Настройка и использование словоеб
Содержание:
- Как работать в Словоеб
- 4 Словоеб, как пользоваться?
- Парсинг поисковых фраз в Словоебе
- Как работать со Словоебом
- 1Описание
- Что такое Словоёб
- Настройка Slovoeb
- Как работать с программой Словоёб?
- Подбор ключевых слов с помощью Словоёб
- Словоеб: настройка
- Словоеб: настройка
- Приступаем к работе
- Цели и задачи новой программы Slovoeb
- Как парсить ключевые запросы в СловоЁБ
- Минус-слова Словоеба
- Советы для грамотного составления семантического ядра
Как работать в Словоеб
Первое, что необходимо сделать – создать новый проект.

Перед нами откроется окно программы. Сверху основная вкладка «Сбор данных», в которой слева расположены основные кнопки управления. Кнопка «Стоп-слова» позволяет игнорировать минус-слова при сборе семантики.
Например, вы продвигаете коммерческий сайт только по городу Москва, и вам не нужны другие города. Для этого скачивайте составленный мной список всех городов России, удаляете оттуда город Москва и используете в качестве стоп-слов, чтобы почистить свой список запросов.
Далее инструменты для парсинга ключевых фраз, для работы с Вордстатом: правой и левой колонкой, поисковыми подсказками. Кнопки вычисления KEI и сбора частотностей.
Большую часть окна занимает пока еще не заполненное поле с названиями колонок сверху. Здесь будут появляться напарсенные ключевые слова, их частотности и т. д.
Снизу три вкладки:
- Новости, которые порядком устарели.
- Журнал событий – в котором будет отображаться ход выполнения парсинга, появляться ошибки и логи.
- Вкладка «Статистика», будет выводить статистику по ключам.

Внизу панель для настройки регионов:
- Яндекс.Вордстат;
- Директ;
Замыкающаяся на себя стрелка поможет вам перезагрузить процесс, если вдруг все зависнет или остановится.
Парсинг запросов
В начале выбираем регион, в нижней панели программы.
Чтобы добавить слова для парсинга переходим на вкладку «Данные», далее нажимаем на большой зеленый плюс. В появившееся окошко вводим одну или несколько фраз.
Если хотите напарсить фразы из левой колонки Яндекс Вордстат, то для этого на вкладке «Сбор данных» кликните по значку с красными вертикальными полосками. В появившееся окошко добавляете одну или несколько фраз. Потом кликаете «Начать сбор».

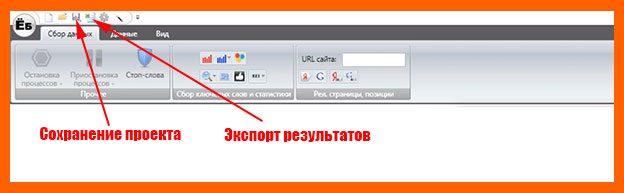
Экспорт результатов
После сбора всех ключей их необходимо экспортировать в excel-файл, кликнув на соответствующую кнопочку вверху окна программы.
Для сохранения всего проекта достаточно кликнуть по дискетке.
4 Словоеб, как пользоваться?
Теперь разберем основные элементы интерфейса.
- Для начала необходимо создать проект (кликнуть на иконку Еб в левом верхнем углу).
- Выбираем имя проекта и место хранения, после того как нажмете «Сохранить», проект откроется в окне программы Словоеб. Создаем проект
- В нижней части программы находятся настройки регионов. Первая слева отвечает за Яндекс.Вордстат, вторая — за Яндекс.Директ и третья за Гугл. Подбираем регионы
- Чуть выше настроек регионов имеются 3 вкладки «Новости», которые уже не обновляются, «Журнал событий» в нем фиксируются логии всех операций и «Статистика» — тут отображаются данные по собранным ключевым словам.
- Основное пространство занимает сама таблица, в которой будут указаны ключевые слова и их частотности. Чуть правее находится поле «Управление группами» в нем вы можете разбивать запросы на группы и работать уже с ними.
- В самом верху находится кнопка «Стоп слова» она позволяет игнорировать не нужные слова на раннем этапе сбора ядра.
Парсинг поисковых фраз в Словоебе
Познакомившись с интерфейсом этой замечательной программы и проставив все нужные настройки, пора переходить к процессу парсинга поисковых запросов из сервиса статистики Яндекса. Далее я расписал пошаговый план сбора будущих ключевых слов в Словоебе. Для примера использовал данные Вордстата по запросу «инфобизнес».
Создаем новый проект (или открываем готовый). В самом начале парсинга нужно сделать свой проект, в котором будут находиться нужные нам поисковые фразы по заданным словам. Обычно каждый проект у меня называется по одной теме.
Указываем стоп-слова. Если мы знаем, какие слова мы не хотели бы видеть в спарсенных поисковых запросах, то их необходимо прописать. Например, для коммерческого сайта этими словами будут «бесплатно», «халява», «скачать» и т.д. Таким образом мы облегчаем процесс сбора будущих ключевиков.
Выбираем регион продвижения. Для того, чтобы получить реальные параметры спарсенных поисковых запросов, необходимо задать нужный регион (аналогичный в сервисе Вордстат). Например, если Ваш блог продвигается по всей России, то в программе необходимо назначить такую же географическую область. Обычно я использую регион «Москва» или «Россия». В данном примере взят второй вариант. Выбрав регион, нажимаем левую кнопку парсинга Вордстата (кнопка №5) и получаем таблицу данных с поисковыми запросами и базовыми частотностями:
Фильтруем полученные запросы. Когда процесс сбора всех поисковых запросов закончился, мы должны пробежаться по ним и удалить те фразы, которые не подходят для нашей тематики. Поверьте, в каждой теме таких слов бывает достаточно. Но их обязательно нужно удалить, потому что они никак не дадут нам ключевые слова для продвижения нашего блога. Чтобы удалить их, сначала надо их выделить в таблице (с помощью чек-боксов):
Затем подводим мышку к нашей таблице с поисковыми фразами, нажимаем ее правую кнопку и в выпадающем меню выбираем соответствующую команду удаления:
Таким образом на выходе мы получаем уже тематические слова по нашим заданным фразам со своими базовыми частотностями. Теперь можно получить и другие параметры поисковых фраз, благодаря которым мы сможем выбрать самые качественные будущие ключевые слова.
Собираем точные частотности. На этом этапе парсинга нашей задачей является получение уточняющих параметров запросов от пользователей поисковых систем — они будут нужны при отборе качественных ключевых слов. Для этого нажимаем кнопку по сбору частотностей (на картинке интерфейса — элемент под номером 7) и выбираем из появившегося меню строку «Собрать частотности !» (картинка справа).
Удаляем слова-пустышки. После того, как в таблице данных наши спарсенные поисковые фразы получат свое значение точной частотности, необходимо удалить из нее так называемые слова-пустышки (точная частотность которых крайне мала и обычно имеет значение от 0 до 2). Удалить можно таким же способом, который показан выше по тексту.
В итоге мы получаем таблицу с данными частотностей для каждого полученного из поиска запроса. Теперь можно сделать ряд дополнительных действий (узнать конкуренцию по версии Словоеба, определить самую релевантную страницу по каждому ключевику) или экспортировать полученные поисковые фразы для дальнейшей обработки.
Таким образом, мы прошли весь процесс парсинга левой колонки Вордстата. Если нам необходимо для расширения тематики узнать дополнительные слова, можно воспользоваться парсингом правой колонки (процесс сбора запросов там такой же, какой мы сейчас рассмотрели).
Как работать со Словоебом
Теперь мы расскажем, как работать со Словоебом. После того как мы настроили программу, приступаем к работе с ней.
Перед началом сбора ключей необходимо определиться, что и откуда мы будем собирать. Словоеб умеет собирать слова с соответствующими им базовыми частотностями левой и правой колонки Yandex.Wordstat, Rambler.AdStat и поисковые подсказки с популярных поисковых систем.
- Открываем окно пакетного сбора фраз левой колонки Yandex.Wordstat.
- Берем наши маркеры или основные запросы и добавляем их. Запросы в проект можно добавить вручную или сразу весь файл со списком. Словоеб принимает только текстовые файлы (.txt).
- После того как мы добавили наши ключи, нажимаем кнопку «Начать сбор», которая находится в нижнем левом углу окна с ключами.
- Ждем, пока программа завершит сбор. Это может занять от нескольких минут до нескольких часов, в зависимости от количества ключей.
Мы можем сразу распределить наши слова на группы, для большего удобства. К примеру, если у вас есть несколько ключей, которые относятся к разным группам, мы можем автоматически создать группы на основе этих фраз и собрать ключи по каждой фразе в отдельные группы.
Предлагаем рассмотреть, как это реализуется, на примере: мы будем собирать фразы из левой колонки Yandex.Wordstat для трех фраз, которые будут относиться к разным посадочным страницам на сайте. Возьмем следующие ключи: «сумки шопперы», «женские сумки на длинной ручке», «женские сумки на каждый день».
Чтобы у нас не было дублей, поставим галочку напротив «Не добавлять фразу, если она уже есть в любых других группах»
Добавляем наши фразы и нажимаем на кнопку распределения фраз на группы. Каждая новая фраза должна начинаться с новой строки.
Теперь для каждой фразы автоматически создалась группа с названием фразы. По необходимости, мы можем вручную добавить необходимые нам фразы в любую из групп. В нашем примере мы этого делать не будем, а просто нажмем кнопку «Начать сбор».
Весь сбор отображается в «Журнале событий» и «Статистике».
После сбора мы видим наши группы (1) и список собранных фраз (2).
В разделе «Как работать со Словоебом» нашей инструкции мы показали основные принципы работы с программой для помощи сбора семантического ядра «Словоеб».
1Описание
- Хочу просто протестировать. Подключить только одну учетную запись яндекса (это просто почтовый ящик с логином и паролем) и подключить один прокси сервер. Это даст понимание как всё работает.
- Собрать небольшое ядро. Подключить 2-3 учетные записи яндекса и такое же количество прокси серверов. Сможете за короткое время собрать ядро для статьи или тематической страницы сайта
- С серьезными намерениями.Подключить 5 учетных записей яндекса и такое же количество прокси серверов, а также настроить и подключить Антикапчу
Программа Словоеб была разработана для поиска ключевых слов и для дальнейшего формирования семантического ядра. Распространяется бесплатно и это
упрощенная версия программы Key Collector. Соответственно, большая часть настроек Словоеба перекочевала в платную программу
Key Collector.
Что такое Словоёб
Словоёб (Slovoeb) — бесплатная (и значительно урезанная по функционалу) версия программы Key Collector, полюбившейся профессиональным оптимизаторам. Большинство функций КейКоллетора обычному пользователю вряд ли понадобится, поэтому можно обойтись Словоёбом для решения главной задачи — подбора ключевых слов.
Кстати, платный KeyCollector позволяет парсить слова и из Google AdWords — это особенно полезно, если ваш сайт ориентирован в первую очередь на страны, где основной трафик даёт именно Гугл. Бесплатный Slovoeb ограничен только Яндексом.
Программа не требует установки. Просто распакуйте архив в любое удобное место на компьютере и запустите Slovoeb.exe. В дальнейшем все ваши настройки будут храниться в выбранной папке. Перед началом работы не забудьте прочитать материал о правильном подборе ключевых слов — информация в статье актуальна и для этой программы.
Настройка Slovoeb
Вот что мы увидим после запуска:
Прежде чем приступить к работе, необходимо выполнить ряд настроек. Первое — указать аккаунты Яндекса для парсинга ключевых слов. Напоминаю, что работать в Вордстате можно только после авторизации. Поэтому советую создать почту Яндекс, штук пять аккаунтов, специально предназначенных для Словоёба. Не используйте спецсимволы в паролях этих аккаунтов!
Не советую использовать свой настоящий аккаунт, так как программа делает очень много запросов к Яндексу за единицу времени, за что можно получить санкции.
Нажмите на значок шестерёнки в верхней левой части окна программы и перейдите в настройки.
Выберите вкладку Yandex.Direct и введите данные аккаунтов в формате логин:пароль. По желанию можно указать и прокси. Обязательно прочтите памятку в окне настроек!
Советую изучить и изменить другие настройки софта.
Автоматическое распознавание капчи
Следующим шагом является автоматизация распознавания капчи. Согласитесь, какой смысл в программе, если она каждый раз требует от вас вручную вводить капчу, выдаваемую Яндексом. Так как Словоёб будет много раз отправлять запросы к Яндексу за короткий промежуток времени, капчи неизбежны.
Я пользуюсь сервисом Antigate. По желанию вы можете воспользоваться и другими программами. Slovoeb поддерживает следующие:
- Antigate
- CaptchaBot
- RIPCaptcha
- ruCaptcha
- SocialLink
О многих из них я прежде никогда не слышал.
В случае с Антигейтом есть нюанс: они переехали на новый сайт (хотя старый всё ещё доступен). Они используют общую базу, поэтому на обоих сайтах единый аккаунт. На каком регистрироваться — решать вам. Первый более классический, спартанский, более привычный для веб-мастеров со стажем. Второй же более современный.
Классический Антигейт — antigate.com, новый Антигейт — anti-captcha.com.
Учтите, что Antigate платный. Но недорогой. Мне хватает 1 доллара на 2 месяца работы (а то и больше).
Перейдите на страницу настроек антикапчи, щёлкнув по вкладке в левой части окна настроек.
В поле Antigate Key введите ваш ключ антикапчи. Получить его можно в настройках профиля Antigate.
На этом базовая настройка Словоёба завершена.
Рекомендую посмотреть и другие вкладки настроек. Возможно, вам захочется что-то настроить под себя.
Как работать с программой Словоёб?
Сервис для составления семантического ядра Словоёб. Первое, для чего мы скачали данную программу — быстрее собрать семантическое ядро. Для этого в нем есть все те же функции, что и в Яндекс.Wordstat. Это сбор по левой колонке, по правой колонке Wordstat («что еще искали…»), сбор частотностей. Но сейчас вы сможете собрать весь необходимый пакет ключевых слов щелчком одной кнопки. Для этого, правда, вам все же нужно пройти первый этап сбора собственными усилиями. Т.е. составить список из нескольких самых значимых фраз, которые описывают страницу вашего сайта. Например, для моего текста подойдут запросы «словоеб» и «поиск ключевых слов».
Нажимаем красную кнопку «Пакетный сбор фраз по левой колонке Yandex.Wordstat» и вписываем туда эти слова. Нажимаем кнопку «Начать сбор» и Словоёб приступает к работе.
Внизу в окне программы есть вкладка «Журнал событий», где вы сможете следить за процессом: нет ли ошибок и прочее. Когда сбор закончен, вы можете его продолжить по правой колонке, если вам показалось, что найденных слов мало.
Кроме того, есть еще и функция сбора поисковых подсказок . Именно тех, которые Google и Яндекс предлагают при вводе слов в строку поиска. Зачастую предложенные ими варианты могут быть очень удачными. Я чаще собираю семантическое ядро именно так.
После того, как вы завершили сбор фраз, можете приступать к сбору частотностей, вида «!» (для точного вхождения ключа) или «» (для вхождения по всем его словоформам).
Отсеять лишние фразы вы можете перед сбором частотностей, либо после. В зависимости о того, как много у вас получилось запросов. Чтобы упростить отбор ключей, можно воспользоваться фильтром «Стоп-слова». Например, у меня лишними будут запросы, в которых есть слово «скачать». Я его вношу в фильтр и нажимаю «Отметить фразы в таблице». Как видите, эти фразы отмечены галочкой в таблице сбора. И я их просто удаляю.
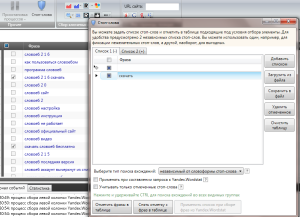
Когда вы отсеяли всё лишнее и собрали всю необходимую информацию, выгружайте ваш файл в Excel (вверху слева есть зеленая иконка «Экспортировать данные») и работайте с ними в удобном формате. Вот так легко программа для составления семантического ядра справляется со своей задачей.
Подбор ключевых слов с помощью Словоёб
Пора приступить непосредственно к подбору запросов. Для этого нужно создать новый проект. Все его данные сохранятся в файл. Таких файлов может быть неограниченное количество, так что вы легко сможете переключаться между проектами.
Нажмите на кнопку «Создать проект»:
В открывшемся окне выберите, куда сохранить файл и как его назвать. Я обычно называю файлы по имени сайта и сохраняю в папку проекта (там, где лежат все остальные данные по нему). Кто-то держит все файлы Словоёба в единой папке. Кому как удобнее.
Следующий шаг после создания проекта — настройка региона. Если ваш сайт ориентирован только на определённый регион (или регионы), вам нужна статистика поисковых запросов именно по нему, а не по всему миру. Нажмите на кнопку выбора региона и установите нужные вам галочки.
Здесь всё так же, как в интерфейсе Вордстата:
Настало время подбора ключевых слов!
Для начала подбора запросов кликните по кнопке «Пакетный сбор запросов из левой колонки Yandex.Wordstat«, как показано на скриншоте.
В открывшемся окне введите ключевые слова, на основе которых вы хотите подобрать запросы. Всё точно так же, как в интерфейсе Вордстата. Главное отличие — в программе вы можете ввести сразу несколько слов, и программа будет работать с ними по очереди, а в Вордстате нужно работать с каждым словом по очереди, вручную, что значительно увеличивает время работы.
Нажмите на кнопку «Начать сбор«. Ура, теперь можно пойти сделать кофе или переключиться на другие задачи. Словоёбу понадобится время, чтобы собрать запросы.
Стоп-слова
После того как программа отпарсила ключевые слова, необходимо отфильтровать их, отбросив не интересующие нас сочетания и формулировки. Это можно сделать с помощью стоп-слов. Нажмите на большую кнопку «Стоп-слова» с изображением щита. В открывшемся окне кликните по кнопке «Добавить списком«. В ещё одном открывшемся окне перечислите стоп-слова (каждое с новой строчки), которых не должно быть в вашем поисковом запросе. Например, нас не интересуют запросы со словами «скачать», «торрент», «новая версия», «последняя версия» и т. д., так как мы распространяем не саму программу, а только её описание.
После введения стоп-слов нажмите на кнопку «Отметить фразы в таблице» в левом нижнем углу окна стоп-слов.
Далее кликните по вкладке «Данные» и затем по кнопке «Удалить отмеченные фразы«.
Далее рекомендую пробежаться по оставшимся результатам и вручную убрать ненужные и бредовые запросы, так как очень сложно учесть в стоп-словах все возможные варианты.
Работа с частотностью в Словоёб
Остался один нюанс: частотность запросов, отображаемая в колонке, — это базовая частотность, то есть фраза со всеми словоформами. Чтобы определить частотности с помощью операторов, кликните по кнопке с изображением лупы и выберите пункт «Собрать частотности вида » » «.
Когда программа закончит проверять частотности, отсортируйте ключевые слова по колонке «Частотность » « » и избавьтесь от нулёвок и прочих микрочастотных запросов.
Словоеб: настройка
Наиболее распространенное назначение Словоёба – это упрощенный поиск ключевых слов. Вместо того чтобы вручную искать «ключи» в Яндекс.Wordstat, сделаем это автоматически.
Для начала нужно скачать последнюю версию программы Словоёб по этой ссылочке — seom.info/new/SlovoEB . Это блог от создателей Словоёба и его расширенной версии — Key Collector.
Распаковываем архив, запускаем файл Slovoeb.exe. Появляется окошко, в котором выбираем функцию «Создать новый проект».
Перед тем, как приступить к работе, нужно внести некоторые корректировки в настройках. Открываем в Словоёбе Настройки, выбираем вкладку «Парсинг» — «Yandex.Direct». Здесь вводим свой логин и пароль в Яндекс (т.е. нужно там для начала зарегистрироваться).
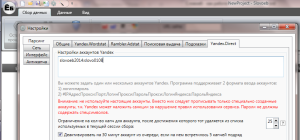
Обратите внимание на красный текст: нужно завести новый ящик на яндексе специально для парсинга, потому что его в любой момент могут забанить. В данном случае, как показано в примере на картинке, мой логин – slovoeb2014, пароль – slovo0108
Без ввода этих данных программа работать не будет.
Еще один важный момент в настройках, это параметр «Задержка между запросами» (см. скриншот).
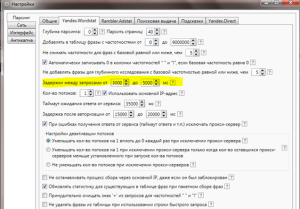
По умолчанию после установки в этой графе в закладке Yandex.Wordstat стоит значение от 5000 до 15000 мс. Это много, программа будет медленно собирать данные с Wordstat. Лучше поставить значение 3000—5000 мс. Может произойти так, что появится ошибка в программе Словоёб: «аккаунт вычеркнут из списка». Возможно, Яндекс заподозрил вас в автоматическом сборе информации. Если это случится, попробуйте увеличить интервал между запросами. У меня с приведенными значениями пока проблем не возникало.
В остальные настройки вы можете вносить свои корректировки в зависимости от потребностей проекта. Например, глубина парсинга – это количество страниц с запросами, которые выдает Яндекс.Wordstat для той, или иной фразы. Можете уменьшить его значение, чтобы сократить количество пустых запросов.
Словоеб: настройка
Наиболее распространенное назначение Словоёба – это упрощенный поиск ключевых слов. Вместо того чтобы вручную искать «ключи» в Яндекс.Wordstat, сделаем это автоматически.
Для начала нужно скачать последнюю версию программы Словоёб по этой ссылочке — seom.info/new/SlovoEB. Это блог от создателей Словоёба и его расширенной версии — Key Collector.
Распаковываем архив, запускаем файл Slovoeb.exe. Появляется окошко, в котором выбираем функцию «Создать новый проект».
Перед тем, как приступить к работе, нужно внести некоторые корректировки в настройках. Открываем в Словоёбе Настройки, выбираем вкладку «Парсинг» — «Yandex.Direct». Здесь вводим свой логин и пароль в Яндекс (т.е. нужно там для начала зарегистрироваться).
Обратите внимание на красный текст: нужно завести новый ящик на яндексе специально для парсинга, потому что его в любой момент могут забанить. В данном случае, как показано в примере на картинке, мой логин – slovoeb2014, пароль – slovo0108
Без ввода этих данных программа работать не будет.
Еще один важный момент в настройках, это параметр «Задержка между запросами» (см. скриншот).
По умолчанию после установки в этой графе в закладке Yandex.Wordstat стоит значение от 5000 до 15000 мс. Это много, программа будет медленно собирать данные с Wordstat. Лучше поставить значение 3000—5000 мс. Может произойти так, что появится ошибка в программе Словоёб: «аккаунт вычеркнут из списка». Возможно, Яндекс заподозрил вас в автоматическом сборе информации. Если это случится, попробуйте увеличить интервал между запросами. У меня с приведенными значениями пока проблем не возникало.
В остальные настройки вы можете вносить свои корректировки в зависимости от потребностей проекта. Например, глубина парсинга – это количество страниц с запросами, которые выдает Яндекс.Wordstat для той, или иной фразы. Можете уменьшить его значение, чтобы сократить количество пустых запросов.
Приступаем к работе
Приступаем к подбору запросов.
Новый проект
Начинаем работу с создания нового проекта. Их может быть несколько — каждый сохраняется в отдельном файле. Есть возможность переключаться между ними.
По умолчанию проекты сохраняются в папку с программой.
Следующим шагом будет настройка региона. При ориентировании на какой-то определённый из них понадобится статистика именно по нему. Выбор его устанавливается галочкой в нужном месте:
Установите региональные настройки
Собираем запросы
Вызываем пакетный сбор в соответствии с картинкой:
Перейдите в меню сбора запросов
В открывшемся диалоге вводятся ключевые слова для подбора запросов.
По нажатию «Начать сбор» приложение начнёт их собирать.
После парсинга нужно отфильтровать запросы от не интересующих нас сочетаний и формулировок.
Это делается стоп-словами. По нажатию кнопки «Стоп-слова» нужно потом выбрать «Добавить списком». В следующем открывшемся диалоге нужно перечислить (каждое с новой строки) те, которые не хотите видеть в своём поисковом запросе.
Например, если не интересуют слова «скачать», «торрент», «новая версия», «последняя версия», так как распространение программы постановщиком задачи не происходит, то это будет выглядеть так:
Здесь можно исключить те слова и выражения, которые нас не интересуют
После введения стоп-слов нужно активировать кнопку «Отметить … в таблице» внизу слева этого же окна.
Переместившись на вкладку «Данные» «Удаляем отмеченные фразы».
После этого нужно ещё вручную почистить кривые запросы, не учтённые в стоп-словах.
Проработка частотности
Для сбора информации по частотности запросов с помощью операторов нужно нажать кнопку с изображением лупы и выбрать команду «Собрать частотности вида * *.
После программной проверки слова сортируются по колонке «Частотность * *», удаляются нулевые и микрочастотные.
И уже после этого будет получено семантическое ядро.
Его можно экспортировать в Excel (по кнопке вверху слева), можно сохранить в группу (справа — работа с группами).
Надеемся, что наша пошаговая инструкция оказала вам помощь в правильном подборе слов-ключей.
Оставляйте свои комментарии и делитесь новыми знаниями со своими друзьями.
Цели и задачи новой программы Slovoeb
Создатель софта и ее предназначение
Словоеб (по английски slovoeb) — уникальный seo-инструмент для эффективного сбора и анализа поисковых фраз, не требующий материальных вложений со стороны веб-мастера (бесплатен). Он является младшим братом профессиональной программы по сбору семантического ядра Key Collector, с идентичным интерфейсом и базовым набором парсинга. Парсинг — это процесс сбора поисковых запросов из различных источников (статистика поисковых систем, анализ конкурентов, данные по веб аналитике и т.д.). Словоеб использует для своего парсинга статистику Яндекса — WordStat и данные системы LiveInternet.
Программу slovoeb придумал известный индивидуальный предприниматель и специалист Александр Люстик, автор блога seom.info. Он хотел найти эффективный способ обработки и анализа поисковых запросов. Ориентация конечно была сделана в первую очередь для платной Key Collector, но все базовые функции для хорошего сбора семантики прекрасно реализованы и в бесплатном аналоге.
Люстик, автор блога seom.info. Он хотел найти эффективный способ обработки и анализа поисковых запросов. Ориентация конечно была сделана в первую очередь для платной Key Collector, но все базовые функции для хорошего сбора семантики прекрасно реализованы и в бесплатном аналоге.
Как бесплатно скачать программу Словоеб
Последнюю версию Словоеба от 21 октября 2013 года можно скачать здесь. Для ее работы обязательным условием является наличие дополнительного расширения — Microsoft .NET Framework 4.0 Full.
Итак, что же умеет делать Словоеб, чем он будет полезен блоггеру для продвижения его блога в поисковых системах.
Основные инструменты программы slovoeb
- Парсинг сервиса Вордстат поисковика Яндекс. Словоеб умеет собирать все поисковые фразы, которые предоставляет статистика WordStat на каждый запрос своего посетителя. Сбор идет как из основной левой колонки сервиса, так и с правой. Никаких ограничений не существует — пользователь программы видит то же самое, что и любой веб-мастер, использующий статистику Яндекса вручную.
- Статистика сервиса Ливинтернет. Slovoeb предоставляет своему пользователю подробную раскладку по популярности поисковых запросов, которые он может использовать для сбора семантического ядра.
- Определение конкурентности запроса. Словоеб может показать пользователю число сайтов в сети Интернет (которые находятся в индексе поисковой системы Яндекс и Гугл) по заданному запросу. На основе этих данных можно приблизительно оценить конкуренцию (но только приблизительно!).
- Определение целевой страницы в Яндексе и Гугле. Софт определяет для каждого запроса самую релевантную страницу, которая находится на блоге или сайте веб-мастера. Критично для выполнения правильной внутренней перелинковки веб-ресурса.
Как парсить ключевые запросы в СловоЁБ
После того, как мы подобрали основные ключевые запросы, которые будем парсить (их можно сохранить для дальнейшей обработки в программе Excel, или подобной), переходим к работе с программой парсером.
После первого запуска необходимо провести минимальные настройки для дальнейшей работы с программой. Первое, это ввести логин и пароль от имеющегося аккаунта Яндекс в формате «мойлогин:мойпароль». Я рекомендую для работы с Словоёбом использовать отдельно созданную учетную запись, чтоб не потярять наработки. если вдруг аккаунт будет по каким то причинам заблокирован. Для ввода логина и пароля жмем значок шестеренки в верхней пали программы и в открывшемся окне выбираем вкладку «Yandex.Direct»:
Далее переходим на вкладку «Yandex.Wordstat», и выставляем значение «глубина парсинга» равное двум.
После чего сохраняем настройки. Все программа готова к работе. Теперь создаем новый проект, нажав кнопку «Создать новый проект» и сохраняем его в удобном для нас месте.
В открывшемся окне проекта переименовываем название Группы по умолчанию в ключевое слово, которое собираемся парсить и жмем кнопку «Пакетный сбор слов из левой колонки….», для начала процедуры парсинга.
В следующем окне вводим ключевое слово, которое мы хотим найти в разных сочетаниях и жмем кнопку «Начать сбор».
Если появится окно с капчей, то вводим соответствующие символы и запускаем поиск.
Вот и все. Сбор слов начался. Вы можете ждать, пока программа соберет все вариации и остановится сама, или остановить поиск вручную, если данные в колонке «Частотность» напротив найденных слов будут составлять менее цифры 7.
Затем можно скопировать найденные слова кликнув правой кнопкой мышки по колонке «Фраза» и выбрав в выпадающем меню пункт «Скопировать колонку в буфер обмена».
Далее найденные слова можно вставить в Excel файл и продолжить там работу по сортировке этих слов, очистки от не нужных приложений и не подходящих ключевых фраз.
Минус-слова Словоеба
Теперь мы поговорим о таком термине, как «минус-слова» (стоп-слова) и о том, как работать с ними в Словоебе.
Минус-слова (стоп-слова) – это слова, которые нам не нужны. Их используют для упрощения работы со списком ключевых фраз, которые соберет Словоеб.
Например: если у вас информационный сайт, и вы ничего не продаете, вам не нужны ключевые фразы со словом «купить»; если у вас сайт по предоставлению услуг в Москве, то вам не нужны ключевые слова, которые содержат другие города.
Чтобы добавить стоп-слова в Словоеб, нужно:
- Нажать на соответствующую кнопку на панели задач.
- Добавить слова.
- Закрыть окно.
Теперь «Словоеб» не будет добавлять в таблицу фразы, в которых встречаются отмеченные слова.
Стоп-слова можно добавлять пакетно (файлом) или сохранять, что в свою очередь бывает весьма необходимо.
В случае если вы уже собрали все нужные вам фразы, но стоп-слова сразу не прописали – не беда, сделайте следующее:
- Внесите необходимые стоп-слова.
- Нажмите кнопку «Отметить фразы во всех таблицах».
Теперь все фразы в таблицах, в которых присутствуют стоп-слова, отмечены галочками.
Закрываем окно стоп-слов и возвращаемся к нашему списку фраз.
Разархивировать скаченный архив.
Теперь у вас есть последняя версия Словоеба. Старую версию можно удалить, только не забудьте перенести настройки со старой версии программы на новую.
Советы для грамотного составления семантического ядра
Резюмируя статью, мы выделили пять практических рекомендаций для сбора семантического ядра. Они помогут интернет-маркетологам и владельцам бизнеса получить качественную семантику и эффективно использовать ее для продвижения проекта.
Работайте вместе
Сбор семантического ядра — это совместная работа заказчика и SEO специалиста. Заказчик хорошо понимает цели бизнеса, владеет терминологией, знает сценарии поведения аудитории и может описать потребности пользователя. Исполнитель разбирается в специфике поиска, учитывает информационную или коммерческую основу запроса и берет на себя весь пласт технической работы. При таком подходе семантика получается полной, коммерчески значимой и на сайт идет не просто целевой, а конвертируемый трафик.
Соберите синонимы
Синонимы расширяют семантику вспомогательными ключами. Они приводят на сайт дополнительный трафик и охватывают альтернативные сегменты целевой аудитории. Например, «садовый центр» могут искать как «садовый питомник», а «многолетники для тени» как «теневыносливые растения». Для сбора синонимов, альтернативных фраз и LSI ключей используйте поисковые подсказки, правую колонку «Яндекс.Вордстат» и раздел «Похожие фразы» в Serpstat. Хорошие результаты дает анализ сниппетов в поисковой выдаче по нужному запросу. Также у конкурентов можно подсмотреть синонимичные заголовки, подзаголовки и alt иллюстраций для своих маркерных запросов.
Чистите без пощады
На стадии сбора и расширения семантики попадается большое количество запросов, не совсем подходящих под тематику проекта. На первый взгляд они могут соответствовать теме, но приведут на сайт нецелевой трафик. Как «растения ботанического сада» на этом скрине.
Запросы, не подходящие под тематику и цели проекта
Функция фильтрации и удаления неподходящих фраз есть у большинства сервисов по сбору и кластеризации семантического ядра. Но даже по автоматически очищенному списку лучше дополнительно пройтись вручную — так получится убрать запросы не только с ненужными словами, но и с неподходящим интентом. Помните, что семантика без «мусора» — это чистый трафик, хороший охват рекламной кампании и релевантные запросам объявления.
Не отбрасывайте высокочастотные и низкочастотные запросы
Не отказывайтесь от дорогих в продвижении ВЧ и не очень щедрых на трафик НЧ запросов. Без высокочастотных ключей не получится разработать удобную структуру сайта и составить контент-план. Без НЧ запросов вы недополучите конверсионный трафик. Чтобы не тратить лишнего на продвижение высокочастотных фраз, начинайте оптимизацию с низкочастотных. С ними проще выйти в ТОП выдачи и получить первых «теплых» и «горячих» клиентов. Со временем сайт нарастит траст, улучшит коммерческие факторы ранжирования и вверх пойдут перегретые ключи из высоконкурентного списка.
SEO для маркетинга, а не наоборот
Разработка семантического ядра исключительно ради трафика принесет трафик, но не сделки
Чтобы получить трафик, который конвертируется в деньги, при сборе семантики нужно «плясать» от задач маркетинга: увеличить продажи или сократить стоимость лида, привлечь внимание к товару на несформированном рынке или обойти конкурентов в регионах. Для этого приходится углубляться в отраслевую специфику, отсматривать интенты, определять их коммерческую значимость и оценивать товарные категории с точки зрения маржинальности
Работы больше и процесс не быстрый, зато бизнес получает фундаментальное основание для старта в онлайне и перспективную базу для дальнейшего развития сайта.







