Введение в объектно-ориентированные базы данных
Содержание:
- Установка и настройка MS SQL Server Management Studio
- Мультимодельные СУБД на основе реляционной модели
- Классификации СУБД
- Виды баз данных
- Что такое база данных в SQL
- MySQL
- Другие модели баз данных (ООСУБД)
- Что такое база данных
- Чем хороши и плохи нереляционные базы данных: главные достоинства и недостатки
- СУБД крупных ЭВМ
- Современная СУБД состоит из:
- Проектирование баз данных
- На чем основан данный рейтинг
- MongoDB
- Все началось со «Спутника»
- Ключи
- Формы
- Для чего нужны
Установка и настройка MS SQL Server Management Studio
После того, как мы настроили сервер. Нужно настроить клиент. MS SQL Server Management Studio предоставляет удобный визуальный интерфейс для клиента и позволяет удобно разрабатывать и отправлять серверу запросы.
Установка его не сложнее плеера, поэтому останавливаться на этом не будем. Скачайте его с официального сайта Microsoft по одной из ссылок ниже.
- Скачать SQL Server Management Studio (16.5.1) https://download.microsoft.com/download/3/1/D/31D734E0-BFE8-4C33-A9DE-2392808ADEE6/SSMS-Setup-RUS.exe
- Скачать SQL Server Management Studio (17.0, версия-кандидат https://download.microsoft.com/download/B/2/3/B234198E-747D-4F89-9008-F39A7E4702D3/SSMS-Setup-RUS.exe
И установите. Программа сама определит, где у вас сервер. Просто следуйте инструкциям.
Мультимодельные СУБД на основе реляционной модели
Ведущими СУБД в настоящее время являются реляционные, прогноз Gartner нельзя было бы считать сбывшимся, если бы РСУБД не демонстрировали движения в направлении мультимодельности. И они демонстрируют. Теперь соображения о том, что мультимодельная СУБД подобна швейцарскому ножу, которым ничего нельзя сделать хорошо, можно направлять сразу Ларри Эллисону.
Автору, однако, больше нравится реализация мультимодельности в Microsoft SQL Server, на примере которого поддержка РСУБД документной и графовой моделей и будет описана.
Документная модель в MS SQL Server
О том, как в MS SQL Server реализована поддержка документной модели, на Хабре уже было две отличных статьи, ограничусь кратким пересказом и комментарием:
- Работаем с JSON в SQL Server 2016
- SQL Server 2017 JSON
Способ поддержки документной модели в MS SQL Server достаточно типичен для реляционных СУБД: JSON-документы предлагается хранить в обычных текстовых полях. Поддержка документной модели заключается в предоставлении специальных операторов для разбора этого JSON:
- для извлечения скалярных значений атрибутов,
- для извлечения поддокументов.
Вторым аргументом обоих операторов является выражение в JSONPath-подобном синтаксисе.
Абстрактно можно сказать, что хранимые таким образом документы не являются в реляционной СУБД «сущностями первого класса», в отличие от кортежей. Конкретно в MS SQL Server в настоящее время отсутствуют индексы по полям JSON-документов, что делает затруднительными операции соединения таблиц по значениям этих полей и даже выборку документов по этим значениям. Впрочем, возможно создать по такому полю вычислимый столбец и индекс по нему.
Дополнительно MS SQL Server предоставляет возможность удобно конструировать JSON-документ из содержимого таблиц с помощью оператора — возможность, в известном смысле противоположную предыдущей, обычному хранению. Понятно, что какой бы быстрой ни была РСУБД, такой подход противоречит идеологии документных СУБД, по сути хранящих готовые ответы на популярные запросы, и может решать лишь проблемы удобства разработки, но не быстродействия.
Наконец, MS SQL Server позволяет решать задачу, обратную конструированию документа: можно разложить JSON по таблицам с помощью . Если документ не совсем плоский, потребуется использовать .
Графовая модель в MS SQL Server
Поддержка графовой (LPG) модели реализована в Microsoft SQL Server тоже вполне предсказуемо: предлагается использовать специальные таблицы для хранения узлов и для хранения ребер графа. Такие таблицы создаются с использованием выражений и соответственно.
Таблицы первого вида сходны с обычными таблицами для хранения записей с тем лишь внешним отличием, что в таблице присутствует системное поле — уникальный в пределах базы данных идентификатор узла графа.
Аналогично, таблицы второго вида имеют системные поля и , записи в таких таблицах понятным образом задают связи между узлами. Для хранения связей каждого вида используется отдельная таблица.
Проиллюстрируем сказанное примером. Пусть графовые данные имеют схему как на приведенном рисунке. Тогда для создания соответствующей структуры в базе данных нужно выполнить следующие DDL-запросы:
Основная специфика таких таблиц заключается в том, что в запросах к ним возможно использовать графовые паттерны с Cypher-подобным синтаксисом (впрочем, «» и пр. пока не поддерживаются). Также на основе измерений производительности можно предположить, что способ хранения данных в этих таблицах отличен от механизма хранения данных в обычных таблицах и оптимизирован для выполнения подобных графовых запросов.
Более того, довольно трудно при работе с такими таблицами эти графовые паттерны не использовать, поскольку в обычных SQL-запросах для решения аналогичных задач потребуется предпринимать дополнительные усилия для получения системных «графовых» идентификаторов узлов (, , ; по этой же причине запросы на вставку данных не приведены здесь как слишком громоздкие).
Подводя итог описанию реализаций документной и графовой моделей в MS SQL Server, я бы отметил, что подобные реализации одной модели поверх другой не кажутся удачными в первую очередь с точки зрения языкового дизайна. Требуется расширять один язык другим, языки не вполне «ортогональны», правила сочетаемости могут быть довольно причудливы.
Классификации СУБД
Различают классификации СУБД по:
- модели данных:
- реляционные;
- объектно-ориентированные;
- объектно-реляционные.
- степени распределенности:
- способу доступа к БД:
Файл-серверные.
В данного типа СУБД файлы данных расположены централизованно на файл-сервере. СУБД находится на каждом клиентском компьютере (рабочей станции). Доступ СУБД к данным выполняется с помощью локальной сети. Чтения и обновления синхронизируются файловыми блокировками.
Преимущество данной архитектуры заключается в низкой нагрузке на процессор файлового сервера.
Недостатками являются:
высокая загрузка локальной сети;
- затрудненное либо невозможное обеспечение высокой степени надежности, доступности и безопасности.
Используются, как правило, в локальных приложениях, применяющих функции управления БД, а также в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД.
В настоящее время файл-серверную технологию считают устаревшей, а ее применение в крупных информационных системах — недостатком.
Примерами систем данного типа являются Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
Клиент-серверные.
Клиент-серверные СУБД располагаются на сервере вместе с базами данных и осуществляют доступ к ним непосредственно и монопольно. Все клиентские запросы обработки данных обрабатывает клиент-серверная СУБД централизованно.
Недостатком клиент-серверных СУБД являются повышенные требования к серверу.
К достоинствам относятся:
потенциально более низкая загрузка локальной сети;
удобное обеспечение высокой степени надежности, доступности и безопасности.
Примерами таких систем являются Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР.
Встраиваемые.
Встраиваемой СУБД является система, поставляемая в качестве составной части некоторого программного продукта и не требующая самостоятельной установки. Встраиваемые СУБД предназначены для локального хранения данных своего приложения и нерассчитанные на коллективное использование в сети. На физическом уровне встраиваемая СУБД, как правило, реализуется в виде подключаемой библиотеки. Доступ приложения к данным осуществляется с помощью SQL либо специальных программных интерфейсов.
Примерами таких систем являются OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР.
Виды баз данных
- Фактографическая – содержит краткую информацию об объектах некоторой системы в строго фиксированном формате;
- Документальная – содержит документы самого разного типа: текстовые, графические, звуковые, мультимедийные;
- Распределённая – база данных, разные части которой хранятся на различных компьютерах, объединённых в сеть;
- Централизованная – база данных, хранящихся на одном компьютере;
- Реляционная – база данных с табличной организацией данных;
- Неструктурированная (NoSQL) — база данных, в которой делается попытка решить проблемы масштабируемости и доступности за счёт атомарности (англ. atomicity) и согласованности данных, но не имеющих четкой (реляционной) структуры.
Одно из основных свойств БД – независимость данных от программы, использующих эти данные. Работа с базой данных требует решения различных задач, основные из них следующие:
- создание базы;
- запись данных в базу;
- корректировка данных;
- выборка данных из базы по запросам пользователя.
Задачи этого списка называются стандартными.
Следующее понятие, связанное с базой данных: программа для работы с базой данных – это программа, которая обеспечивает решение требуемого комплекса задач. Любая подобная программа должна уметь решать все задачи стандартного набора.
База данных в разных системах имеет различную структуру.
В ПВЭМ обычно используются реляционные БД – в таких базах файл является по структуре таблицей. В ней столбцы называются полями, строки – записями.
В БД содержатся банные некоторого множества объктов. Каждая запись содержит данные одного объекта. Каждая такая БД определяется именем файла, списком полей, шириной полей. Например, БД Школа (Ученик, Класс, Адрес).
Примером БД может служить расписание движения поездов или автобусов. Здесь каждая строчка – запись отражает данные строго одного объекта. База включает поля: номер рейса, маршрута следования, время отправления и т.д.
Классическим примером БД является и телефонный справочник. Запрос к базе данных – это предписание, указывающее, какие данные пользователь желает получить из базы.
Некоторые запросы могут представлять собой серьёзную задачу, для решения которой потребляется составлять сложную программу. Например, запрос к базе – автобусному расписанию: определить разницу в среднем интервале отправления автобусов из Ростова в Таганрог и из Ростова в Шахты.
Объекты для работы с базами данных
Для создания приложения, позволяющего просматривать и редактировать базы данных, нам потребуется три звена:
- набор данных
- источник данных
- визуальные элементы управления
В нашем случае эта триада реализуется в виде:
- Table
- DataSource
- DBGrid
Table подключается непосредственно к таблице в базе данных. Для этого нужно установить псевдоним базы в свойстве DataBaseName и имя таблицы в свойстве TableName, а затем активизировать связь: свойство .
Однако, поскольку Table является невизуальным компонентом, хотя связь с базой и установлена, пользователь не в состоянии увидеть какие – либо данные. Поэтому необходимо добавить визуальные компоненты, отображающие эти данные. В нашем случае это сетка DBGrid. Сетка сама по себе «не знает», какие данные ей нужно отображать, её нужно подключить к Table, что и делается через компонент – посредник .
А зачем нужен компонент – посредник? Почему бы сразу не подключаться к Table?
Допустим, несколько визуальных компонентов – таблица, поля ввода и т.п. подключены к таблице. А нам нужно быстро переключить их все на другую подобную таблицу. С DataSource это сделать несложно — достаточно просто поменять свойство t, а вот без пришлось бы менять указатели у каждого компонента.
Приложения баз данных – нить, связывающая БД и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table(таблица, навигационный доступ)
- Query(запрос, реляционный доступ)
Визуальные компоненты:
- Сетки DBGrid, DBCtrlGrid
- Навигатор DBNavigator
- Всяческие аналоги Lable, Editи т.д.
- Компоненты подстановки
Что такое база данных в SQL
SQL-запросы обращаются к данным в виде таблиц, то есть к реляционным базам данных. Упрощенный вариант такой базы — это таблицы Excel, в которых информация также упорядочена в столбцы и строки.
Основные понятия реляционной модели:
1. Отношение — это сама таблица, она двумерная и состоит из столбцов и строк.
2. Атрибут — столбец в таблице, который содержит один конкретный параметр: название, тип, дату, стоимость или другую характеристику.
3. Домен — это допустимые значения для каждого атрибута. Например, в столбце «Имя» или «Название» значения должны представлять собой набор буквенных символов, но они не могут начинаться с «ь» или «ъ» и не могут быть записаны числами.
4. Кортеж (строка или запись) — это табличная строка с порядковым номером, в которой содержится информация об одном конкретном объекте.
5. Значение — элемент таблицы, который находится на пересечении столбцов и строк.
6. Ключ — это самый важный столбец в таблице, за счет этих значений и происходит взаимодействие в реляционной базе данных, он связывает таблицы между собой.
Ключи бывают нескольких видов:
- Первичный ключ — идентификатор, такой как индекс или артикул.
- Потенциальный ключ — другое уникальное значение, которое может служить идентификатором.
- Внешний ключ — столбец-ссылка, используется для объединения двух таблиц, каждое значение внешнего ключа обязательно соответствует первичному ключу в другой таблице.
Например, для решения задачи — выбрать все пиццерии, которые смогут доставить пиццу с ананасами после 23:00, — кроме основной таблицы с графиками работы понадобятся также таблицы с ассортиментом каждого заведения, а также таблицы с составом каждой пиццы (чтобы понять, есть ли в ней ананасы). Все эти таблицы будут связаны между собой с помощью ключей.
Список пиццерий в городе
Ассортимент одной из пиццерий с ключом id — 1
MySQL
MySQL работает на Linux, Windows, OSX, FreeBSD и Solaris. Можно начать работать с бесплатным сервером, а затем перейти на коммерческую версию. Лицензия GPL с открытым исходным кодом позволяет модифицировать ПО MySQL.
Эта система управления базами данных использует стандартную форму SQL. Утилиты для проектирования таблиц имеют интуитивно понятный интерфейс. MySQL поддерживает до 50 миллионов строк в таблице. Предельный размер файла для таблицы по умолчанию 4 ГБ, но его можно увеличить. Поддерживает секционирование и репликацию, а также Xpath и хранимые процедуры, триггеры и представления.
- Разработчик: Oracle Corporation
- Написана на C, C++
- Последняя версия: 8.0.16
- Скачать: MySql
Особенности
- Масштабируемость.
- Лёгкость использования.
- Безопасность.
- Поддержка Novell Cluster.
- Скорость.
- Поддержка многих операционных систем.
Другие модели баз данных (ООСУБД)
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Пожалуйста, оставляйте ваши отзывы по текущей теме статьи. За комментарии, отклики, дизлайки, лайки, подписки низкий вам поклон!
Что такое база данных
Обычно под базой данных принято понимать любой набор информации, который хранится определенным образом, и этой информацией можно воспользоваться.
Однако если говорить о компьютерных базах данных, то здесь, конечно же, речь идет о так называемых реляционных базах данных.
Логически такая база данных представлена в виде таблиц, в которых и хранится вся эта информация.
Физически база данных представляет собой, конечно же, обычные файлы, созданные в специальном формате.
И здесь возникает вопрос, если база данных — это файлы, созданные в специальном формате, то как создать такие файлы и редактировать их?
Для этого, как Вы понимаете, нужен специальный инструмент, т.е. программа, которая могла бы создавать базы данных и управлять ими, иными словами, работать с файлами базы данных.
Такой программой как раз и выступает СУБД, т.е. система управления базами данных.
Чем хороши и плохи нереляционные базы данных: главные достоинства и недостатки
По сравнению с классическими SQL-базами, нереляционные СУБД обладают следующими преимуществами:
- линейная масштабируемость – добавление новых узлов в кластер увеличивает общую производительность системы ;
- гибкость, позволяющая оперировать полуструктирированные данные, реализуя, в. т.ч. полнотекстовый поиск по базе ;
- возможность работать с разными представлениями информации, в т.ч. без задания схемы данных ;
- высокая доступность за счет репликации данных и других механизмов отказоустойчивости, в частности, шаринга – автоматического разделения данных по разным узлам сети, когда каждый сервер кластера отвечает только за определенный набор информации, обрабатывая запросы на его чтение и запись. Это увеличивает скорость обработки данных и пропускную способность приложения .
- производительность за счет оптимизации для конкретных видов моделей данных (документной, графовой, колоночной или «ключ‑значение») и шаблонов доступа ;
- широкие функциональные возможности – собственные SQL-подобные языки запросов, RESTful-интерфейсы, API и сложные типы данных, например, map, list и struct, позволяющие обрабатывать сразу множество значений .
Обратной стороной вышеуказанных достоинств являются следующие недостатки:
- ограниченная емкость встроенного языка запросов . Например, HBase предоставляет всего 4 функции работы с данными (Put, Get, Scan, Delete), в Cassandra отсутствуют операции Insert и Join, несмотря на наличие SQL-подобного языка запросов. Для решения этой проблемы используются сторонние средства трансляции классических SQL-выражений в исполнительный код для конкретной нереляционной базы. Например, Apache Phoenix для HBase или универсальный Drill.
- сложности в поддержке всех ACID-требований к транзакциям (атомарность, консистентность, изоляция, долговечность) из-за того, что NoSQL-СУБД вместо CAP-модели (согласованность, доступность, устойчивость к разделению) скорее соответствуют модели BASE (базовая доступность, гибкое состояние и итоговая согласованность) . Впрочем, некоторые нереляционные СУБД пытаются обойти это ограничение с помощью настраиваемых уровней согласованности, о чем мы рассказывали на примере Cassandra. Аналогичным образом Riak позволяет настраивать требуемые характеристики доступности-согласованности даже для отдельных запросов за счет задания количества узлов, необходимых для подтверждения успешного завершения транзакции . Подробнее о CAP-и BASE-моделях мы расскажем в отдельной статье.
- сильная привязка приложения к конкретной СУБД из-за специфики внутреннего языка запросов и гибкой модели данных, ориентированной на конкретный случай ;
- недостаток специалистов по NoSQL-базам по сравнению с реляционными аналогами .
Подводя итог описанию основных аспектов нереляционных СУБД, стоит отметить некоторую некорректность запроса «NoSQL vs SQL» в связи с разными архитектурными подходами и прикладными задачами, на которые ориентированы эти ИТ-средства. Традиционные SQL-базы отлично справляются с обработкой строго типизированной информации не слишком большого объема. Например, локальная ERP-система или облачная CRM. Однако, в случае обработки большого объема полуструктурированных и неструктурированных данных, т.е. Big Data, в распределенной системе следует выбирать из множества NoSQL-хранилищ, учитывая специфику самой задачи. В частности, для самостоятельных решений интернета вещей (Internet of Things), в т.ч. промышленного, отлично подходит Cassandra, о чем мы рассказывали здесь
А в случае многоуровневой ИТ-инфраструктуры на базе Apache Hadoop стоит обратить внимание на HBase, которая позволяет оперативно, практически в режиме реального времени, работать с данными, хранящимися в HDFS
Нереляционные СУБД находят больше областей приложений, чем традиционные SQL-решения
Источники
- https://ru.wikipedia.org/wiki/NoSQL
- https://aws.amazon.com/ru/nosql/
- https://ru.bmstu.wiki/NoSQL
- https://tproger.ru/translations/types-of-nosql-db/
- https://habr.com/ru/sandbox/113232/
СУБД крупных ЭВМ
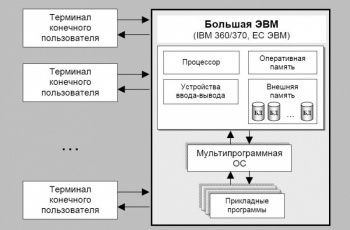
Данный этап развития связан с организацией баз данных на больших машинах типа IBM 360/370, ЕС-ЭВМ и различных моделях фирмы Hewlett Packard. В таком случае информация хранилась во внешней памяти центральной ЭВМ. Пользователями баз данных были фактически задачи, запускаемые в основном в пакетном режиме. Интерактивный режим доступа обеспечивался с помощью консольных терминалов, которые не обладали собственными вычислительными ресурсами (процессором, оперативной памятью, внешней памятью) и служили только устройствами ввода-вывода для центральной ЭВМ. Программы доступа к БД писались на различных языках программирования и запускались как обычные числовые программы. Особенности данного этапа:
- Все СУБД базируются на мощных мультипрограммных ОС (Unix и др.).
- Поддерживается работа с централизованной БД в режиме распределенного доступа. Функции управления распределением ресурсов выполняются операционной системой.
- Поддерживаются языки низкого манипулирования данными, ориентированные на навигационные методы доступа к данным. Значительная роль отводится администрированию данных.
- Проводятся серьезные работы по обоснованию и формализации реляционной модели данных. Была создана первая система (System R), реализующая идеологию реляционной модели данных.
- Проводятся теоретические работы по оптимизации запросов и управлению распределенным доступом к централизованной БД, было введено понятие транзакции.
- Большой поток публикаций по всем вопросам теории БД. Результаты научных исследований активно внедряются в коммерческие СУБД.
- Появляются первые языки высокого уровня для работы с реляционной моделью данных (SQL), однако отсутствуют стандарты для этих языков.
Современная СУБД состоит из:
- ядра — части программ СУБД, отвечающих за управление данными в памяти и журнализацию
- Процессора языка базы данных, обеспечивающего оптимизацию запросов на извлечение и изменение данных, и создание БД
- Подсистемы поддержки времени исполнения, интерпретирующую программы манипуляции данными, которые создают интерфейс пользователя СУБД
- Сервисных программ (внешних утилит), которые обеспечивают прочие возможности по обслуживанию информационных систем.
Так как через СУБД осуществляют все процессы, применимые к базам данных, следовательно, лучше будет выделить только её основные возможности.
Проектирование баз данных
Проектирование — самая трудная задача при работе с данными. Оно заключается не только в том, чтобы создать таблицу, указав наименование столбцов и тип данных. Это гораздо более сложный процесс, требующий специализированных знаний и умений. Говоря о типах баз данных в столбцах, подразумевается, например, способ их записи, который бывает символьный (строковый), числовой, календарный, NULL.
Основная сложность заключается в том, что мощность наших компьютеров ограничена. И пока данных мало, таблиц и строк тоже немного, поэтому машина обрабатывает информацию достаточно быстро. Но с течением времени информации становится всё больше, что может стать причиной снижения быстродействия. Работа машины будет замедляться, времени на обработку запросов потребуется всё больше. Добавить новую запись в таблицу не станет проблемой для реляционной СУБД, а вот выборка данных может превратиться в весьма ресурсоёмкую операцию. Хотя, многое будет зависеть и от настроек СУБД.
На чем основан данный рейтинг
В одной из прошлых статей – ТОП 7 популярных языков программирования, за основу мы брали достаточно много различных источников, но если говорить про базы данных, то таких источников гораздо меньше. Однако все равно существуют официальные рейтинги и другие аналитические данные, которые показывают популярность СУБД.
Некоторые рейтинги основываются на частоте упоминаний в запросах поисковых систем, т.е. если люди чаще ищут информацию по БД в интернете, значит, можно сделать вывод, что эта база данных пользуется популярностью. А некоторые ориентируются на количество заданных вопросов по конкретной базе на специализированных форумах, т.е. если больше вопросов задают по работе с какой-то конкретной базой данных, значит ее используют много людей, и она популярна.
В любом случае такие рейтинги, как, впрочем, и рейтинги языков программирования, не отражают точную фактическую популярность той или иной СУБД, так как основываются на каком-то одном показателе. И как результат, рейтинги просто противоречат друг другу.
Однако если проанализировать все источники, то можно определить несколько баз данных, которые наиболее часто встречаются в топе каждого рейтинга, тем более что состав ТОПа баз данных во всех рейтингах примерно одинаковый, только места у СУБД разные.
На основе всех этих источников можно сделать вывод, что определённые базы данных действительно являются популярными по всем показателям, а не только по какому-то одному.
Таким образом, чтобы упростить Вам задачу в анализе всей необходимой информации, в этом материале представлен ТОП 5 СУБД, который основан на данных всех популярных официальных рейтингов и показателей за предыдущий год.
Источники данных (официальные показатели и рейтинги СУБД):
- PYPL (PopularitY of Programming Language) – рейтинг основывается на данных поисковой системы Google;
- Stack Overflow – основывается на количестве вопросов, связанных с базой данных;
-
DB-Engines – данный рейтинг основывается на многих показателях:
- Данные поисковых систем Google, Bing и Yandex;
- Количество вопросов на Stack Overflow и DBA Stack Exchange;
- Количество предложений о работе на Indeed и Simply Hired, в которых упоминается система;
- Количество профилей в профессиональных сетях LinkedIn и Upwork, в которых упоминается система;
- Количество упоминаний в Twitter.
- Кроме все прочего учитывались данные компании РУССОФТ, которая проводила специальные опросы софтверных компаний об используемых инструментах программирования, и в частности СУБД.
MongoDB
Самая популярная NoSQL система управления базами данных. Лучше всего подходит для динамических запросов и определения индексов. Гибкая структура, которую можно модифицировать и расширять. Поддерживает Linux, OSX и Windows, но размер БД ограничен 2,5 ГБ в 32-битных системах. Использует платформы хранения MMAPv1 и WiredTiger.
- Разработчик: MongoDB Inc. в 2007
- Написана на C++
Особенности
- Высокая производительность.
- Автоматическая фрагментация.
- Работа на нескольких серверах.
- Поддержка репликации Master-Slave.
- Данные хранятся в форме документов JSON.
- Возможность индексировать все поля в документе.
- Поддержка поиска по регулярным выражениям.
Все началось со «Спутника»
Системы управления базами данных, как и интернет, и многие другие новации, своим появлением обязаны «Моменту Спутника» (Sputnik Moment). Так в конце пятидесятых назвали ускоряющий импульс, который получила в ответ на запуск Советским Союзом 4 октября 1957 г. и другие успехи СССР в космосе вся американская индустрия. И прежде всего нарождающаяся компьютерная. В 1961 г. президент Джон Кеннеди (John Kennedy) предложил в качестве «главного ответа Советам» лунную программу «Аполлон». Для ее выполнения требовались невиданные прежде масштабы кооперации соисполнителей, поэтому было решено автоматизировать управление поставками комплектующих.
 Запуск первого искусственного спутника Земли оказал огромное влияние на технологическую гонку второй половины XX века
Запуск первого искусственного спутника Земли оказал огромное влияние на технологическую гонку второй половины XX века
В соответствие с этим решением в 1965 г. IBM и другие участники программы разработали задание на триединую систему Information Control System and Data Language/Interface (ICS/DL/I), включающую подсистему управления информацией, язык данных и интерфейс. Предназначением системы была автоматизации работы со списками, состоящими из записей о комплектующих. В последующем IBM переработала ICS/DL/I в коммерческий продукт Information Management System/360 (IMS/360), продолжающий работать на некоторых мэйнфреймах до сегодняшнего дня.
Созданием IMS DBMS был заложен краеугольный камень в создание современного стека корпоративных информационных систем, характерного отделением кода приложений от данных специально созданным программным обеспечением. Этот тип программного обеспечения стали называть Database Management System (DBMS). А когда появились СУБД других типов, то IMS и ее аналоги (IDS, IDMS, Total) отнесли к классу навигационных или сетевых.
Ключи
Базы данных СУБД MS Access имеют в таблицах одно главное — ключевое — поле. По умолчанию оно, как уже было сказано, обязательно к заполнению. Кроме того, на него накладывается необходимость быть уникальным, что значит, что уже введенное значение в ключевом поле нельзя будет ввести в ключевом поле другой записи этой же таблицы. При необходимости можно добавить дополнительное ключевое поле, с менее строгими правилами — уникальность выбирается разработчиком БД. При помощи ключевых полей осуществляют связи между таблицами базы данных.
Ключи подразделяются на:
-
первичные (основные) — непосредственно сама связь;
-
вторичные (внешние) — способ связи.
Формы
Используются в качестве средства для ввода новой информации в таблицу. Преимуществом форм становится их удобный для пользователя вид — разработчик может использовать макет формы или создать совершенно новую. На этот объект можно поместить кнопки, переключатели и многое другое
В числе прочих особое внимание приковывает к себе кнопочная форма, представляющая собой модифицированный диспетчер задач, составляемый пользователем “под себя”. На нее можно поместить основные функции работы с базой данных — вход, выход, заполнение таблиц, просмотр данных
Обычные формы можно также включить в кнопочную.
Для чего нужны
Вот основные задачи БД на примере гардеробной:
- Сохранить наши данные по запросу — чтобы вы могли открыть дверь, повесить куртку, закрыть дверь и больше не думать ни о куртке, ни о гардеробной.
- Изменить наши данные по запросу — чтобы можно было легко извлечь из гардеробной все дырявые носки и положить на их место целые.
- Найти эти данные по запросу — чтобы быстро найти приличный пиджак или парный носок.
- Не дать прочитать эти данные тем, кому не следует, а кому надо — дать. Например, младший брат может смотреть на ваши кроссовки, но не может их брать. А девушка (или парень) может положить свои вещи, но только на определённую полку.
- Поддерживать порядок и не дать захламиться — если вам было лень и вы просто кинули толстовку куда попало, чтобы гардеробная либо сама нашла, куда эту толстовку правильно положить, либо сказала: «Э БРАТ ЗАЧЕМ ЗАХЛАМЛЯЕШЬ ПОЛОЖИ НОРМАЛЬНО ДАВАЙ»
- Масштабироваться — чтобы вы могли просто вешать в гардеробную вещи и не думать об объёме полок.
- Не потерять данные — если квартира будет гореть, приличная гардеробная не должна даже нагреться. Или, если она всё-таки горит, чтобы где-то в защищённом подземном гараже была точная копия этой гардеробной со всеми актуальными вещами.







