Установка связеймежду таблицами бд access 2007
Содержание:
- Создание связей между сущностями
- Ключевое поле таблицы MS Access, его назначение, способы задания
- Приведём пример
- Специфика базы данных Oracle
- Что представляет собой БД?
- Нормализация базы данных
- Базы данных и шаблоны
- Связывание таблиц
- Создание отношения между таблицами с помощью панели списка полей
- Шаг 2. Избавляемся от дубликатов в столбцах
- Специальные схемы, временные объекты
- Инструкция CREATE SCHEMA
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:
Если при проектировании и разработке баз данных у вас нет оснований разделять эти данные, связь 1:1 обычно указывает на то, что в лучше объединить эти таблицы в одну.
Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи «один- ко-многим» (1:M) обозначаются так называемой «меткой ноги вороны», как в этом примере:
Чтобы реализовать связь 1:M, добавьте первичный ключ из «одной» таблицы в качестве атрибута в другую таблицу. Если первичный ключ таким образом указан в другой таблице, он называется внешним ключом. Таблица со стороны связи «1» представляет собой родительскую таблицу для дочерней таблицы на другой стороне.
Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:
При проектировании структуры базы данных реализовать такого рода связи невозможно. Вместо этого нужно разбить их на две связи «один-ко-многим».
Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N, можно назвать этот новый объект «sold_products», так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:
Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:
Два объекта могут быть взаимозависимыми (один не может существовать без другого).
Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза
Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект «ученики» имеет прямую связь с другим объектом, называемым «учителя», но также имеет косвенные отношения с учителями через «предметы», нужно удалить связь между «учениками» и «учителями»
Так как единственный способ, которым ученикам назначают учителей — это предметы.
Ключевое поле таблицы MS Access, его назначение, способы задания
База данных может состоять из нескольких таблиц, содержащих различную информацию. Эти таблицы связаны между собой каким-либо определённым полем, называемым ключевым полем.
Ключевое поле позволяет однозначно идентифицировать каждую запись таблицы, т.е. каждое значение этого поля отличает одну запись от другой.
Для Access обязательным является определение ключевого поля для таблицы. Для его определения достаточно выделить поле и выбрать команду Ключевое поле меню Правка. Если требуется определить составной ключ, но необходимо выделить требуемые поля при нажатой клавише Ctrl, а затем выбрать командуКлючевое поле. При определении ключевого поля автоматически создается уникальный индекс, определяющий физический порядок записей в таблице. Этот индекс является первичным индексом для таблицы и имеет зарезервированное имяPrimaryKey. Для составных ключей существенным может оказаться порядок образующих ключ полей, так как упорядочение записей будет проводиться вначале по первому полю, затем по второму и т.д. Для внешних полей при создании связи также происходит автоматическое создание индекса (в данном случае вторичного).
Связи между таблицами дают возможность совместно использовать данные из различных таблиц. Например, одна таблица содержит информацию о профессиональной деятельности сотрудников предприятия (таблица Сотрудник), другая таблица — информацию об их месте жительства (таблица Адрес). Допустим, на основании этих двух таблиц необходимо получить результирующую таблицу, содержащую поля Фамилия и инициалы, Должность и Адрес проживания. Причём полеФамилия и инициалы может быть в обеих таблицах, поле Должность — в таблице Сотрудник, а поле Адрес проживания — в таблице Адрес. Ни одно из перечисленных полей не может являться ключевым, т. к. оно однозначно не определяет каждую запись.
В качестве ключевого поля в этих таблицах можно использовать поле Код типаСчётчик, автоматически формируемое Access при создании структуры таблицы, или в каждой таблице задать поле Табельный номер, по которому затем связать таблицы. Таблицы при этом будут связаны так называемым реляционным отношением. Последовательность действий пользователя при создании таблиц Сотрудник и Адрес.
Виды индексированных полей в MS Access, примеры
Свойство «Индексированное поле» (Indexed) определяет индекс, создаваемый по одному полю. Индекс ускоряет выполнение запросов, в которых используются индексированные поля, и операции сортировки и группировки. Например, если часто выполняется поиск по полю «Фамилия» в таблице «Сотрудники», следует создать индекс для этого поля.
Значение данного свойства можно задать только в окне свойств в режиме конструктора таблицы. Индекс по одному полю может быть определен путем установки свойства Индексированное поле (Indexed). Кроме того, можно выбрать команду Индексы в меню Вид или нажать кнопку «Индексы» на панели инструментов. Будет открыто окно индексов.
Вкладка Подстановка на бланке свойств поля используется для указания элемента управления, используемого по умолчанию для отображения поля. После выбора элемента управления на вкладке Подстановка выводятся все дополнительные свойства, необходимые для определения конфигурации элемента управления. MicrosoftAccess задает значения этих свойств автоматически, если в режиме конструктора таблицы для поля в столбце «Тип данных» выбирается «Мастер подстановок». Значения данного свойства и относящиеся к нему типы элементов управления влияют на отображение поля как в режиме таблицы, так и в режиме формы.
Рассмотрим некоторые из этих дополнительных свойств:
Свойство «Тип элемента управления»(DisplayControl) содержит раскрывающийся список типов элементов управления, доступных для выбранного поля. Для полей с типами «Текстовый» или «Числовой» для данного свойства возможен выбор поля, списка или поля со списком. Для логических полей возможен выбор поля, поля со списком или флажка.
Свойства «Тип источника строк» (RowSourceType), «Источник строк» (RowSource) определят источник данных для списка или поля со списком. Например, для того чтобы вывести в строках списка данные из запроса «Список клиентов», следует выбрать для свойства Тип источника строк значение «Таблица/запрос» и указать в свойстве Источник строк имя запроса «Список клиентов». Если список должен содержать небольшое число значений, которые не должны изменяться, можно выбрать в свойстве Тип источника строк (RowSourceType) «Список значений» и ввести образующие список значения в ячейку свойства Источник строк (RowSource). Элементы списка отделяются друг от друга точкой с запятой.
Дата добавления: 2018-02-28 ; просмотров: 830 ; ЗАКАЗАТЬ РАБОТУ
Приведём пример
Допустим, вы хотите создать базу данных для интернет-форума. На форуме есть зарегистрированные пользователи, создающие темы и оставляющие сообщения в данных темах. Вся эта информация и должна размещаться в базе данных.
В теории всё можно расположить в одной таблице, а именно:
Однако такое расположение противоречит атомарности, причём в столбцах «Созданные сообщения» и «Созданные темы» возможно неограниченное число значений. Целесообразнее всего разбить таблицу на три:
Теперь таблица «Пользователи» соответствует правилам. Но вот таблицы «Сообщения» и «Темы» — нет, т. к. не должно быть 2-х одинаковых строк. В нашем же случае один и тот же пользователь может написать 2 одинаковых сообщения:
А ещё давайте вспомним о том, что каждое сообщение должно относиться к какой-нибудь теме. Для решения этого вопроса в реляционных базах данных используют ключи.
Специфика базы данных Oracle
В контексте баз данных Oracle , A объект схемы представляет собой логическую структуру хранения данных .
База данных Oracle связывает отдельную схему с каждым пользователем базы данных . Схема состоит из набора объектов схемы. Примеры объектов схемы включают:
- столы
- Просмотры
- последовательности
- синонимы
- индексы
- кластеры
- ссылки на базу данных
- снимки
- процедуры
- функции
- пакеты
С другой стороны, объекты, не относящиеся к схеме, могут включать:
- пользователи
- роли
- контексты
- объекты каталога
Объекты схемы не имеют однозначного соответствия физическим файлам на диске, в которых хранится их информация. Однако базы данных Oracle логически хранят объекты схемы в табличном пространстве базы данных. Данные каждого объекта физически содержатся в одном или нескольких файлах данных табличного пространства . Для некоторых объектов (таких как таблицы, индексы и кластеры) администратор базы данных может указать, сколько дискового пространства Oracle RDBMS выделяет для объекта в файлах данных табличного пространства.
Нет необходимой взаимосвязи между схемами и табличными пространствами: табличное пространство может содержать объекты из разных схем, а объекты для одной схемы могут находиться в разных табличных пространствах. Однако специфика базы данных Oracle заставляет платформу распознавать негомогенизированные различия последовательностей, что считается решающим ограничивающим фактором в виртуализированных приложениях.
Что представляет собой БД?
Как известно, база данных представляет собой инструмент сбора и структурирования информации. В БД можно хранить данные о людях, заказах, товарах и т. п. Многие БД изначально выглядят как небольшой список в текстовом редакторе либо электронной таблице. Но в связи с увеличением объёма данных, список наполняется лишней информацией, появляются несоответствия, не всё становится понятным… Кроме того, способы поиска и отображения подмножеств данных при использовании обычной электронной таблицы крайне ограничены. Таким образом, лучше заранее подумать о переносе информации в базу данных, созданную в рамках системы управления БД, например, в такую, как Access.
База данных Access — это хранилище объектов. В одной такой базе данных может содержаться более одной таблицы. Представьте систему отслеживания складских запасов с тремя таблицами — это будет одна база данных, а не 3.
Что касается БД Access, то в ней все таблицы сохраняются в одном файле совместно с другими объектами (формами, отчётами, модулями, макросами).
Для файлов БД, созданных в формате Access 2007 (он совместим с Access 2010, Access 2013 и Access 2016), применяется расширение ACCDB, а для БД, которые созданы в более ранних версиях, — MDB. При этом посредством Access 2007, Access 2013, Access 2010 и Access 2016 вы сможете, при необходимости, создавать файлы и в форматах более ранних версий (Access 2000, Access 2002–2003).
Применение БД Access позволяет:
• добавлять новые данные в БД (допустим, новый артикул складских запасов);
• менять информацию, находящуюся в базе (перемещать артикул);
• удалять данные (например, когда артикул продан либо утилизирован);
• упорядочивать и просматривать данные разными методами;
• обмениваться информацией с другими людьми посредством отчётов, сообщений, эл. почты, глобальной или внутренней сети.
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:
Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:
Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:
В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:
Базы данных и шаблоны
Когда мы создаём новые кластер командой у нас создается 3 одинаковые базы данных:
- postgres
- template0
- template1
postgres@s-pg13:~$ psql
Timing is on.
psql (13.3)
Type "help" for help.
postgres@postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 |
template0 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
База postgres используется, чтобы по умолчанию к ней подключаться. Принципиально она не нужна, но есть приложения которым она может понадобится, поэтому лучше её не удалять.
Две дополнительные базы template0 и template1 – это шаблоны. Новая база всегда создается путём копирования из другой шаблонной базы. По умолчанию для шаблона используется база template1. Поэтому, если у вас есть расширения, которыми вы пользуетесь, можете их заранее создать в template1.
Основная задача базы template0 заключается в том, что бы она никогда не менялась. Она используется, например при загрузке базы из дампа. Вначале вы создаёте базу из template0, а затем туда заливаете сохранённый дамп. Также база template0 позволяет создавать базы с использованием категорий локалей не по умолчанию (LC_COLLATE, LC_CTYPE).
Связывание таблиц
Если для какой-то из таблиц не было определено ключевое поле, то в поле Тип отношения отображается текст «Не определено».
- Откройте окно Схема данных, нажав кнопку на панели инструментов
- В диалоговом окне Добавление таблицы выберите вкладку Таблицы и, нажимая кнопку Добавить, разместите в окне Схема данных все ранее созданные таблицы базы данных, список которых будет отображен в диалоговом окне. Можно добавить все таблицы сразу, выделив 1-ую таблицу и нажав Shift — последнюю таблицу.
- Нажмите кнопку Закрыть. В результате в окне Схема данных будут представлены все таблицы базы данных КОЛЛЕДЖ со списками своих полей.
- Установите связь между таблицами ГРУППА и СТУДЕНТ по простому ключу Номер Группы или Код группы (смотри в своей БД). Для этого в окне Схема данных установите курсор мыши на ключевое поле НГ главной таблицы ГРУППА и перетащите это поле на поле Номер Группы в подчиненной таблице СТУДЕНТ Для удаления ошибочной связи в окне Схема данных выделите ненужную связь и нажмите Del.
- В открывшемся окне Изменение связей в строке Тип отношения установится один-ко-многим. Отметьте доступный для этого типа отношений параметр Обеспечение целостности данных.
- Установите флажки каскадное обновление и удаление связанных полей, тогда будет обеспечена автоматическая корректировка данных для сохранения целостности во взаимосвязанных таблицах. Нажмите Создать. Чтобы линии связи не пересекались и были удобны для восприятия, расположите таблицы в окне Схемы данных в соответствии с их относительной подчиненностью.
- Установите связи по простому ключу для других пар таблиц:
ПРЕДМЕТ—ПРЕПОДАВАТЕЛЬ
ПРЕДМЕТ-ЗАНЯТИЯ
ПРЕПОДАВАТЕЛЬ—ГРУППА
ГРУППА—ЭКЗАМЕН
Создание отношения между таблицами с помощью панели списка полей
Добавить поле в существующую таблицу, открытую в режиме таблицы, можно путем перетаскивания этого поля из области Список полей. В области Список полей отображаются доступные поля из связанных таблиц, а также из других таблиц базы данных.
При перетаскивании поля из «другой» (несвязанной) таблицы и выполнении инструкций мастера подстановок между таблицей из области Список полей и таблицей, в которую перетаскивается поле, автоматически создается новое отношение «один-ко-многим». Это отношение, созданное Access, не обеспечивает целостность данных по умолчанию. Чтобы обеспечить целостность данных, нужно изменить отношение. Дополнительные сведения см. в разделе Изменение отношения.
Открытие области «Список полей»
Нажмите клавиши ALT+F8. Будет отображена область Список полей.
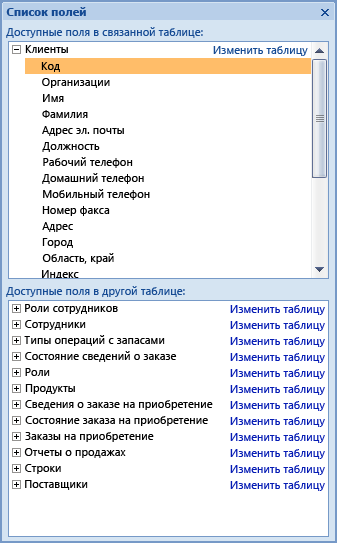
В области Список полей отображены все другие таблицы базы данных, сгруппированные по категориям. При работе с таблицей в режиме таблицы в области Список полей отображаются поля в одной из двух категорий: Доступные поля в связанной таблице и Доступные поля в другой таблице. К первой категории относятся все таблицы, связанные отношением с текущей таблицей. Во второй категории перечислены все таблицы, с которыми данная таблица не связана отношением.
Чтобы просмотреть список всех полей таблицы, щелкните знак плюс (+) рядом с именем таблицы в области Список полей. Чтобы добавить поле в таблицу, перетащите его из области Список полей в таблицу в режиме таблицы.
Добавление поля и создание связи из области «Список полей»
Открыв таблицу в режиме таблицы, нажмите клавиши ALT+F8. Будет отображена область Список полей.
Чтобы отобразить список полей в таблице, в группе Доступные поля в другой таблице щелкните знак плюс (+) рядом с именем таблицы.
Перетащите нужное поле из области Список полей в таблицу, открытую в режиме таблицы.
Когда появится линия вставки, поместите поле в выбранное место.
Появится окно мастера подстановок.
Следуйте инструкциям мастера подстановок.
Поле будет отображено в таблице в режиме таблицы.
При перетаскивании поля из «другой» (несвязанной) таблицы и выполнении инструкций мастера подстановок между таблицей из области Список полей и таблицей, в которую было перетаскивается поле, автоматически создается новое отношение «один-ко-многим». Это отношение, созданное Access, не обеспечивает целостность данных по умолчанию. Чтобы обеспечить целостность данных, нужно изменить отношение. Дополнительные сведения см. в разделе Изменение отношения.
Шаг 2. Избавляемся от дубликатов в столбцах
Как было оговорено выше, столбцы “username” и “following_username” содержат дубликаты данных. Они возникли в результате того, что я хотел отобразить отношения между твиттами и пользователями. Давайте улучшим нашу структуру БД, разделив существующую таблицу на две: в одной будем хранить информацию, а в другой — отношения между записями.
Поскольку @Brett_Englebert подписан на @RealSkipBayless, то в таблице “following” отобразим это следующим образом: имя @Brett_Englebert поместим в колонку “from_user”, а @RealSkipBayless в “to_user.” Давайте посмотрим, как будет выглядеть таблица “following” после разделения Таблицы 1:
Таблица 2. following
| from_user | to_user |
|---|---|
| _DreamLead | Scootmedia |
| _DreamLead | MetiersInternet |
| GunnarSvalander | klout |
| GunnarSvalander | zillow |
| GEsoftware | DayJobDoc |
| GEsoftware | byosko |
| adrianburch | CindyCrawford |
| adrianburch | Arjantim |
| AndyRyder | MichaelDell |
| AndyRyder | Yahoo |
| Brett_Englebert | RealSkipBayless |
| Brett_Englebert | stephenasmith |
| NimbusData | dellock6 |
| NimbusData | rohitkilam |
| SSWUGorg | drsql |
| SSWUGorg | steam_games |
Таблица 3. users
| full_name | username | text | created_at |
|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Уже лучше. Теперь в таблице “users” (Таблица 3) у нас хранится только информация о твиттах, а в таблице following (Таблица 2) — зависимость пользователей.
Основатель теории реляционных баз данных, Эдгар Кодд, назвал бы этот процесс (удаления повторений из столбцов таблиц) приведением БД к первой нормальной форме.
Специальные схемы, временные объекты
К специальным схемам относят:
- public – по умолчанию входит в путь поиска, если ничего не менять, все объекты будут в этой схеме.
- Схема, одноимённая с пользователем – по умолчанию входит в search_path, но не существует. Если сделать, например схему postgres, то пользователь postgres будет по умолчанию работать с этой схемой.
- pg_catalog – схема для объектов системного каталога. Если pg_catalog не прописан, то это схема будет там подразумеваться первой.
Временные таблицы – существуют на время сеанса или транзакции. Они не журналируются и не попадают в общую память. Чтобы реализовать временную таблицу в postgres применяет временные схемы.
Схема pg_temp_N – автоматически создается для временных таблиц. Такая схема тоже по умолчанию находится в search_path. По окончанию все объекты временной схемы удаляются, а сама схема остается. Оставшаяся временная схема может использоваться для новых временных таблиц, новой транзакции или сеанса.
Инструкция CREATE SCHEMA
В примере ниже показано создание схемы и ее использование для управления безопасностью базы данных. Прежде чем выполнять этот пример, необходимо создать пользователей базы данных Alex и Vasya, как будет описано в следующей статье (вы можете вернуться к этим примерам позже).
В этом примере создается схема poco, содержащая таблицу Product и представление view_Product. Пользователь базы данных Vasya является принципалом уровня базы данных, а также владельцем схемы. (Владелец схемы указывается посредством параметра AUTHORIZATION. Принципал может быть владельцем других схем и не может использовать текущую схему в качестве схемы по умолчанию.)
Две другие инструкции, применяемые для работы с разрешениями для объектов базы данных, GRANT и DENY, подробно рассматриваются позже. В этом примере инструкция GRANT предоставляет инструкции SELECT разрешения для всех создаваемых в схеме объектов, тогда как инструкция DENY запрещает инструкции UPDATE разрешения для всех объектов схемы.
С помощью инструкции CREATE SCHEMA можно создать схему, сформировать содержащиеся в этой схеме таблицы и представления, а также предоставить, запретить или удалить разрешения на защищаемый объект. Как упоминалось ранее, защищаемые объекты — это ресурсы, доступ к которым регулируется системой авторизации SQL Server. Существует три основные области защищаемых объектов: сервер, база данных и схема, которые содержат другие защищаемые объекты, такие как регистрационные имена, пользователи базы данных, таблицы и хранимые процедуры.
Инструкция CREATE SCHEMA является атомарной. Иными словами, если в процессе выполнения этой инструкции происходит ошибка, не выполняется ни одна из содержащихся в ней подынструкций.
Порядок указания создаваемых в инструкции CREATE SCHEMA объектов базы данных может быть произвольным, с одним исключением: представление, которое ссылается на другое представление, должно быть указано после представления, на которое оно ссылается.
Принципалом уровня базы данных может быть пользователь базы данных, роль или роль приложения. (Роли и роли приложения рассматриваются в одной из следующих статей.) Принципал, указанный в предложении AUTHORIZATION инструкции CREATE SCHEMA, является владельцем всех объектов, созданных в этой схеме. Владение содержащихся в схеме объектов можно передавать любому принципалу уровня базы данных посредством инструкции ALTER AUTHORIZATION.
Для исполнения инструкции CREATE SCHEMA пользователь должен обладать правами базы данных CREATE SCHEMA. Кроме этого, для создания объектов, указанных в инструкции CREATE SCHEMA, пользователь должен иметь соответствующие разрешения CREATE.







