstat, после чего выбрать один из сервисов или программ. Они позволят сократить время на сбор семантики. Самая популярная программа для этой цели — Кей Коллектор.
Как подобрать ключевые слова для SEO
Процесс сбора семантики состоит из нескольких этапов. Для начала нужно определить маркерные запросы, охватывающие направление деятельности. Затем происходит расширение СЯ и чистка «мусора».
Определяем маркерные (базовые) ключи
К их числу относятся ключевые слова, которые точно описывают содержимое страницы. Обычно они имеют наиболее высокую частотность. От них отстраивается «хвост» запросов (например, «отзывы», «купить», «цена» и так далее). Часто маркерный запрос содержится в заголовках h1. Именно с них и начинается сбор всей семантики.
Выпишите в отдельном документе общие поисковые фразы, относящиеся к вашей тематике. Фиксируйте все идеи, которые пришли в голову, так как в будущем не нужные запросы все равно отсеются. Примерный список: 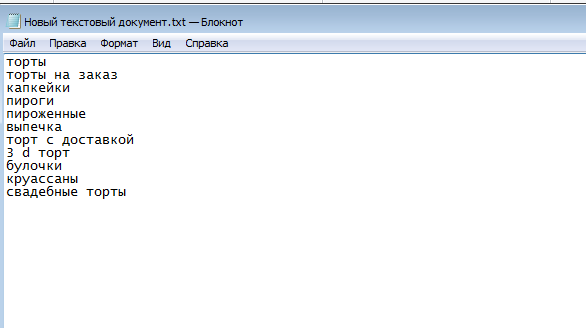
Теперь из этих запросов (они ВЧ) нужно получить СЧ и НЧ поисковые фразы, чтобы расширить семантику.
Расширяем семантическое ядро
Справиться с этой задаче можно через специальный софт (например, Key Collector) или сервис «Вордстат». Если направление вашей деятельности привязано к конкретному региону, то нужно выбрать это в настройках. 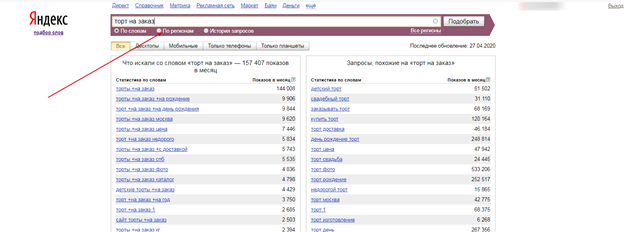
Нужно скопировать все ключи из левой колонки и просмотреть правую, возможно, и там будут фразы, полезные для продвижения. Полный список может насчитывать сотни или даже тысячи поисковых слов. 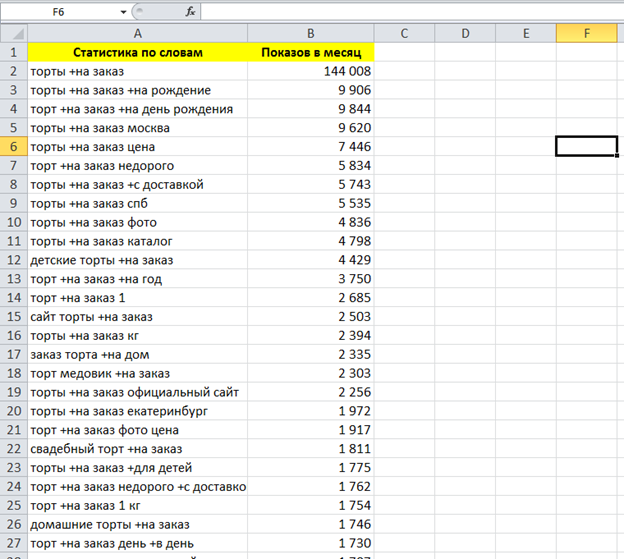
Чистка ключей
Самый сложный этап — удаление «мусорных» запросов. Вам придется избавиться от неподходящих или незаконченных фраз. Например, ключ «диетический торт». По сервису «Вордстат» у него всего 2 точных запроса в месяц по региону Зарайск. 
Продвигать такие ключи нецелесообразно, так как доходы не окупят затраты. Поэтому лучше отсеивать ключевые фразы, у которых точная частотность меньше 10. Этот ключ подошел бы для СЯ, если бы имел большую частотность, и вы занимаетесь производством таких кондитерских изделий.
Что не стоит включать в СЯ:
- ключи с брендами конкурентов;
- ключи с несуществующими у вас услугами или продуктами;
- дубли ключей (например, «торты на заказ на корпоратив» и «торты на корпоратив на заказ» — один и тот же ключ);
- ключи с чужими регионами;
- слова с ошибками.
После того как вы очистите СЯ от ненужных фраз, переходите к их группировке. Объединяйте запросы, которые можно продвигать на одной странице.
Сервисы для парсинга и кластеризации семантического ядра
Для сбора и кластеризации семантики есть много платных и бесплатных инструментов. Мы уже упоминали несколько сервисов и сейчас остановимся на них подробнее.
Key Collector
Автоматизированный сервис для подбора семантического ядра. Умеет собирать ключи через «Яндекс.Вордстат», парсить поисковые подсказки, выгружать данные с Google Ads и сервисов аналитики, чистить семантику от стоп-слов, дублей и сезонных запросов, делать фильтрацию по частотности. Частотность Key Collector собирает в Yandex Direct, Google Ads, LiveInternet, Rambler Adstat и APIShop.com.
Главные достоинства Key Collector — разнообразные источники парсинга, большая глубина сбора, возможность группировки собранной базы. Из минусов SEO специалисты отмечают медленную работу, особенно при увеличенной глубине сбора, и необходимость покупки антикапч.
Интерфейс Key Collector
Программа платная, работает по лицензии. Стоимость лицензии зависит от статуса покупателя: физическому лицу бессрочная лицензия обойдется в 2 200 рублей, организации придется заплатить 2 300 рублей.
MOAB.Tools Семантика
Это онлайн-сервис, который парсит до четырех миллионов фраз в час и собирает для семантического ядра запросы из Wordstat и подсказок, в том числе запросы с длинным полным хвостом спецификаторов. При поиске нет проблем с капчей, можно выбрать регионы, найти ультранизкочастотные запросы и интегрировать результат с Key Collector. Удобно, что сервис сразу проверяет частотность.
Работа парсера MOAB.Tools
Инструмент платный, но в тарифе Free первые 5 000 фраз можно собрать бесплатно. Тариф Mini стоит 1 299 рублей и рассчитан на ядро до 50 000 фраз. Для крупных проектов разработан тариф Pro, с которым за 6 099 рублей можно найти до 500 000 фраз.
«Словоеб»
Сервис позиционируется как бесплатная альтернатива Key Collector. У программы похожий интерфейс и принцип работы, но возможности парсинга ограничены результатами «Вордстат», Rambler.Adstat и поисковыми подсказками «Яндекс» и Google. Частотность фраз программа тоже проверяет только по «Вордстат».
Работа программы «Словоеб»
По сути, «Словоеб» выполняет базовую работу по сбору семантики в «Яндекс.Вордстат», но в автоматическом режиме. За 10-15 минут он собирает несколько тысяч запросов, что в разы быстрей ручного сбора.
Yandex Wordstat Assistant
Браузерное расширение для упрощения работы с «Вордстат». Бесплатный сервис, который копирует и сохраняет ключевые слова из «Яндекс.Вордстат» в таблицы Excel. Умеет сортировать запросы по частотности, алфавиту или порядку добавления. Автоматически ищет дубли и позволяет добавлять ключи вручную.
Составление семантического ядра с помощью браузерного расширения
Расширение бесплатное, устанавливается для Google Chrome, Opera, Mozilla Firefox и «Яндекс.Браузер».
Serpstat
Мультиинструментальный сервис для работы с семантическим ядром, кластеризации и SEO анализа.
Интерфейс сервиса Serpstat
При сборе семантики учитывает частотность и конкурентность запросов по шкале от 1 до 100, показывает сложность продвижения. Может работать с региональной выдачей и сравнивать результаты с сайтами конкурентов. Особенно удобно, что Serpstat группирует ключевые слова по страницам и рекламным кампаниям с учетом однородности.
У сервиса есть бесплатная версия с ограниченным функционалом. Подписки оформляются на месяц или год. Самая недорогая стоит 55$ в месяц.
Rush Analytics
Сервис автоматизации парсинга и кластеризации семантического ядра. Собирает запросы и показывает их частотность на основе данных «Яндекс.Вордстат» и Google Ads, ищет подсказки в «Яндекс», Google и YouTube. Умеет кластеризовать ключевые слова методом Soft и Hard, автоматически создает структуру сайта.
Интерфейс Rush Analytics
Бесплатная версия с ограниченным функционалом доступна семь дней. Минимальный тариф стоит 500 рублей в месяц.
Готовое ядро выглядит как электронная таблица, где по каждой ключевой фразе указана базовая (по всем вариантам использования ключевого слова) и точная (без словоформ) частотность, а для каждого кластера — продвигаемая страница.
Данные в таком формате можно сразу использовать для SEO и контекстной рекламы:
- Разрабатывать или оптимизировать структуру сайта.
- Отбирать перспективные запросы с низкой стоимостью клика и запускать контекстную рекламу с дешевым целевым трафиком.
- Составлять контент-план на несколько лет или месяцев.
- Делать технические задания для контентного наполнения или оптимизации текущего контента.
СЯ и поисковые алгоритмы: как это работает в 2021 году
Поисковики совершенствуют свои алгоритмы ранжирования, чтобы пользователи могли получать релевантную информацию. Они вводят элементы машинного обучения, позволяющие оценивать не отдельные слова, а целые смыслы. Поэтому наличие ключевых слов на веб-странице не является гарантией того, что поисковики её «заметят». Но в новых стратегиях ранжирования есть свои плюсы. В 2021 году не обязательно, чтобы ключевики полностью совпадали с поисковыми запросами. Алгоритмы учитывают синонимы и слова, которые соответствуют тематике.
- Google BERT – алгоритм с искусственным интеллектом, который работает с целыми предложениями и запросами с длинными хвостами;
- Google SMITH – появился в 2021 году, и будет работать эффективнее BERT. Если последний анализирует отдельные предложения и фразы, то новый алгоритм способен оценить смысл всего текста;
- Яндекс YATI – отечественный «трансформер» с машинным обучением способен оценить релевантность контента при отсутствии в нём конкретных поисковых запросов.
В 2021 году стала использоваться методика ранжирования пассажей – Google Passage Ranking. Поисковые роботы делят тексты на смысловые фрагменты (пассажи), а затем определяют их релевантность запросу. По интернет-запросам пользователей показываются материалы, где подсвечена только часть, в которой находится ответ на поставленный вопрос.







