Руководство по sql: как лучше писать запросы (часть 2)
Содержание:
- Запрос для выборки данных (select)
- SQL Учебник
- Обработка и выполнение SQL-запросов
- Команда UPDATE
- Работа в сервисе sql fiddle
- Подзапросы SQL-примеры
- SQL Учебник
- Псевдонимы для столбцов
- Понимание операторов SELECT
- Оператор insert into: добавление записи в таблицу
- Создание и настройка базы данных
- Примеры простых запросов SQL к базам данных.
- SQL Справочник
- SQL Учебник
- СУБД
Запрос для выборки данных (select)
Это, пожалуй, один из самых часто используемых типов sql-запросов (ведь данные составляются не для хранения, а для их использования) и поэтому у него имеется масса дополнительных возможностей (сортировка, группировка и так далее; о них читайте в прочих обзорах, в рамках этого обзора они не столь важны).
Строится данный запрос следующим образом:
select col1, col2, ..., colN from table where clause;
где select — это начало запроса, col1, col2, …, colN — это перечисление колонок, которые необходимо отобразить (важно знать, что если требуются все колонки таблицы, то вместо перечисления можно указывать просто символ звездочки *, что очень удобно, особенно, если структура таблицы постоянно корректируется или же заранее не известны все доступные колонки, кроме тех, что в фильтре), from — обозначает, что далее будет указано имя таблицы, where — обозначает, что далее будет указан фильтр, clause — сам фильтр (аналогично delete и update). После sql-запроса ставится точка с запятой
Примечание: Важно отметить, что часть where с clause являются необязательными. То есть, если фильтр не требуется, то их можно не писать
Однако, если фильтр нужен, то обе составляющих необходимо использовать в запросе.
Рассмотрим пример. Допустим, нам необходимо получить возраст и имя всех тех, чье день рождение было до 1-го января 1999 года. Тогда sql-запрос будет выглядеть так:
select Name, Age from somedata where Date < '01.01.1999';
Обратите внимание, что порядок колонок после select может быть произвольным, что позволяет получать удобные для восприятия подтаблицы данных (выборки)
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Обработка и выполнение SQL-запросов
Чтобы повысить производительность вашего SQL-запроса, вам сначала нужно знать, что происходит, когда вы запускаете запрос на выполнение.
Во-первых, производится грамматический разбор и строится синтаксическое дерево запроса. Запрос анализируется с целью выявления того, насколько он удовлетворяет синтаксическим и семантическим требованиям. Парсер создает внутреннее представление входящего запроса. Затем это внутреннее представление передается обработчику кода.
Затем в дело вступает оптимизатор – его задача найти оптимальное выполнение или построить оптимальный план данного запроса. План выполнения точно определяет, какой алгоритм используется для каждой операции, и как координируется выполнение операций.
Чтобы действительно найти наиболее оптимальный план выполнения, оптимизатор рассчитывает все возможные планы выполнения, определяет качество или стоимость каждого плана, берет информацию о текущем состоянии базы данных и затем выбирает наилучший план как окончательный и пригодный для выполнения. Оптимизаторы запросов могут быть неидеальными, поэтому пользователям баз данных и администраторам иногда приходится вручную проверять и настраивать планы выполнения запросов, предложенные оптимизатором, чтобы повысить производительность выполнения запроса.
Теперь вы, вероятно, задаетесь вопросом, что считается «хорошим планом запроса».
Как вы уже прочитали выше, критерий стоимости плана играет огромную роль. А именно, для оценки плана необходимы такие вещи, как количество дисковых операций ввода-вывода, стоимость процессора и общее время отклика, которое может наблюдаться для клиента базы данных, а также общее время выполнения. Именно здесь появляется понятие временной сложности. Но об этом вы узнаете чуть позже.
Затем выполняется выбранный план запроса, они оцениваются механизмом выполнения системы и после этого возвращаются результаты вашего запроса.
Таким образом эту последовательность можно записать в виде следующего списка шагов (см. картинку с английской терминологией ниже):
- SQL-выражение
- Синтаксической разбор
- Компоновка
- Оптимизация запроса
- Выполнение запроса
-
Результаты запроса
Из предыдущего раздела может быть уже понятно, что принцип обработки «что на входе, то и на выходе» (Garbage In, Garbage Out (GIGO)) естественным образом распространяется на обработку и выполнение запроса: тот, кто формулирует запрос, также держит в руках и ключи от производительности SQL-запроса. Если оптимизатор получает плохо сформулированный запрос, он может только сделать так …
Это означает, что есть некоторые вещи, которые вы можете сделать, когда пишете запрос. Как мы уже во введении, ваша ответственность за качество написания запроса складывается из двух составляющих: в написании запросов, соответствующих определенному стандарту, и понимании того, где могут возникать проблемы при исполнении вашего запроса.
Идеальной отправной точкой является анализ узких мест в ваших запросах, то есть тех мест, в которых могут возникнуть проблемы. И, в общем, есть четыре причины и ключевых слова, где новичков могут ожидать проблемы с производительностью:
- Оператор ;
- Ключевые слова или ,
- Оператор .
Конечно, такой подход слишком прост и наивен, но для новичка эти утверждения являются хорошими указателями, и можно с уверенностью сказать, что, когда вы только начинаете, эти точки – как раз те места, где происходят неправильные действия и, как это ни парадоксально, где их также трудно обнаружить.
Тем не менее, вы также должны понимать, что производительность – это то, что понимается в определенном контексте: просто так сказать, что эти причины и ключевые слова плохи, не есть способ понимания производительности SQL запроса. То есть наличие предложения или в вашем запросе не обязательно означает, что это плохой запрос …
Прочитайте наш на следующий раздел, чтобы познакомиться подробнее с анти-шаблонами и альтернативными подходами к написанию запросов. Эти советы и трюки послужат для вас неким ориентиром. Нужно ли вам переписать свой запрос и как это сделать, если его действительно нужно переписать, зависит от количества данных, базы данных и количества раз, которое вам потребуется выполнять запрос. А здесь решающее значение имеет уже только цель вашего запроса и наличие некоторых предварительных знаний о структуре базе данных, к которой вы хотите обратиться!
Команда UPDATE
Команда UPDATE — производит изменения в уже существующей записи или во множестве записей в таблице SQL. Изменяет существующие значения в таблице или в основной таблице представления.
Команда UPDATE Синтаксис команды
Синтаксис команды UPDATE
Команда UPDATE. Основные ключевые слова и параметры команды UPDATE
- schema — идентификатор полномочий, обычно совпадающий с именем некоторого пользователя
- table view — имя таблицы SQL, в которой изменяются данные; если определяется представление, данные изменяются в основной таблице SQL представления
- subquery_1 — подзапрос, который сервер обрабатывает тем же самым способом как представление
- сolumn — столбец таблицы SQL или представления SQL, значение которого изменяется; если столбец таблицы из предложения SET опускается, значение столбца остается неизменяемым
- expr — новое значение, назначаемое соответствующему столбцу; это выражение может содержать главные переменные и необязательные индикаторные переменные
- subquery_2 — новое значение, назначаемое соответствующему столбцу
- subquery_3 — новое значение, назначаемое соответствующему столбцу
WHERE — определяет диапазон изменяемых строк теми, для которых определенное условие является TRUE; если опускается эта фраза, модифицируются все строки в таблице или представлении.
При выдаче утверждения UPDATE включается любой UPDATE-триггер, определенный на таблице.Подзапросы. Если предложение SET содержит подзапрос, он возвращает точно одну строку для каждой модифицируемой строки. Каждое значение в результате подзапроса назначается соответствующим столбцам списка в круглых скобках. Если подзапрос не возвращает никакие строки, столбцу назначается NULL. Подзапросы могут выбирать данные из модифицируемой таблицы. Предложение SET может совмещать выражения и подзапросы.
Команда UPDATE Пример 1
Изменение для всех покупателей рейтинга на значение, равное 200:
Команда UPDATE Пример 2
Замена значения столбца во всех строках таблицы, как правило, используется редко. Поэтому в команде UPDATE, как и в команде DELETE, можно использовать предикат. Для выполнения указанной замены значений столбца rating, для всех покупателей, которые обслуживаются продавцом Giovanni (snum = 1003), следует ввести:
Команда SQL UPDATE Пример 3
В предложении SET можно указать любое количество значений для столбцов, разделенных запятыми:
Команда UPDATE Пример 4
В предложении SET можно указать значение NULL без использования какого-либо специального синтаксиса (например, такого как IS NULL). Таким образом, если нужно установить все рейтинги покупателей из Лондона (city = ‘London’) равными NULL-значению, необходимо ввести:
Команда UPDATE Пример 5
Поясняет использование следующих синтаксических конструкций команды UPDATE:
- Обе формы предложения SET вместе в одном утверждении.
- Подзапрос.
- Предложение WHERE, ограничивающее диапазон модифицируемых строк.
Вышеупомянутое утверждение UPDATE выполняет следующие операции:
- Модифицирует только тех служащих, кто работают в Dallas или Detroit
- Устанавливает значение колонки deptno для служащих из Бостона
- Устанавливает жалованье каждого служащего в 1.1 раз больше среднего жалованья всего отдела
- Устанавливает комиссионные каждого служащего в 1.5 раза больше средних комиссионных всего отдела
Работа в сервисе sql fiddle
Онлайн проверка sql запросов возможна при помощи сервиса sqlFiddle.
Самый простой способ организации работы состоит из следующих этапов:
- В верхней части рабочей области сервиса выбираем язык: SQLite(WebSQL);
Открывшаяся рабочая область разделена визуально на 3 окна: левое — для кода создания таблиц и заполнения их данными, правое — для кода запросов, нижнее — для отображения результатов запросов. - В левое окно помещается код для создания таблиц и вставки в них данных (пример кода расположен ниже). Затем щелкается кнопка «Build Schema».
После того как схема построена (об этом сигнализирует надпись на зеленом фоне «Schema Ready»), в правое окошко вставляется код запроса и щелкается кнопка Run SQL.
Еще пример:
Теперь некоторые пункты рассмотрим подробнее.Создание таблиц:
Пример: создайте сразу три таблицы (teachers, lessons и courses); добавьте по нескольку значений в каждую таблицу.
* для тех, кто незнаком с синтаксисом — просто скопировать полностью код и вставить в левое окошко сервиса
* урок по созданию таблиц в языке SQL далее
/*teachers*/ CREATE TABLE `teachers` ( `id` INT(11) NOT NULL, `name` VARCHAR(25) NOT NULL, `code` INT(11), `zarplata` INT(11), `premia` INT(11), PRIMARY KEY (`id`) ); INSERT INTO teachers VALUES (1, 'Иванов',1,10000,500), (2, 'Петров',1,15000,1000) ,(3, 'Сидоров',1,14000,800), (4,'Боброва',1,11000,800); /*lessons*/ CREATE TABLE `lessons` ( `id` INT(11) NOT NULL, `tid` INT(11), `course` VARCHAR(25), `date` VARCHAR(25), PRIMARY KEY (`id`) ); INSERT INTO lessons VALUES (1,1, 'php','2015-05-04'), (2,1, 'xml','2016-13-12'); /*courses*/ CREATE TABLE `courses` ( `id` INT(11) NOT NULL, `tid` INT(11), `title` VARCHAR(25), `length` INT(11), PRIMARY KEY (`id`) ); INSERT INTO courses VALUES (1,1, 'php',54), (2,1, 'xml',72), (3,2, 'sql',25); |
В результате получим таблицы с данными:
Отправка запроса:
Для того чтобы протестировать работоспособность сервиса, добавьте в правое окошко код запроса.
Пример: при помощи запроса выберите все данные из таблицы teachers, касаемые учителя с фамилией Иванов
SELECT * FROM `teachers` WHERE `name` = 'Иванов'; |
На дальнейших уроках SQL будет использоваться та же схема, поэтому необходимо будет просто копировать схему и вставлять в левое окно сервиса.
Онлайн визуализации схемы базы данных
Для онлайн визуализации схемы базы данных можно воспользоваться сервисом https://dbdesigner.net/:
- Создать свой аккаунт (войти в него, если уже есть).
- Щелкнуть по кнопке Go to Application.
- Меню Schema -> Import.
- Скопировать и вставить в появившееся окно код создания и заполнения таблиц базы данных
Далее к уроку 0 Язык sql создание таблиц
Подзапросы SQL-примеры
В этом разделе мы рассмотрим, как использовать подзапросы. У нас есть следующие две таблицы: ‘student‘ и ‘marks‘ с общим полем ‘StudentID‘:
студенты
отметки
Теперь нужно составить запрос, определяющий всех студентов, которые получают лучшие отметки, чем студент со StudentID — «V002». Но мы не знаем отметок студента «V002».
Поэтому нужно составить два SQL подзапроса в Select. Один запрос возвращает отметки (хранятся в поле «Total_marks») для «V002», а второй запрос выбирает учеников, которые получают лучшие оценки, чем результат первого запроса.
Первый запрос:
SELECT * FROM `marks` WHERE studentid = 'V002';
Результат запроса:
Результатом запроса будет 80.
Используя результат этого запроса, мы написали еще один запрос, чтобы определить учеников, которые получают оценки лучше, чем 80.
Второй запрос:
SELECT a.studentid, a.name, b.total_marks FROM student a, marks b WHERE a.studentid = b.studentid AND b.total_marks >80;
Результат запроса:
Два приведенных запроса определяют студентов, которые получают лучше оценки, чем студент StudentID «V002» (Abhay).
Можно объединить эти два запроса, вложив один запрос в другой. Подзапрос — это запрос внутри круглых скобок. Рассмотрим подзапроса в SQL пример:
Код SQL:
SELECT a.studentid, a.name, b.total_marks FROM student a, marks b WHERE a.studentid = b.studentid AND b.total_marks > (SELECT total_marks FROM marks WHERE studentid = 'V002');
Результат запроса:
Графическое представление подзапроса SQL:
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Псевдонимы для столбцов
Следующий оператор SQL создает два псевдонима, один для столбца CustomerID и CustomerName:
Пример
SELECT CustomerID AS ID, CustomerName AS Customer
FROM Customers;
Следующая инструкция SQL создает два псевдонима.
Обратите внимание, что он требует двойных кавычек или квадратных скобок, если имя псевдонима содержит пробелы:
Пример
SELECT CustomerName AS Customer, ContactName AS
FROM Customers;
Следующий оператор SQL создает псевдоним «Адрес», которые объединяют четыре столбца (адрес, почтовый индекс, города и страны):
Пример
SELECT CustomerName, Address + ‘, ‘ + PostalCode + ‘ ‘ + City + ‘, ‘ + Country
AS Address
FROM Customers;
Примечание: Чтобы получить инструкцию SQL, чтобы работать в MySQL использовать следующие:
SELECT CustomerName, CONCAT(Address,’, ‘,PostalCode,’, ‘,City,’, ‘,Country) AS Address
FROM Customers;
Понимание операторов SELECT
Как упоминалось во введении, SQL-запросы почти всегда начинаются с оператора . SELECT используется в запросах, чтобы указать, какие столбцы из таблицы должны быть возвращены в наборе результатов. Запросы также почти всегда включают , который используется для указания таблицы, к которой будет обращаться оператор.
Как правило, SQL-запросы следуют этому синтаксису:
Например, следующий оператор вернет весь столбец из таблицы:
Вы можете выбрать несколько столбцов из одной таблицы, разделяя их имена запятыми, например:
Вместо того, чтобы называть конкретный столбец или набор столбцов, вы можете следовать за оператором со звездочкой (), которая служит заполнителем, представляющим все столбцы в таблице. Следующая команда возвращает каждый столбец из таблицы :
WHERE используется в запросах для фильтрации записей, которые удовлетворяют указанному условию, и любые строки, которые не удовлетворяют этому условию, исключаются из результата. Предложение обычно соответствует следующему синтаксису:
Оператор сравнения в предложении WHERE определяет способ сравнения указанного столбца со значением. Вот некоторые распространенные операторы сравнения SQL:
| Оператор | Что он делает |
|---|---|
| = | тесты для равенства |
| != | тесты для неравенства |
| тесты для меньше, чем | |
| > | тесты для больше |
| тесты для менее чем или равный к | |
| >= | тесты для больше чем или равный к |
| BETWEEN | проверяет лежит ли в заданном диапазоне |
| IN | проверяет содержатся ли строки в наборе значений |
| EXISTS | тесты на соответствие строки существует при заданных условиях |
| LIKE | проверяет совпадает ли значение с указанной строкой |
| IS NULL | тесты для `NULL` значения |
| IS NOT NULL | тесты для всех других значений, чем `NULL` |
Например, если вы хотите найти размер обуви Ирмы, вы можете использовать следующий запрос:
SQL допускает использование подстановочных знаков, и это особенно удобно при использовании в предложениях WHERE. Знаки процента () представляют ноль или более неизвестных символов, а подчеркивания () представляют один неизвестный символ. Они полезны, если вы пытаетесь найти конкретную запись в таблице, но не уверены, что эта запись. Чтобы проиллюстрировать это, скажем, что вы забыли любимое блюдо нескольких своих друзей, но вы уверены, что это конкретное блюдо начинается с буквы «t». Вы можете найти его имя, выполнив следующий запрос:
Основываясь на вышеприведенном выводе, мы видим, что блюдо — это тофу.
Могут быть случаи, когда вы работаете с базами данных, в которых есть столбцы или таблицы с относительно длинными или трудно читаемыми именами. В этих случаях вы можете сделать эти имена более читабельными, создав псевдоним с ключевым словом . Псевдонимы, созданные с помощью , являются временными и существуют только на время запроса, для которого они созданы:
Здесь мы сказали SQL отображать столбец как, столбец как, а столбец как .
Примеры, которые мы рассмотрели до этого момента, включают в себя некоторые из наиболее часто используемых ключевых слов и предложений в запросах SQL. Они полезны для базовых запросов, но они бесполезны, если вы пытаетесь выполнить вычисление или получить скалярное значение (одно значение, а не набор из нескольких различных значений) на основе ваших данных. Это где агрегатные функции вступают в игру.
Оператор insert into: добавление записи в таблицу
Начнём с добавления новых данных в таблицу. Для добавления записи используется следующий синтаксис:
В начале добавим город в таблицу городов:
При добавлении записи не обязательно указывать значения для всех полей. Многие из полей имеют значения по умолчанию, которые сами заполняются при сохранении.
Теперь создадим запись о погоде за сегодняшний день.
При определении таблицы weather_log мы решили ссылаться на город, путём записи в поле city_id идентификатора города из таблицы cities. Так как мы только что добавили новый город, ничего не мешает использовать его идентификатор в записи о погоде.
Идентификатором города будет первичный ключ, который также был определён в качестве первого поля таблицы. Нумерация этого поля начинается с единицы, значит первая добавленная запись имеет идентификатор . Зная это, запрос на добавление записи о погоде в Санкт-Петербурге за третье сентября 2017 года выглядит так:
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.
Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
Создадим новую БД с именем «b_library для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
CREATE DATABASE b_library;
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library.
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
USE b_library;
В БД «b_library создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
CREATE TABLE tAuthors ( AuthorId INT IDENTITY (1, 1) NOT NULL, AuthorFirstName NVARCHAR (20) NOT NULL, AuthorLastName NVARCHAR (20) NOT NULL, AuthorAge INT NOT NULL );
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
INSERT tAuthors VALUES (‘Александр’, ‘Пушкин’, ’37’), (‘Сергей’, ‘Есенин’, ’30’), (‘Джек’, ‘Лондон’, ’40’), (‘Шота’, ‘Руставели’, ’44’), (‘Рабиндранат’, ‘Тагор’, ’80’);
Мы можем посмотреть в «tAuthors» записи, путем отправления в СУБД простого SQL запроса:
SELECT * FROM tAuthors;
В нашей БД «b_library» мы создали первую таблицу «tAuthors», заполнили «tAuthors» авторами книг и теперь можем рассмотреть различные примеры SQL запросов, которыми мы сможем взаимодействовать с БД.
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
SELECT
1) Выведем все имеющиеся у нас БД:
SELECT name, database_id, create_date FROM sys.databases;
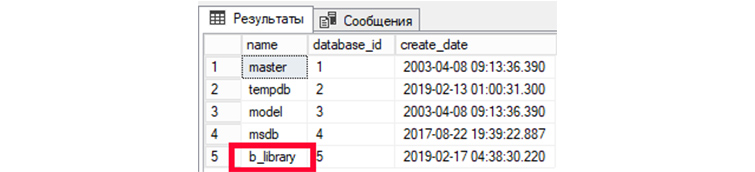
2) Выведем все таблицы в созданной нами ранее БД «b_library»:
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE=’BASE TABLE’
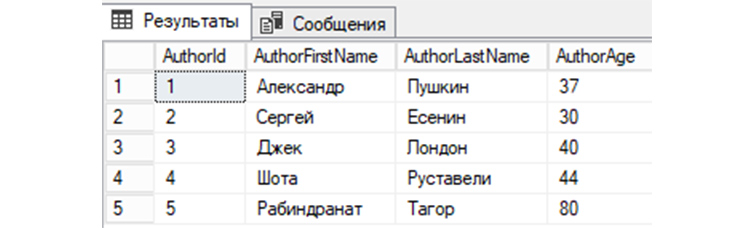
 3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
SELECT * FROM tAuthors;
 4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
SELECT count(*) FROM tAuthors;
 5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
SELECT * FROM tAuthors ORDER BY AuthorId OFFSET 3 ROWS FETCH NEXT 2 ROWS ONLY;
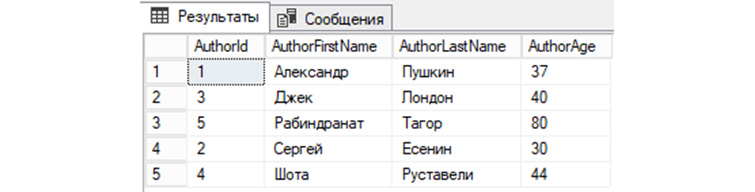
 6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
SELECT * FROM tAuthors ORDER BY AuthorFirstName;
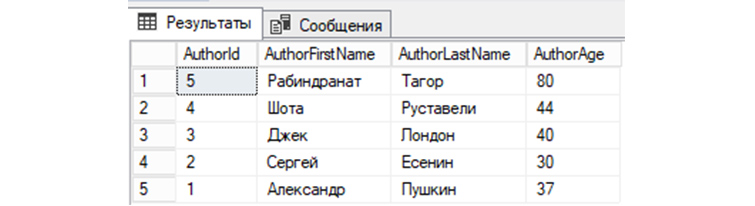
 7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
SELECT * FROM tAuthors ORDER BY AuthorId DESC;
 8) Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
8) Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
SELECT * FROM tAuthors WHERE AuthorFirstName=’Александр’;
 9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘се%’;
 10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘%ат’ ORDER BY AuthorId;
Видео курсы по схожей тематике:

SQL Базовый. Разбор ДЗ
Владимир Дымчук

MySQL Базовый
Андрей Бондаренко

Transact SQL
Станислав Зуйко
 11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
SELECT * FROM tAuthors WHERE AuthorId IN (2,4);
 12) Выберем в «tAuthors» такую запись AuthorAge, значение которой — наибольшее:
12) Выберем в «tAuthors» такую запись AuthorAge, значение которой — наибольшее:
SELECT max(AuthorAge) FROM tAuthors;
 13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
SELECT AuthorFirstName, AuthorLastName FROM tAuthors;
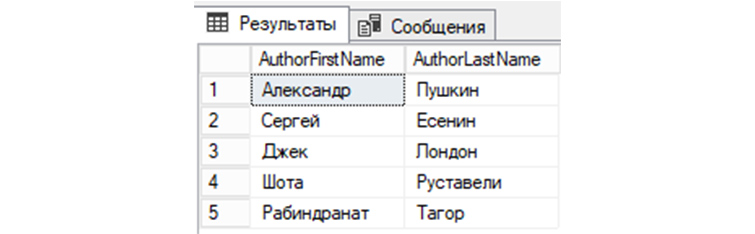 14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
SELECT AuthorId, AuthorFirstName, AuthorLastName FROM tAuthors WHERE AuthorId!=’3′;
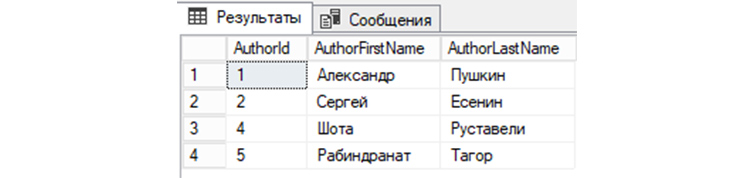
INSERT
INSERT – это вид запроса SQL, при применении которого СУБД выполняет добавление новых записей в БД. Добавим в «tAuthors» нового автора – Уильяма Шекспира, 51 год. Соответственно в поле AuthorFirstName добавится Уильям, в AuthorLastName добавится Шекспир, в AuthorAge – 51. В AuthorId, в нашем случае, автоматически добавится значение, инкрементированное от предыдущего на 1.
INSERT INTO tAuthors VALUES (‘Уильям’, ‘Шекспир’, ’51’);
Проверим:
SELECT * FROM tAuthors;
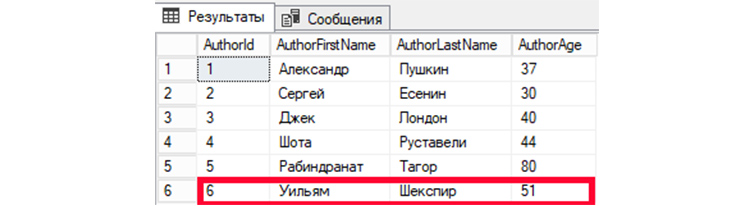
UPDATE
UPDATE – SQL запрос, позволяющий внести изменения или дописывать новую информацию в те записи, которые уже существуют.
Внесем корректировки в шестую запись (AuthorId = 6). Значения изменим для полей имени, фамилии и возраста автора.
UPDATE tAuthors SET AuthorFirstName = ‘Лев’, AuthorLastName=’Толстой’, AuthorAge = ’82’ WHERE AuthorId = ‘6’;
Затем, обратимся к БД, чтобы вывести все имеющиеся записи:
SELECT * FROM tAuthors;
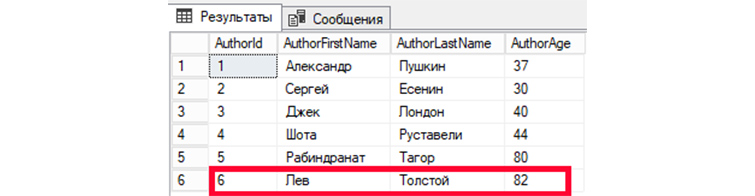
Мы видим изменения информации в записи автора под номером 6.
DELETE
DELETE – SQL запрос, выполняя который в СУБД производится операция удаления определенной строки из таблицы в БД.
Обратимся к «tAuthors» с командой на удаление строки, где AuthorId = 5:
DELETE FROM tAuthors WHERE AuthorId = ‘5’;
Чтобы увидеть изменения, снова обратимся к базе для вывода всех записей:
SELECT * FROM tAuthors;
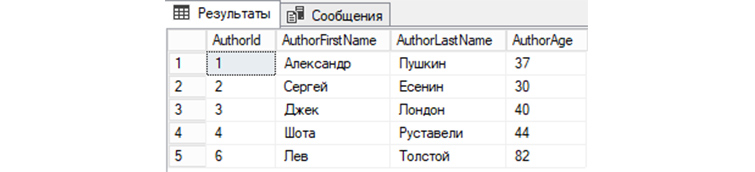
Мы видим, что запись автора под номером 5 теперь отсутствует в «tAuthors» и, соответственно, не выводится с другими записями.
DROP
DROP – ключевое слово в SQL, применяемое для удаления данных с помощью запроса. К примеру удаление некоторой таблицы из БД.
После рассмотрения ряда простых запросов к БД мы можем полностью удалить нашу таблицу «tAuthors целиком, выполнив простой SQL запрос:
DROP TABLE tAuthors;
Далее рассмотрим сложные запросы SQL.
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
СУБД
Существуют различные версии языка SQL. Эти разновидности специалисты иногда называют диалектами. Они создаются отдельными организациями и сообществами. Создатели выпускают более расширенные варианты устоявшихся языковых стандартов SQL.
Различные вариации спецификаций SQL предназначены для продуктивной работы с самыми разнообразными системами управления базами данных (СУБД). Каждая из них представляет собой систему программ, заточенную на выполнение определенных задач, достижения целей и работу с программными продуктами собственной инфраструктуры.
Чаще всего специалисты применяют СУБД, которые используют собственные стандарты SQL:
- Microsoft SQL Server – система управления БД, собственником которой является Microsoft. Особенно популярна в крупных компаниях корпоративного сектора. По сути является огромным комплексом приложений, который дает возможность сохранять, изменять, анализировать данные, реализовывать их безопасность и т.д. Использует диалект T-SQL (Transact-SQL);
- Oracle Database – СУБД от Oracle. Также очень популярна, в том числе в крупных компаниях корпоративного сектора. Сопоставима с предыдущей СУБД, по отношению к которой является основным конкурентом. Полнофункциональные версии обоих собственников являются достаточно дорогостоящими;
- MySQL – также принадлежит компании Oracle, но предполагает бесплатное использование. Этот продукт достаточно популярен в онлайн-сегменте. Именно на нем работает большинство веб-проектов (все они используют эту СУБД для хранения информации);
- PostgreSQL – свободная система, которая поддерживается и развивается сообществом пользователей. Также распространяется бесплатно, достаточно функциональна и пользуется широкой популярностью.
Возможности расширений в различных диалектах SQL могут иметь как общие свойства (основные конструкции), так и определенные отличия (в используемых типах данных, командах). Это объясняется тем, что диалекты создают и используют различные организации, преследующие разные цели и задачи.







